



Realtime-VLA FLASH: Speculative Inference Framework for Diffusion-based VLAs
이 논문은 Diffusion-based Vision-Language-Action 모델(dVLAs)이 high latency로 인해 real-time deployment에서 제한된다는 문제를 speculative inference framework로 완화한다. 이 개념은 LLM의 speculative decoding과 컨셉을 공유하는데, 가벼운 draft model이 후보 action들을 만들어주면 기존의 무거운 모델이 이것을 parallel하게 verify하는 것이다. 하지만 dVLA는 continuous action chunk를 생성하고 explicit likelihood가 없기 때문에, draft token을 큰 모델이 확률적으로 accept/reject하는 것이 아니라 draft action chunk가 main action expert의 flow field와 locally consistent한지 검사한다는 점이 다르다.
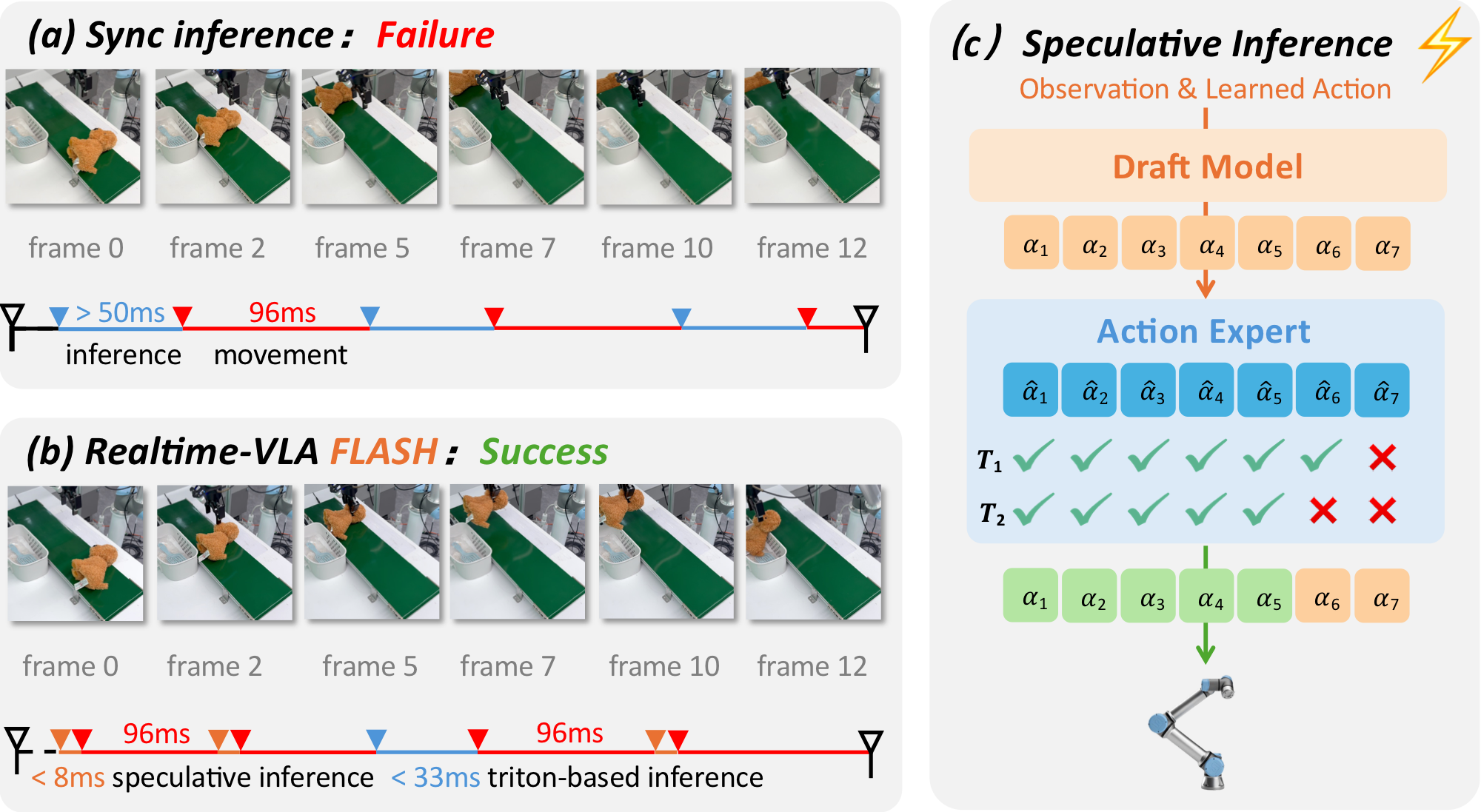 Overall Figure
Overall Figure
Introduction
$\pi_0$ 같은 dVLA의 inference는 보통 다음과 같은 구조를 가진다:
- 카메라 이미지와 언어 명령을 받아 VLM backbone이 perception 및 context를 처리한다.
- VLM이 만든 prefix KV cache를 action expert에 넘겨준다.
- action expert가 flow matching / diffusion-style denoising을 수행하여 continuous action chunk를 생성한다.
- 로봇은 action chunk의 앞부분 일부를 실행한 뒤 다시 replanning한다.
위 방법의 문제는 로봇의 제어 주기보다 모델 자체의 inference의 속도가 훨씬 느리다는 점이다. 기존 방식은 action chunking으로 이 간극을 줄였다. 하지만 replanning round가 발생할 때마다 여전히 비싼 full inference pipeline을 다시 돌려야 하기 때문에 end-to-end inference latency가 reactive manipulation의 bottleneck이 된다.
LLM speculative decoding에서는 작은 draft model이 token을 먼저 생성(제안)하고, 큰 model이 이 token의 probability를 이용해서 parallel하게 검증한다. 하지만 $\pi_0$-style dVLA는 discrete하지 않고 continuous한 action chunk를 생성하고, 또한 explicit하게 likelihood를 구하기 힘들다. 따라서 어떤 action chunk가 더 “plausible”한지 정의하기가 어렵다. Denoising step이 sequential ODE integration 구조라는 점 또한 효율적으로 검증하는데 방해가 된다. 본 논문의 저자들은 dVLA에 speculative inference를 적용하기 위해서는 1) draft proposal, 2) parallel verification, 3) acceptance criterion이 필요하다고 주장한다.
Flow matching은 Gaussian noise와 target action endpoint 사이의 linear interpolation path에서 velocity field를 학습하는 방식이다. 따라서 draft action endpoint가 주어졌을 때, 그 endpoint와 noise 사이의 중간 지점들을 만들고 main action expert가 그 중간 지점에서 예측하는 velocity가 다시 draft endpoint와 일치하는지는 쉽게 계산할 수 있다. 이것을 이용해서 verification을 진행한다는 것이 핵심이다.
Method
Latency Analysis
$\pi_0$-style dVLA의 full inference는 크게 Image Encoder / VLM Prefill / Action Denoise 세 단계로 나눌 수 있다. 저자들은 NVIDIA RTX 4090D에서 각 단계를 profiling했는데, 각각 11.3ms, 26.7ms, 20.0ms의 latency를 보였다고 한다. 이를 이용해서 roofline analysis를 한 결과는 아래와 같다. 즉 Image Encoder와 VLM Prefill 단계는 주로 compute-bound이고, Action Denoise는 memory-bound이다. Action Denoise는 매 denoising step마다 cache를 반복적으로 읽지만 denoising 자체가 sequential하기 때문에 병렬화가 어렵기 때문이다. 이는 다른 논문들에서도 일관되게 발견할 수 있는 결론이다.
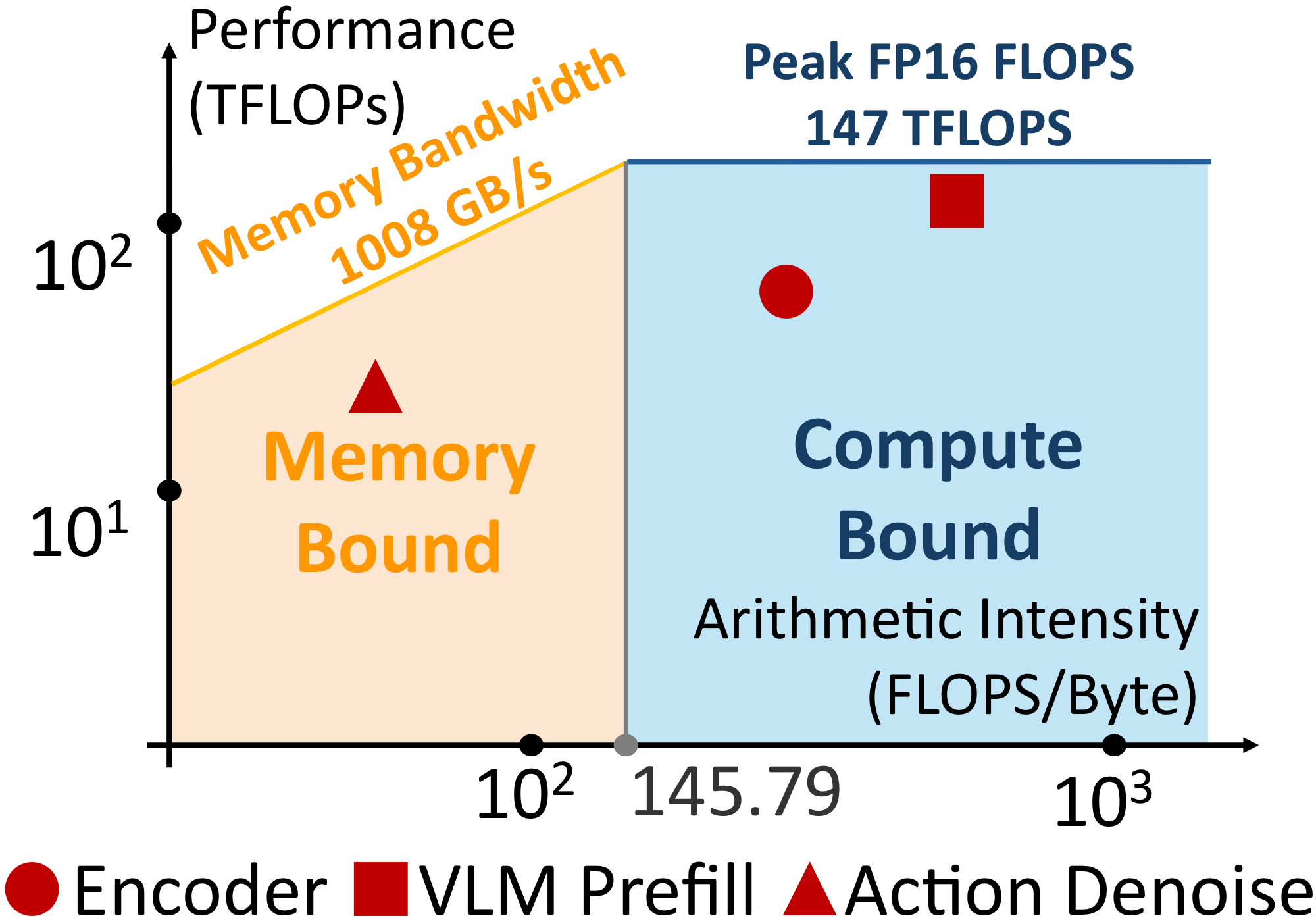 Roofline analysis
Roofline analysis
Realtime-VLA FLASH Overview
본 논문에서 제안하는 전체 Framework 및 Draft Model은 다음 그림과 같다:
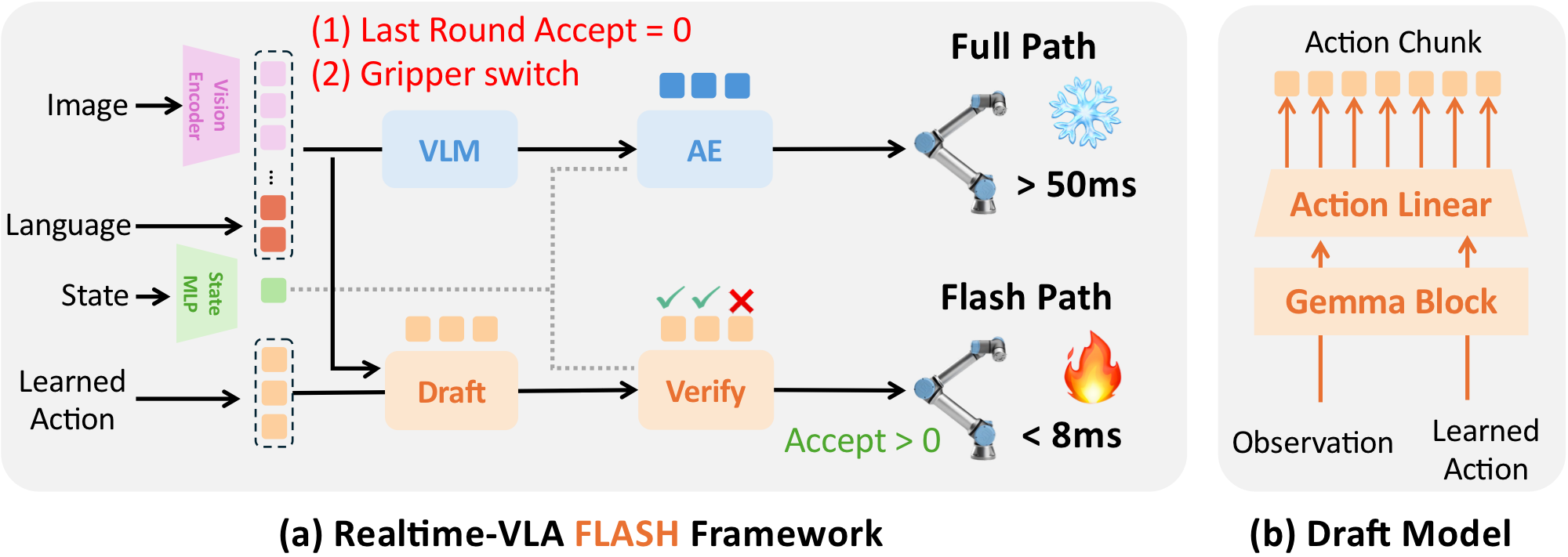 Realtime-VLA FLASH Framework
Realtime-VLA FLASH Framework
위 그림에서 알 수 있듯이, FLASH에서는 두 개의 inference path를 둔다:
| Path | 수행 내용 |
|---|---|
| Full Path | Image Encoder → VLM Prefill → Action Denoise |
| Flash Path | current image encoding → lightweight draft model → Action Expert parallel verification |
Flash path는 full path(기존 $\pi_0$의 inference)와 마찬가지로 현재 이미지를 encode하지만, full VLM prefill을 생략하고 대신에 최근 full path round에서 만든 visual KV cache를 재사용한다. 이를 이용해 lightweight draft model이 candidate action chunk를 만든 뒤, main model의 action expert가 selected denoising timesteps에서 endpoint reconstruction을 수행해 draft와의 consistency를 검사한다. 만약에 draft가 제안한 후보들이 하나도 accept되지 않는다면, 다시 full path로 돌아가 cache를 refresh하고 trajectory를 보정한다. 즉 draft가 감당하기 힘들 정도로 위험한 상황에서는 속도 대신 기존의 느리고 정확한 모델을 사용한다.
Draft model은 $H$개의 learned action query를 sequence에 붙여서 $H$ 길이의 horizon을 가지는 후보 action chunk를 parallel하게 제안한다. 이 draft endpoint들이 action expert가 보기에도 그럴듯한 endpoint인지 확인하기 위해, intermediate denoising state를 만들고 이를 action expert에 넣어 velocity를 예측하게 한다. 이 velocity를 이용해 endpoint를 한 번에 reconstruct한다. 만약 draft endpoint가 main policy와 local하게 consistent하다면, reconstructed endpoint는 draft endpoint와 가까울 것이다. FLASH는 action chunk 전체를 binary accept/reject하지 않고 longest consistent prefix를 실행한다(action chunk 전체가 완벽하지 않아도, 앞부분 몇 step은 충분히 안전하고 유용할 수 있기 때문).
수식
구체적으로 draft endpoint $\hat{A}^{(d)}_t$와 Gaussian noise $\epsilon$을 이용해
\[ \tilde{A}_{\tau} = \tau \hat{A}^{(d)}_t + (1-\tau)\epsilon \]를 만들고, action expert가 예측한 velocity를 이용해 endpoint를 다음처럼 복원한다.
\[ \hat{A}_t(\tau) = \tilde{A}_{\tau} + (1-\tau)v_\theta(\tilde{A}_{\tau}, \tau \mid c_t, s_t) \]만약 draft endpoint가 main action expert의 flow field와 local하게 consistent하다면, 복원된 endpoint $\hat{A}_t(\tau)$는 draft endpoint $\hat{A}^{(d)}_t$와 가까워야 한다.
추가적으로, FLASH는 gripper switch를 phase transition signal로 사용한다. Gripper가 손을 집거나 놓기 시작하는 지점은 중요한 phase transition이라고 간주할 수 있기 때문에 이런 순간은 full path로 fallback한다.
Experiments
NVIDIA RTX 4090D를 이용했고, 시뮬레이션으로는 LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, LIBERO-10을 사용했다. Real-world 실험으로는 single-arm UR5에 2개의 Intel RealSense D435i 카메라를 가지고 conveyor-belt sorting 세팅을 사용했다. 주목할 만한 점은 FLASH에 Triton을 결합한 버전까지 구현했다는 점이다.
핵심 결과는 성공률을 크게 잃지 않으면서 latency를 크게 줄였다는 점이다. LIBERO에서 FLASH+Triton-$\pi_0$는 Torch-$\pi_0$ 대비 평균 success rate를 94.1%에서 93.8%로 거의 유지하면서, 평균 task-level inference latency를 58.0ms에서 19.1ms로 줄였고, 3.04× speedup을 보였다. Real-world conveyor-belt sorting에서도 inference latency가 실제 task success에 직접적인 영향을 준다는 것을 보였는데, 15 m/min 조건에서 기존 baseline들은 모두 실패한 반면 FLASH+Triton-$\pi_0$는 nonzero success를 유지했다.
Limitations
FLASH의 verification은 accepted draft가 full-path rollout과 동일한 trajectory를 만든다는 formal guarantee는 아니다. Draft endpoint가 reused KV cache와 current robot state 아래에서 action expert의 learned flow field와 local하게 compatible한지를 보는 heuristic consistency test에 가깝다. 따라서 fixed threshold, selected verification timestep, gripper-switch fallback 같은 heuristic에 의존하며, 더 adaptive한 verifier 설계가 중요한 future work로 남는다.
Personal Idea
- 여기서 사용하는 KV cache 부분에 OxyGen을 결합할 수 있을까? 할 수 있다면 그렇게 해서 얻는 이득은?
- Flow matching이 아니라 diffusion model인 action expert라면, reparametrization이나 clean action estimate를 쓰면 되나?
Comments