



OxyGen: Unified KV Cache Management for VLA Inference under Multi-Task Parallelism
이 논문은 Mixture-of-Transformers(MoT) Vision-Language-Action(VLA) 모델들이 구조적으로 action과 language 같은 heterogeneous output을 지원함에도, 기존 inference system은 on-device 환경에서 efficient multi-task parallelism을 달성하지 못한다고 지적한다. 저자들은 그 주된 원인을 isolated KV cache management로 보고, 이로 인해 같은 observation과 instruction에 대한 VLM backbone prefill이 task마다 반복되고, action generation과 language decoding 사이의 resource contention이 발생한다고 설명한다.
저자들은 이를 해결하기 위해 unified KV cache management라는 inference 방식을 제안한다. 이는 KV cache를 task와 frame을 가로지르는 shared system resource로 관리해서 prefill 중복과 language decoding blocking을 줄인다.
저자들은 이 알고리즘을 $\pi_{0.5}$ 위에 구현하여 NVIDIA GeForce RTX 4090, Jetson AGX Thor에서 실험을 돌렸다. 실험 configuration은 LIBERO, DROID, ALOHA에서 가져온 observation specification과 action dimensionality를 사용했다.
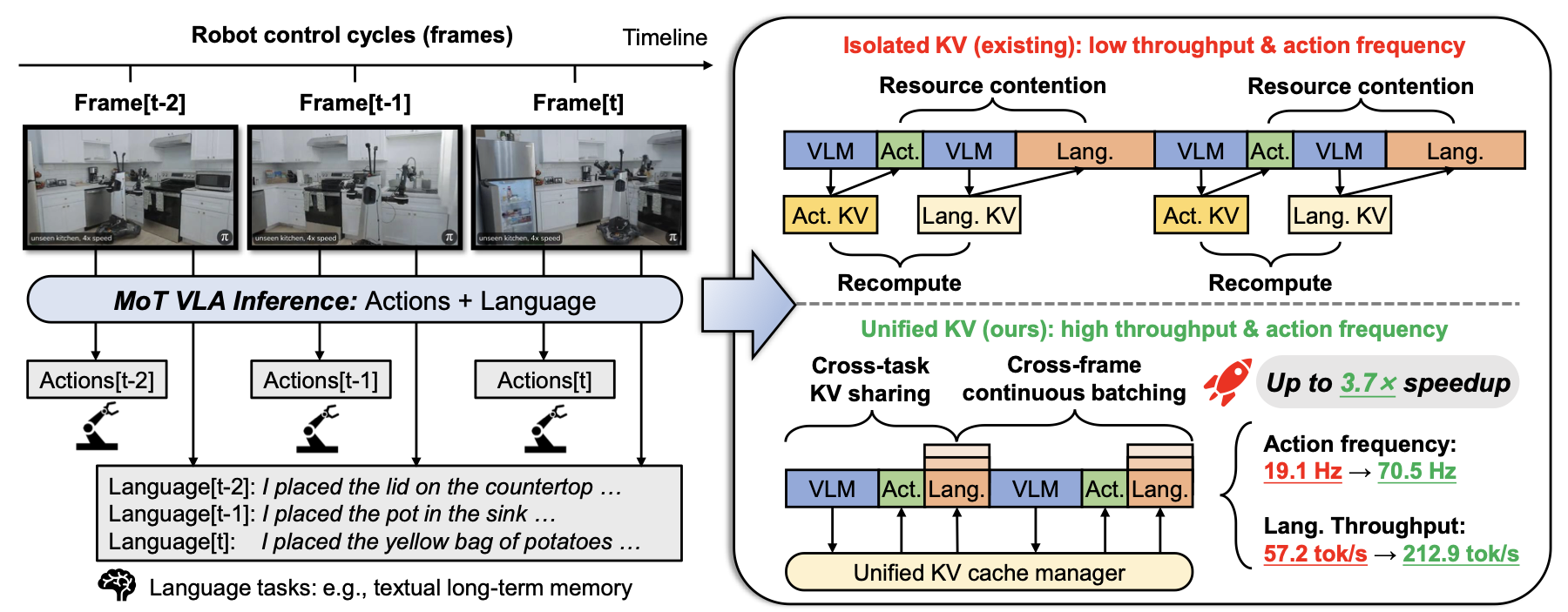 Overall Figure
Overall Figure
Method
Multi-task parallelism with asymmetric deadlines
이 논문은 MoT VLA의 핵심 on-device inference scenario를 “asymmetric deadlines를 갖는 multi-task parallelism”으로 설정한다. 즉, robot action은 매 control cycle 안에 생성되어야 하는 hard-deadline task이고, language/memory generation은 여러 frame에 걸쳐 진행 가능한 soft-deadline task이다.
Unified KV Cache Manager
OxyGen은 unified KV cache manager $\mathcal{M}$을 둔다. 이 manager는 KV cache를 task와 frame을 가로질러 관리한다.
Manager의 역할은 크게 세 가지다.
- 현재 frame의 prefill KV를 저장한다.
- action expert와 language expert가 같은 prefill KV를 각자의 방식으로 소비하게 한다.
- 이전 frame들에서 시작된 language request들을 유지하고, batch로 묶어 decoding한다.
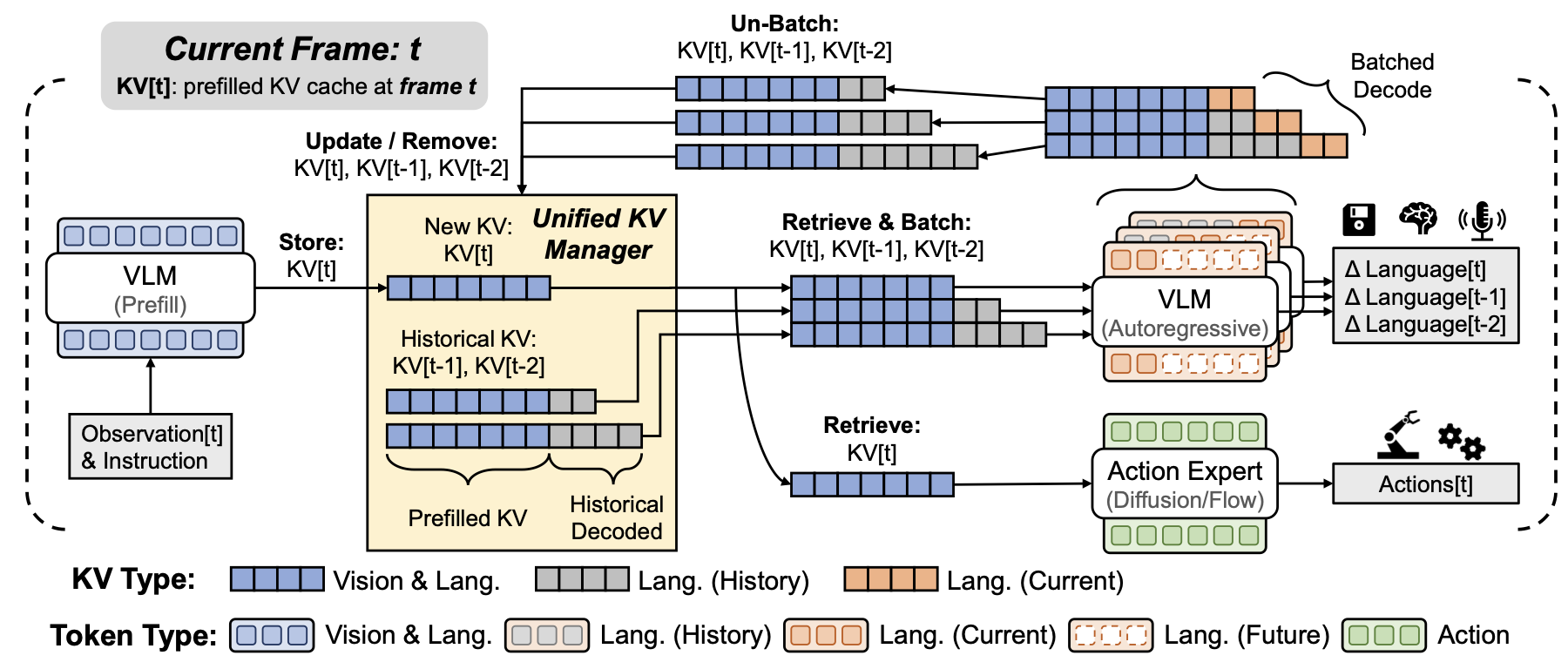 KV-centric dataflow
KV-centric dataflow
위 Figure의 dataflow를 말로 풀면 다음과 같다.
t 시점의 frame에서
1. Observation[t] + Instruction이 VLM으로 들어간다.
2. VLM prefill 결과로 KV[t]가 생성된다. (frame t의 observation과 instruction을 prefill해서 얻은 KV cache)
3. Manager가 KV[t]를 저장한다.
4. Action expert는 KV[t]를 retrieve해서 Actions[t]를 생성한다.
5. Language expert는 KV[t], KV[t-1], KV[t-2] 등 active request의 KV를 batch로 받아 decoding한다.
6. 새로 생성된 language token KV는 각 request state에 update된다.
7. 끝난 request는 remove되고, 끝나지 않은 request는 다음 frame을 위해 유지된다.
즉, manager는 단순한 cache dictionary가 아닌 robot control cycle과 language generation request를 연결하는 scheduling layer다.
1st Key Optimization: Cross-task KV Sharing
기존 방식에서는 action task와 language task가 각각 VLM prefill을 실행하는 것에 비해, OxyGen에서는 prefill을 한 번만 한다. 이렇게 하면 같은 observation을 반복해서 encode하지 않아도 된다. 특히 VLM backbone prefill은 비싼 연산이다. vision token과 language token이 함께 들어가고, 여러 transformer layer를 통과해야 하며, GPU memory bandwidth와 compute를 많이 사용하기 때문이다. 따라서 cross-task KV sharing은 다음 비용을 줄인다:
- 중복 VLM forward pass
- 중복 attention computation
- 중복 KV cache allocation
- 중복 weight memory access
- action path에 끼어드는 불필요한 latency
시스템 관점에서 보면 이는 shared computation reuse다.
2nd Key Optimization: Cross-frame Continuous Batching
Robot control에서는 매 frame마다 action을 생성해야 한다. 하지만 language generation은 보통 한 frame 안에 끝낼 필요가 없다. 예를 들어 다음과 같은 language task는 여러 frame에 걸쳐 진행되어도 된다.
- 현재 작업 상황을 textual memory로 저장
- robot trajectory를 natural language로 narrate
- long-horizon plan을 조금씩 생성
- scene change를 summary로 기록
따라서 OxyGen은 language request를 frame마다 조금씩 진행한다.
예를 들어 total $N=12$ token을 생성해야 하고, frame마다 $k=4$ token만 decode한다고 하자. 그러면 하나의 request는 3 frame에 걸쳐 완료된다. 이때 frame $t+2$ 시점에는 아래와 같이 여러 request가 동시에 active 상태일 수 있다.
Active requests at frame t:
Request from frame t-2
Request from frame t-1
Request from frame t
OxyGen은 아래와 같이 이 active request들을 batch로 묶어 language decoding한다. $\sigma_t$는 $t$ 시점에 autoregressive language generation을 하기 위해 (KV cache를 포함한) 모든 필요한 context이다.
Retrieve:
σ[t-2], σ[t-1], σ[t]
Batch:
σ_hat = Batch(σ[t-2], σ[t-1], σ[t])
Decode:
each request advances by k tokens
UnBatch:
σ'[t-2], σ'[t-1], σ'[t]
Update or Remove:
finished request → remove
unfinished request → update
이 방식의 장점은 다음과 같다:
- language decoding batch size가 커진다.
- GPU utilization이 좋아진다.
- action deadline을 침범하지 않도록 frame당 decoding budget $k$를 제한할 수 있다.
- language generation을 action control loop와 decouple할 수 있다.
Comments