



Shallow-π implementation
Shallow-π의 공식 구현체를 이용해서 π0를 distill한 버전인 Shallow-π를 구현했다.
이전의 distillation과 비교되는 Shallow-π의 대략적인 컨셉은 다음 사진과 같다:
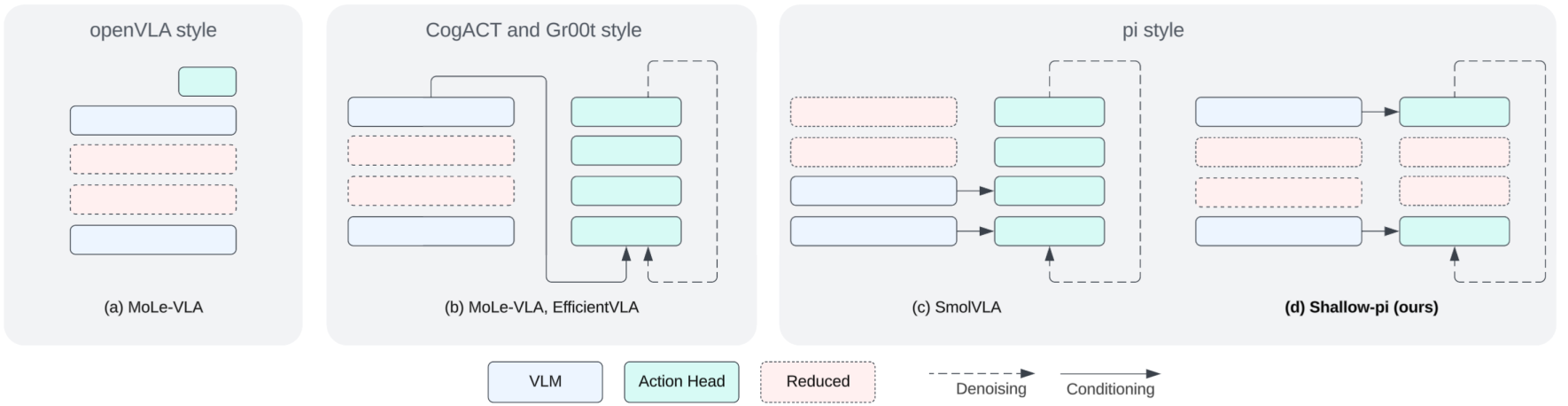 Figure source: Shallow-π: Knowledge Distillation for Flow-based VLAs.
Figure source: Shallow-π: Knowledge Distillation for Flow-based VLAs.
GPU VRAM을 효율적으로 사용하기 위해서 BF16 데이터 타입을 사용했고, 하나의 GPU에 batch size가 64까지 올라가는 것을 확인하여 5개의 GPU로 batch size 320으로 distillation을 진행했다(총 30,000 step). Distillation 동안 수집한 metric 정보는 다음과 같다(다른 연구실 인원들과 같이 쓰는 서버이기 때문에, 학습 도중에 다른 workload들이 생겼다가 없어졌다가 했을 것이다):
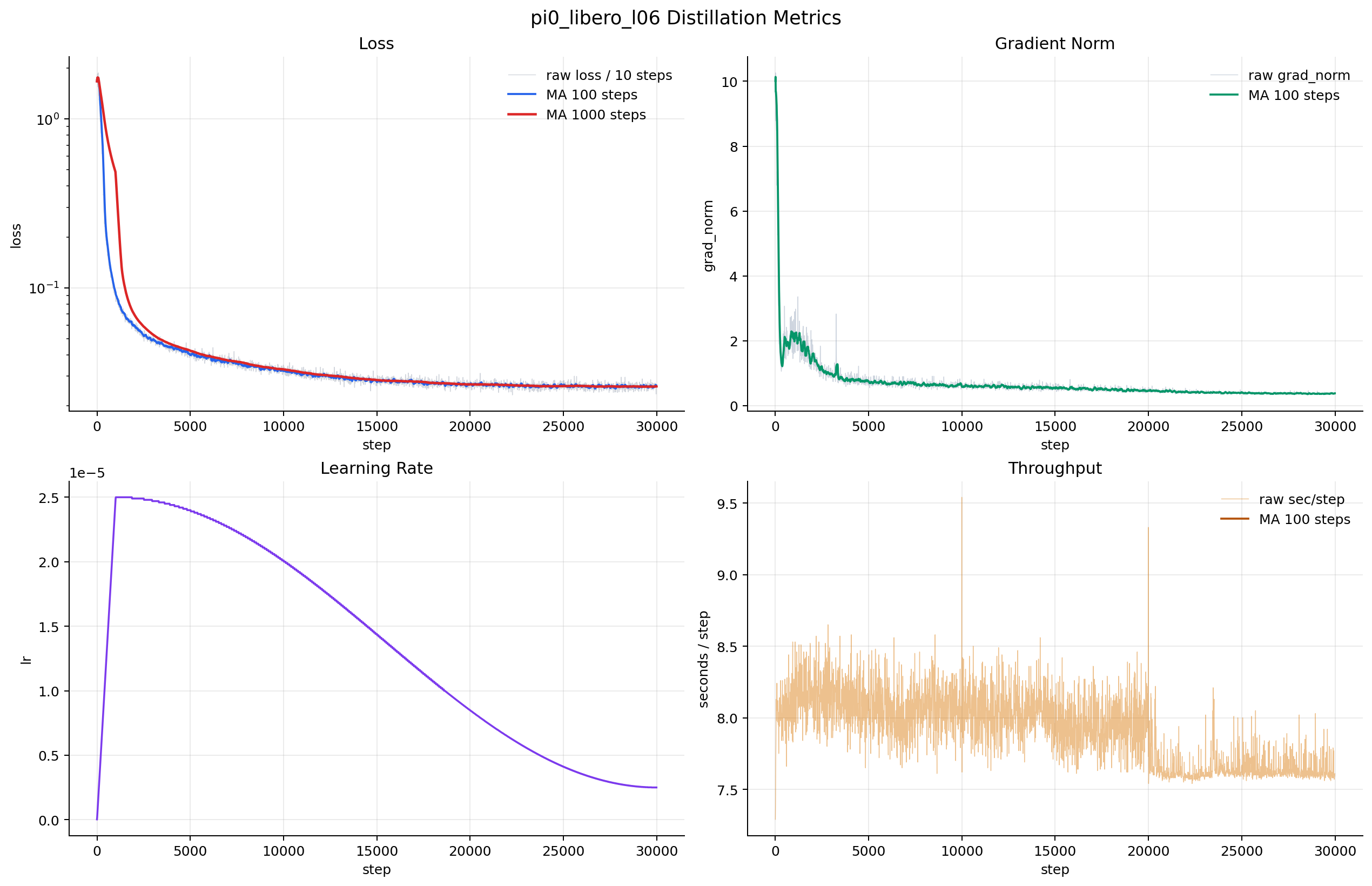 pi0_libero_l06 → pi0_libero teacher를 distillation해서 만든 Gemma depth 6짜리 shallow student
pi0_libero_l06 → pi0_libero teacher를 distillation해서 만든 Gemma depth 6짜리 shallow student
제대로 distillation이 되었는지 확인하기 위해, 학습이 완료된 30k-step checkpoint를 사용해 libero_spatial, libero_object, libero_goal, libero_10 총 4개의 LIBERO task suite에서 평가를 진행했다. Success rate는 아래와 같다:
| Task Suite | Episodes | Success Rate |
|---|---|---|
| libero_spatial | 500 | 89.4% |
| libero_object | 500 | 88.8% |
| libero_goal | 500 | 81.8% |
| libero_10 | 500 | 45.6% |
| Average | 2,000 | 76.4% |
Comments