



DEFLECT: Delay-Robust Execution via Flow-matching Likelihood-Estimated Counterfactual Tuning for VLA Policies
이 논문이 집중하는 현대 VLA 모델들의 문제는 prediction-execution misalignment이다. 특정 시점 $t$에서 observation을 받아서 inference를 수행하고 나면, 그 결과 action은 $t$가 아니라 그로부터 시간이 지났을 때 execute될 수 있다. 모델 크기가 점점 커질수록 inference는 보통 느려질 것이고, robot control rate가 빠르다는 점을 고려했을 때 이는 정상적인 제어를 불가능하게 만든다. 따라서 실제 deployment에서는 보통 아래와 같은 asynchronous inference를 사용한다:
- 현재 observation을 받아서 VLA가 다음 action chunk를 계산하기 시작한다.
- VLA가 계산하는 동안 robot은 이전에 계산된 action chunk를 계속 실행한다.
- VLA 계산이 끝나면 새 chunk를 받아서 실행한다.
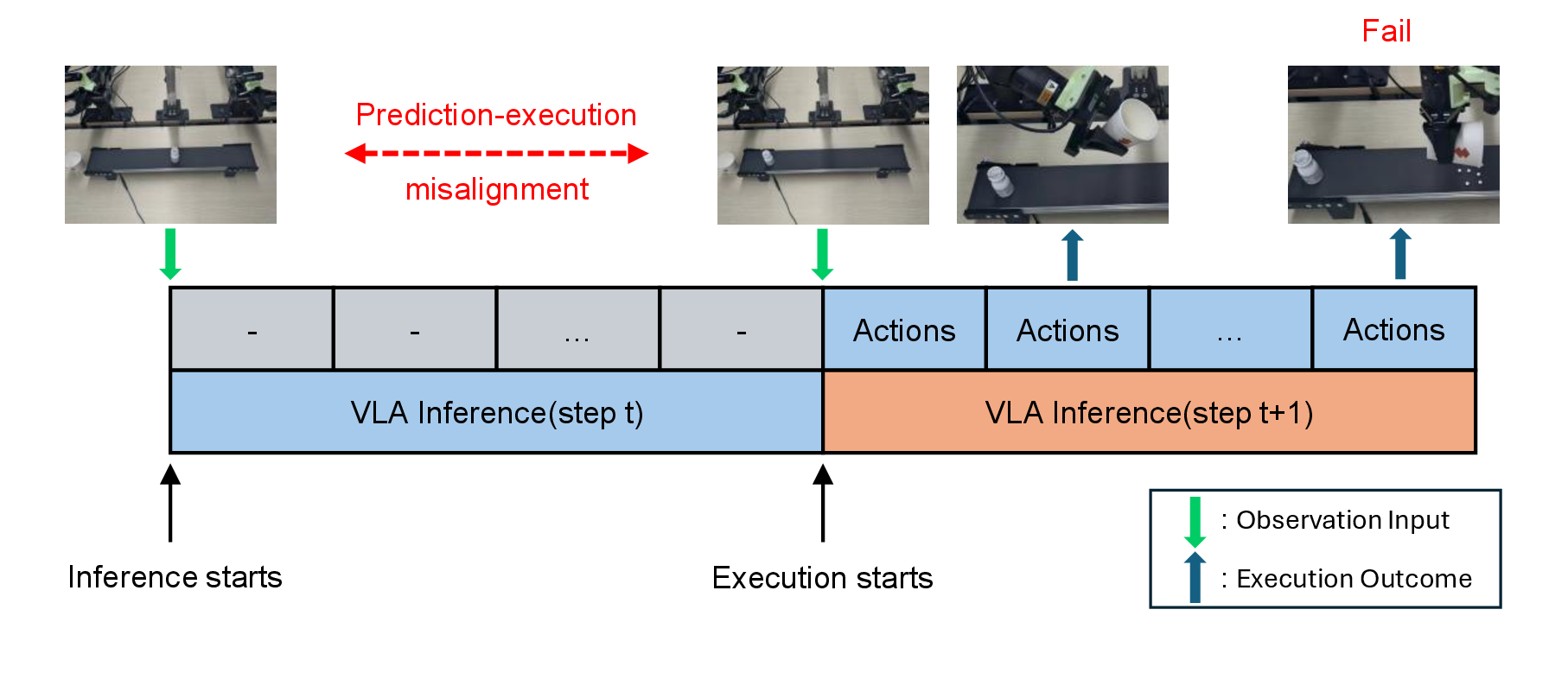 Problem Example
Problem Example
이렇게 하면 inference와 execution을 overlap할 수 있지만, VLA가 action을 예측할 때 본 observation과, 그 action이 실제 실행되는 physical state가 서로 달라지는데 이를 본 논문에서는 prediction-execution misalignment라고 부른다.
이를 해결하기 위해 DEFLECT(Delay-Robust Execution via Flow-matching Likelihood-Estimated Counterfactual Tuning)라는 알고리즘을 제안하는데, 크게 분류하자면 이는 flow-matching VLA를 offline DPO로 post-training (fine-tuning)하는 알고리즘이다. 핵심은 converting latency itself into a label-free preference signal이다. DPO에 필요한 preference data를 만들기 위해 같은 trajectory 내에서 두 가지 counterfactual condition을 만든다. 하나는 fresh condition으로 execution 시점의 최신 observation을 본 경우이고 나머지 하나는 stale condition으로 inference 시작 시점의 오래된 observation을 본 경우이다. 그리고 학습이 완료된 VLA를 두 condition에 대해서 같은 noise로 inference를 돌려서 action chunk $A^{+}$(fresh condition에서 나온 action chunk, preferred data), $A^{-}$(stale condition에서 나온 action chunk, rejected data)를 구한다.
Comments