



Retrieve, Don’t Retrain: Extending Vision-Language-Action Models to New Tasks at Test Time
VLA/WAM policy를 새 task마다 다시 fine-tuning하지 않고, 저비용 pool embodiment demonstration을 retrieval pool에 추가한 뒤 frozen policy가 매 control step마다 retrieved trajectory를 조건으로 action chunk를 생성하게 만든 test-time task adaptation method
Overview Figure
Summary
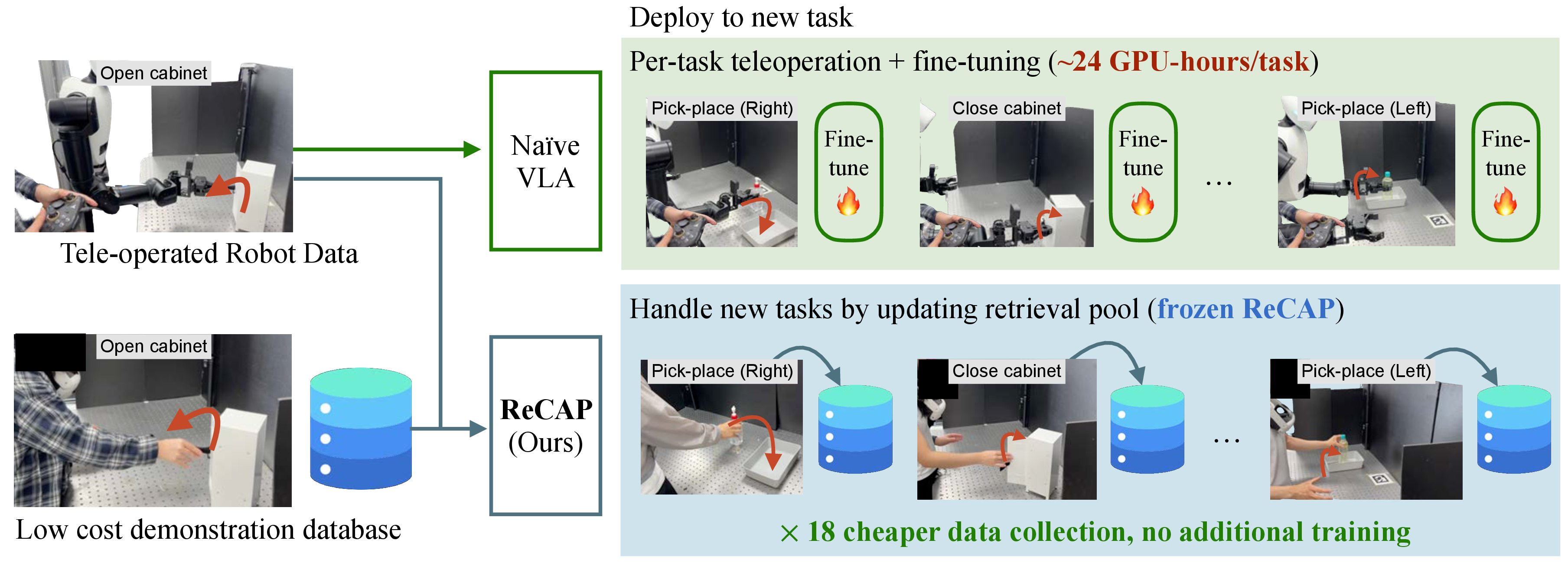
- 기존 VLA / robot foundation model은 새로운 task를 target robot에서 수행하려면 task-specific teleoperation data와 per-task fine-tuning이 필요해 data collection과 compute cost가 task 수에 비례해 증가한다.
- 이 논문은 target-side per-task adaptation을 없애고, 더 싸게 수집 가능한 pool embodiment 예시, 예를 들어 human-hand / 다른 robot trajectory를 retrieval memory에 추가하는 것만으로 새 task를 absorb 한다.
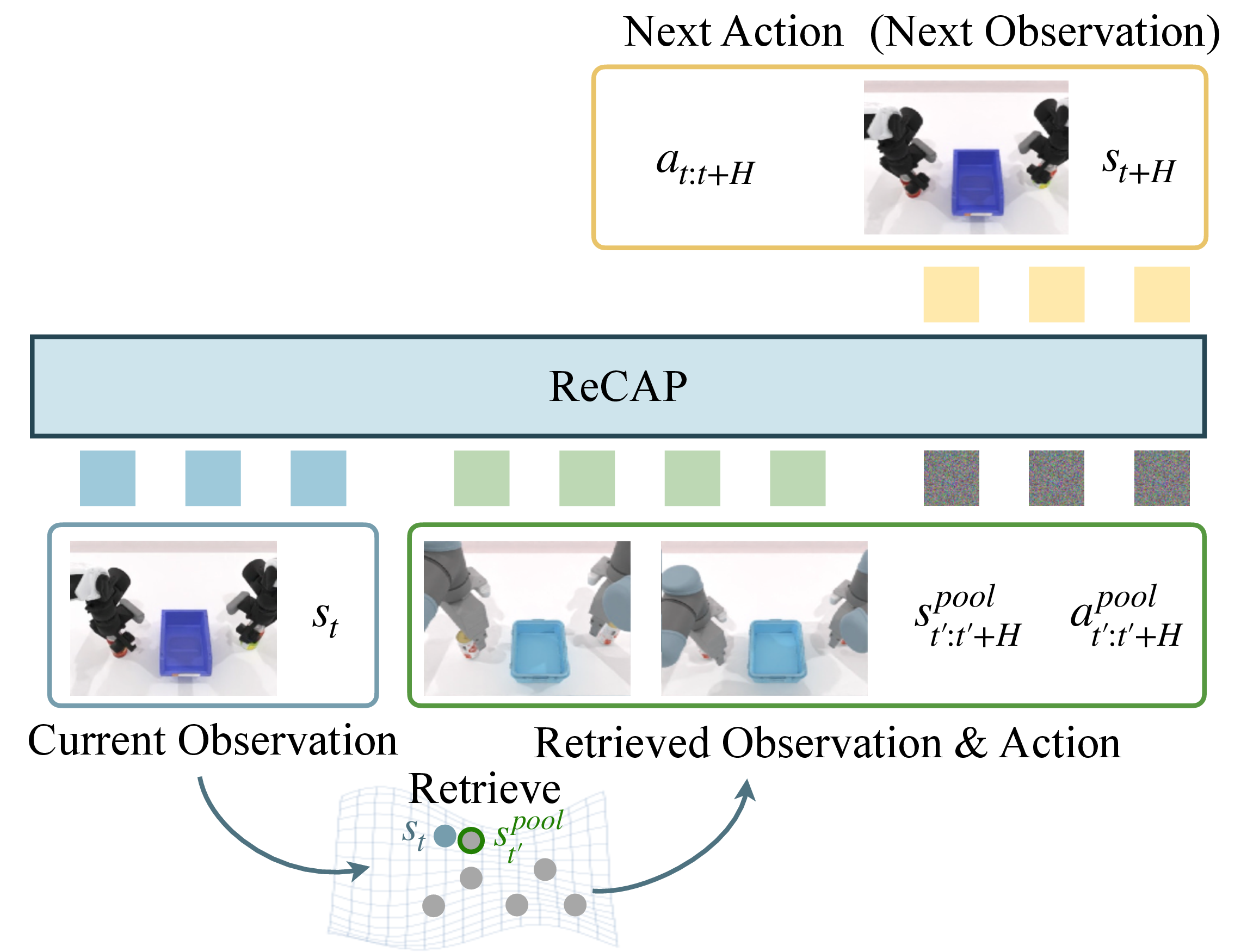
- 핵심 아이디어는 target robot과 pool embodiment가 “무엇을 해야 하는지”라는 high-level task progression은 공유하고, “어떻게 실행하는지”라는 embodiment-specific dynamics만 다르다는 가정 아래, retrieved pool trajectory를 coarse motion prior로 쓰고 policy는 residual correction만 예측하게 하는 것이다.
- Cosmos Policy 기반 WAM에 retrieved state-action chunk를 clean conditioning frames로 prepend하고, action과 future observation을 하나의 flow-matching objective로 joint denoising하며, action은
target action = retrieved pool action + residual형태로 parameterize한다. - 실험에서는 PushT unseen angle success가 6.0%에서 34.9%, RoboTwin unseen task success가 strongest baseline 26.0%에서 31.5%로 개선되고, real robot에서도 open-cabinet만 fine-tuning한 뒤 held-out tasks를 human-hand retrieval만으로 일부 수행한다.