



Learning Action Priors for Cross-embodiment Robot Manipulation
Pretrained VLM에 아직 motor structure를 배우지 못한 action head를 바로 붙여 joint train하는 대신, state-action trajectory만으로 flow-matching action encoder-decoder를 먼저 pretrain한 뒤 decoder initialization, decaying latent distillation, history compression을 통해 VLA에 이식하는 cross-embodiment policy training framework
Overview Figure
Summary
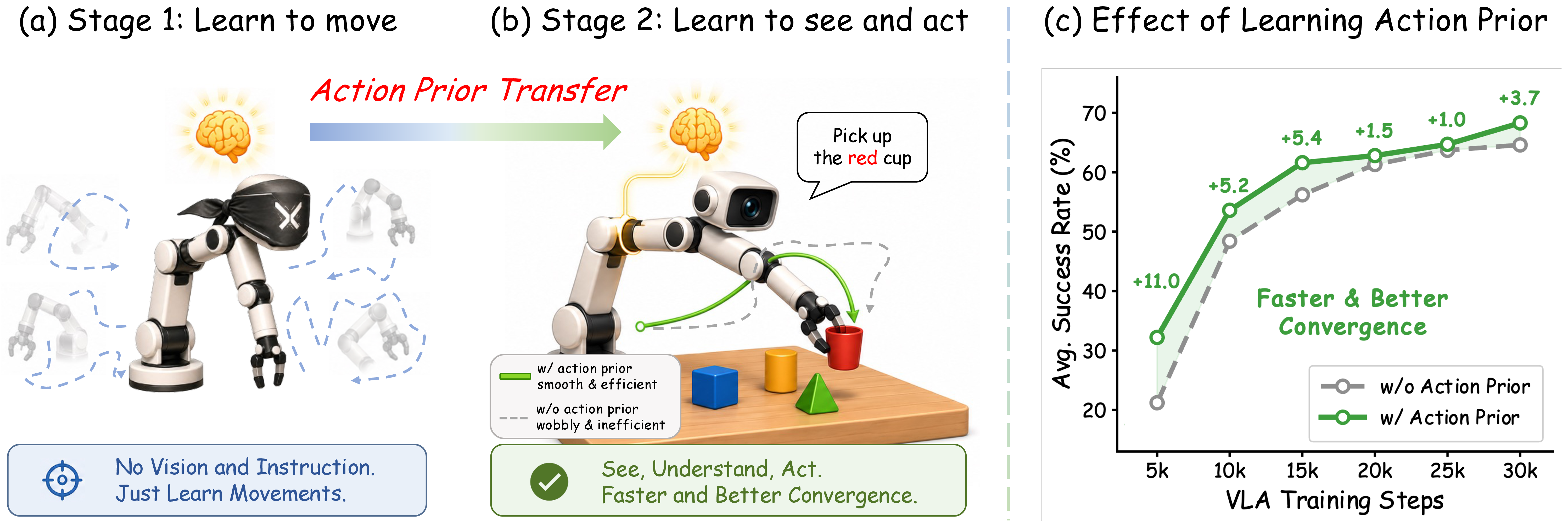
- 기존 VLA는 pretrained VLM의 visual-language prior에 비해 action module에는 대응되는 motor prior가 없어서, 초기 학습 단계에서 action distribution과 vision-language-action alignment를 동시에 배워야 한다.
- 이 논문은 heterogeneous action space를 갖는 cross-embodiment setting에서 action module을 먼저 학습시켜 VLA optimization을 안정화하고, 특히 data-scarce real-world behavior의 underfitting을 줄이려 한다.
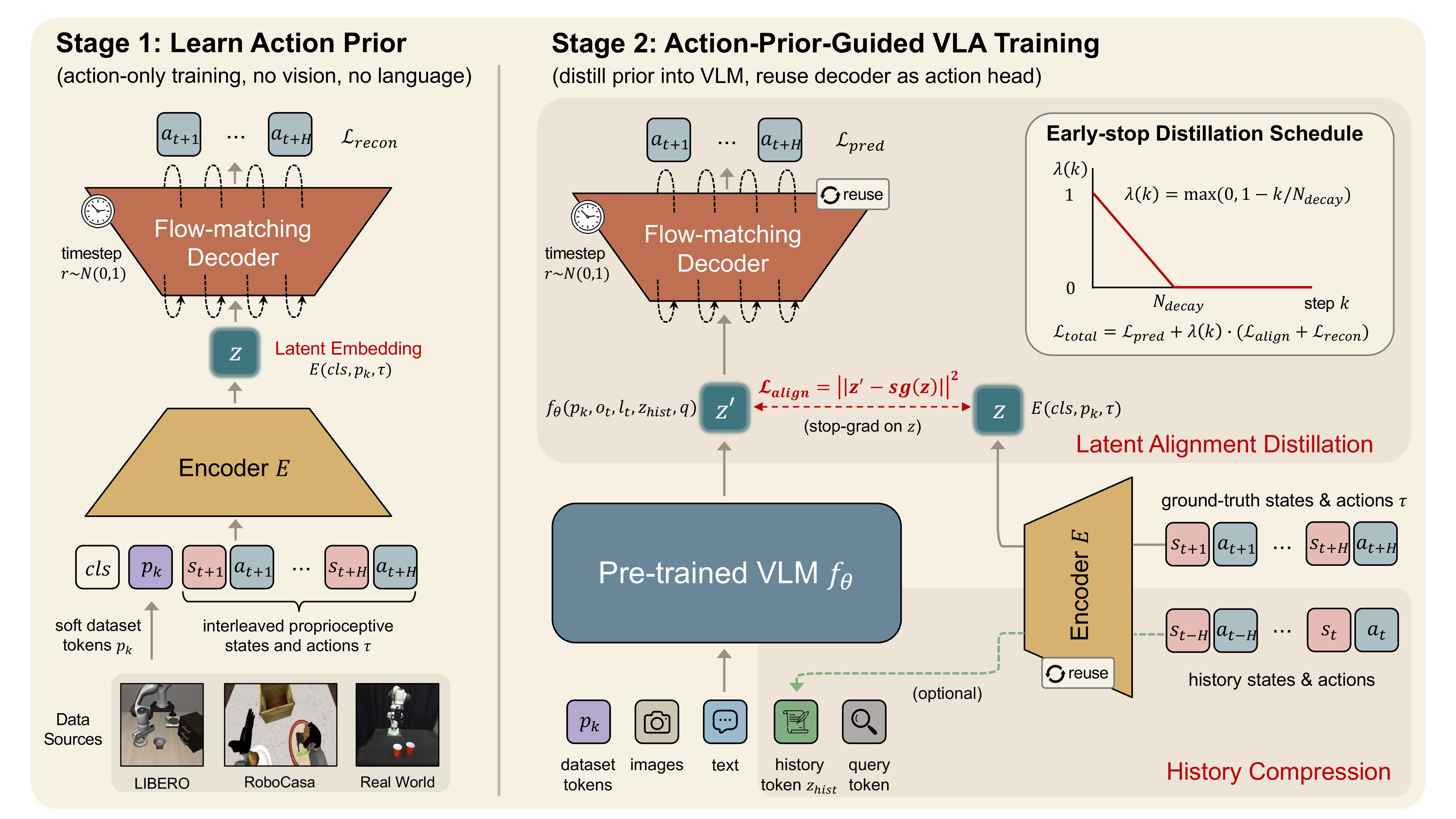
- Stage 1에서는 interleaved proprioceptive state-action sequence를 하나의 latent motion embedding $z$로 압축하고, flow-matching decoder가 $z$로부터 action chunk를 복원하도록 학습한다.
- Stage 2에서는 pretrained decoder를 VLA action head로 재사용하고, VLM이 query token으로 예측한 latent $z’$를 학습시킨다. 이때 학습 목적은 prediction loss 단독이 아니라 $\mathcal{L} = \mathcal{L}_{pred} + \lambda (k) (\mathcal{L}_{align}+\mathcal{L}_{recon})$의 세 항이다. $\mathcal{L}_{align}$은 $z’$를 encoder의 ground-truth latent $z$(stop-grad)에 맞추고, $\mathcal{L}_{recon}$은 encoder-decoder branch의 flow-matching reconstruction을 그대로 유지해 joint optimization 중에도 action latent geometry를 보존하도록 regularize한다. 두 auxiliary loss는 $\lambda(k)=\max(0,1-k/N_{decay})$에 따라 초기 5k step($N_{decay}$)에 걸쳐 0으로 선형 감쇠한 뒤 꺼진다.
- 같은 encoder를 과거 state-action history를 single token $z_{hist}$로 압축하는 history compressor로도 재사용한다. 학습 시에는 $\mathcal{L}_{total}=(\mathcal{L}(z_{hist})+\mathcal{L}(\varnothing))/2$로 history-conditioned와 history-free objective를 평균해, history token에 대한 over-reliance를 막는 일종의 token-level regularization을 건다.
- 13개 joint cross-embodiment task에서 overall success가 55.3% → 64.9% → (history) 68.0%로 올랐다. 다만 이 이득은 주로 저데이터 영역에서 나온다: simulation 평균은 64.3 → 66.5 → 68.8 (no-prior 대비 +2.2 / +4.5)로 marginal한 반면, real-world Franka 평균은 35.0 → 61.3 → 66.3 (+26.3 / +31.3)으로 dominant하다. 초기 prediction loss와 gradient norm도 각각 약 8배, 16배 감소했다.
- Stage 1의 action data를 565k → 2.3M transition(4×)으로 늘리면 더 강한 prior가 만들어지고, Stage 2의 VLA data·step·backbone·하이퍼파라미터를 전혀 바꾸지 않아도 downstream이 직접 개선된다. 동일 VLA step 기준 5k step에서 No Action Prior 21.2% → Action-State Prior 32.2% → scaled prior 35.4%이며, scaled prior의 최종 success는 68.8%다. Stage 1은 image·language token을 처리하지 않아 전체 wall-clock의 약 10%만 추가한다.
Further Analysis
- 이 논문의 핵심은 새로운 flow decoder 자체보다 training order와 latent interface이다
- 표준 VLA가 곧바로 $(o,l)\rightarrow a$를 학습한다면, 이 논문은 먼저 $\tau=(s,a,\ldots) \rightarrow z \rightarrow a$ 라는 motor representation을 만든 뒤, $(o,l,\text{history}) \rightarrow z’$를 학습한다.
- 즉, VLM이 continuous action을 처음부터 직접 이해하게 하지 않고, 이미 정리된 motor latent space를 찾아가게 한다.
- Action prior는 Bayesian 의미의 명시적 prior $p(a)$라기보다 pretrained action autoencoder/generator에 가깝다
- Stage 1 decoder는 dataset token만으로 action을 생성하지 않고, 같은 trajectory로부터 encoder가 만든 latent $z$를 받는다. 따라서 더 정확한 표현은 pretrained action manifold와 decoder initialization이다.
- 논문의 “action-only” 표현은 주의해서 읽어야 한다
- Full method의 Stage 1 encoder는 action뿐 아니라 proprioceptive state도 입력받는다. Table IV에서도 action-only prior의 simulation gain은 +0.8점인 반면, state를 함께 넣으면 +3.7점이다.
- 따라서 실제 강한 방법은
Action-State Prior이며, “vision-language-free trajectory pretraining”이라고 부르는 편이 정확하다.
- History compression은 단순한 부가 기능이 아니라 partial observability 문제를 다루는 장치다
- 현재 image만으로는 로봇이 아직 접근 중인지, 정렬을 마쳤는지, grasp를 실행해야 하는지 구분하기 어렵다.
- 과거 motion을 한 token으로 압축하면 VLM이 현재 phase를 추정할 수 있다.
- 가장 큰 claim gap은 cross-embodiment generalization이다
- 여러 embodiment를 함께 학습한 것은 맞지만, 학습에서 보지 못한 unseen embodiment로의 transfer는 평가하지 않았다.
- 따라서 검증된 것은 multi-embodiment joint fitting이지, zero-shot embodiment generalization은 아니다.