



0. VAE(Variational AutoEncoder)
DDPM의 variational perspective를 이해하는 데 필요한 VAE의 핵심 개념을 정리
0. Background
이번, 그리고 이 category에서 앞으로 다룰 모든 게시물은 “생성 모델”, 즉 generative AI에 대해 다룬다. 생성 모델이란 image나 video 같이 우리가 보기에 의미가 있는 데이터를 “생성”하는 “모델”이다. 모델은 최근에는 neural network로 대부분 구현한다. 이것에 대해서도 다룰 것이 많으나 우선은 일반적인 “함수”, 즉 input이 주어지면 그에 따른 output을 만들어주는 box라 생각해도 된다. 생성 모델은 (input이 무엇인지는 차차 다룰 것이고) output이 의미가 있는 데이터, 예를 들어 image가 되는 box이다.
1. Building Blocks of VAE
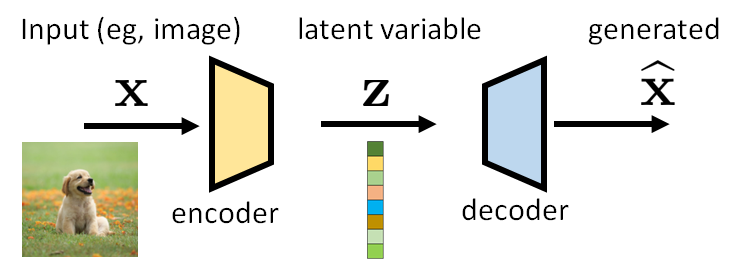 VAE overview
VAE overview
VAE는 크게 2개의 모델, encoder와 decoder로 구성되어 있다. Input vector $\mathbf{x}$(image처럼 우리가 generate하고 싶은 데이터)를 encoder에 넣어주면 output으로 latent variable $\mathbf{z}$라는 것이 나온다(이것의 의미는 곧 설명하겠다). 이 latent variable이라는 것을 decoder의 input으로 넣어주면 decoder가 $\hat{\mathbf{x}}$을 output으로 뱉어준다. Decoder의 목적은 $\mathbf{x}$와 최대한 비슷한 것을 output으로 만들도록 하는 것이다. 우리가 생성하고 싶은 것이 image라고 할 때, 왜 굳이 image를 넣어서 image를 다시 만드려고 할까?
VAE의 두 구성요소 중 encoder는 학습 과정에서만 사용하고, 실제 “생성 모델”로 VAE를 사용할 때는 decoder만 사용한다. 즉 학습이 완료된 모델을 사용할 때는 시작이 input vector $\mathbf{x}$가 아니라 latent variable $\mathbf{z}$이다. 이 latent variable이라는 것은 무엇일까?
Latent variable은 보통 우리가 생성하고 싶은 모델보다 차원이 낮은, 그리고 생성하기 쉬운 (그래서 우리가 보기에는 의미가 없어 보이는) 변수이다. 즉, encoder는 고차원 데이터를 input으로 받아서 저차원 데이터를 output으로 뱉어주고, 그 저차원 데이터를 가지고 decoder는 고차원 데이터를 복원하려고 노력한다.
만약 encoder가 input image $\mathbf{x}$에서 의미있는 정보만 잘 압축할 수 있다면, decoder의 output이 $\mathbf{x}$와 비슷하게 자연스러운 image가 될 수 있다!
물론 latent variable $\mathbf{z}$ 자체가 $\mathbf{x}$나 $\hat{\mathbf{x}}$보다 차원이 작기 때문에, 정보의 손실이 아예 없을수는 없다. 이것은 정보이론에서 증명되었다. 하지만 정보이론까지 갈 것도 없이 상식적으로 생각해봤을 때 실수 element의 개수가 5개인 모든 vector를 실수 element의 개수가 3개인 vector로 표현하는 것은 불가능하다. 그러니 최대한 “의미있는” 정보를 잘 압축해야 한다.
만약 encoder가 위에서 언급한 목적을 달성했고, decoder도 (뒤에서 자세히 설명할) 학습이 잘 되었다고 가정하자. 그러면 latent variable은 decoder가 생성할 image의 “씨앗”이 되어줄 것이다. 그리고 이 씨앗은 우리가 위에서 처음에 가정할 때 “생성하기 쉽다”고 가정했기 때문에 쉽게 씨앗을 만들고 이것을 decoder에 넣어준다면 결과적으로 쉽게 image를 생성한 것이 될 것이다.
VAE는 probabilistic model 중 하나로, probabilistic model이란 불확실한 현실을 확률분포로 표현해서 어떤 결과가 더 가능성이 높은지 추론하는 모델이다. 따라서 아직은 정확하게 그 원리를 설명하지 않았지만, 어쨌든 VAE가 학습이 잘 되었다면 이 모델은 우리가 보기에 의미가 있는 image들에 대한 분포를 잘 표현할 것이라 유추해볼 수 있다. 예를 들어서 이 세상에는 강아지가 서있는 image는 많지만, 강아지가 덤블링을 하는 image는 적을 것이다. 따라서 제대로 학습된 VAE는 전자의 image에 높은 확률을 부여할 것이므로 VAE에게 image를 생성하게 하면 전자의 image가 많이 나올 것이다.
논의를 더 진행하기 위해, VAE가 다루는 distribution들을 소개하겠다. Notation을 다시 언급하자면, $\mathbf{x}$는 우리가 만들고 싶은 데이터(여기서는 image라 통일하겠다)를 의미하고, $\mathbf{z}$는 latent variable을 의미한다.
- $p(\mathbf{x})$
- $\mathbf{x}$의 true distribution을 의미한다. 이것은 우리가 알 수 없는 분포이다. 만약 우리가 이것을 알 수 있었다면 VAE든 diffusion model이든 다 필요없이 그냥 이 분포에서 sampling을 하면 되었을 것이다..
- 하지만 우리는 이것을 approximate하는 분포를 만들어 낼 것이다.
- $p(\mathbf{z})$
- latent variable의 distribution을 의미한다. 이것에는 왜 굳이 true distribution이라고 말하지 않는가? 왜냐하면 $p(\mathbf{x})$는 우리가 정할 수 있는 것이 아니라 자연이 정해주는 것이라고 하면, $p(\mathbf{z})$는 우리가 정할 수 있기 때문에 굳이 이 분포에 대한 approximate를 하지 않아도 되기 때문이다. 즉 $p(\mathbf{z})$는 우리가 다루기 쉽게 (위에서의 논의를 이어서 말하자면, “생성하기 쉬운” 분포로) 설정해버리면 그만이다. 그것이 latent variable의 (true) distribution이다.
- 지금까지는 “생성하기 쉬운” 분포라고만 얘기했지만, 보통은 zero-mean unit-variance Gaussian $\mathcal{N}(0, \mathbf{I})$로 설정한다. 왜 굳이 이 분포일까? 앞으로의 논의를 이해하기에 반드시 필요한 이야기는 아니지만 짧게 설명하자면, Gaussian distribution의 linear transformation은 여전히 Gaussian이기 때문에 data processing이 더 쉬워진다는 이점이 있다. 또한 다른 문서에서는 충분히 똑똑한 함수가 있기만 한다면 어떠한 분포도 Gaussian에서 출발하는 mapping으로 만들 수 있다고 설명한다.
- $p( \mathbf{z} | \mathbf{x})$
- Encoder가 표현하는 conditional distribution이다. Image $\mathbf{x}$가 주어졌을 때(given) latent variable $\mathbf{z}$의 분포, 즉 likelihood를 표현한다.
- 엄밀하게는 이것도 $p(\mathbf{x})$처럼 참값을 구하는 것은 불가능하다. 사실은 encoder는 이것을 approximate하는 것이다.
- $p( \mathbf{x} | \mathbf{z})$
- Decoder가 표현하는(엄밀하게는 approximate하는) conditional distribution이다. 이는 posterior distribution이라고 부른다.
즉 우리가 정확하게 알 수 있는 분포는 $p(\mathbf{z})$뿐이다. 추가적으로 deep latent variable이란 $p(\mathbf{z})$ 또는 $p( \mathbf{z} | \mathbf{x})$ 또는 $p( \mathbf{x} | \mathbf{z})$가 neural network로 parameterized되는(표현되는) latent variable을 말한다. 여기서는 encoder와 decoder를 neural network로 만든다. Neural network가 충분히 똑똑하다면, standard normal distribution $\mathcal{N}(0, \mathbf{I})$같은 쉬운 distribution만으로 매우 복잡한 data distribution $p(\mathbf{x})$을 표현할 수 있을 것이다.
Encoder와 decoder의 학습 방법에 대해서 논의하기 위해, notation을 더 정확히 한다:
- $q_{\boldsymbol{\phi}}( \mathbf{z} | \mathbf{x})$
- $p( \mathbf{z} | \mathbf{x})$를 approximate하는 encoder가 표현하는 분포. 즉 encoder는 이 분포를 나타낸다. 학습이 되기 전의 encoder는 $q_{\boldsymbol{\phi}}( \mathbf{z} | \mathbf{x})$가 $p( \mathbf{z} | \mathbf{x})$와 매우 다를 것이고 학습이 잘된 encoder는 둘이 비슷할 것이다. $\boldsymbol{\phi}$는 encoder neural network의 parameter를 나타낸다. Neural network에 대해서 잘 모르는 사람을 위해서 짧게 말하자면, neural network를 학습시킨다는 것은 결국 이 parameter라는 것의 수치를 잘 조절한다는 것을 말한다.
- $q_{\boldsymbol{\phi}}( \mathbf{z} | \mathbf{x})$를 어떻게 표현할지에 대한 특별한 제약은 없지만, 보통은 Gaussian distribution의 mean과 covariance로 표현한다(because of its tractability and computational efficiency). 즉 아래와 같이 사용한다:
- $\text{diag}(\boldsymbol{\sigma}^2)$ 같은 위 표현에 대해서 이해가 잘 되지 않는 사람은 Claude나 ChatGPT 등등에 물어보면 된다. 귀찮은 사람들을 위해서 짧게 설명하자면 데이터가 1차원이라면 Gaussian 분포의 평균과 분산을 neural network가 output으로 뱉어준다고 생각하면 된다. 그렇게 완성된 Gaussian 분포에서 sampling한 결과가 latent variable $\mathbf{z}$이다.
- $p_{\boldsymbol{\theta}}( \mathbf{x} | \mathbf{z})$
- $p( \mathbf{x} | \mathbf{z})$를 approximate하는 decoder가 표현하는 분포. 즉 decoder는 이 분포를 나타낸다. $\boldsymbol{\theta}$는 decoder neural network의 parameter를 나타낸다. Encoder와 비슷하게 아래와 같이 사용한다:
- Encoder와 다르게 decoder는 output이 mean 하나다. Covariance는 hyperparameter(parameter처럼 학습 중에 변하는 값이 아니라, 사람이 미리 정해놓고 변하지 않는 값)로 설정한다. 물론 이렇게 하지 않고 covariance까지 학습해도 된다.
지금까지의 논의를 정리하는 그림은 아래와 같다. $\mathbf{x} \rightarrow \mathbf{z}$는 “forward” relationship이라고 하고(encoder $q_{\boldsymbol{\phi}}( \mathbf{z} | \mathbf{x})$), $\mathbf{z} \rightarrow \mathbf{x}$는 “backward” relationship이라고 한다(decoder $p_{\boldsymbol{\theta}}( \mathbf{x} | \mathbf{z})$).
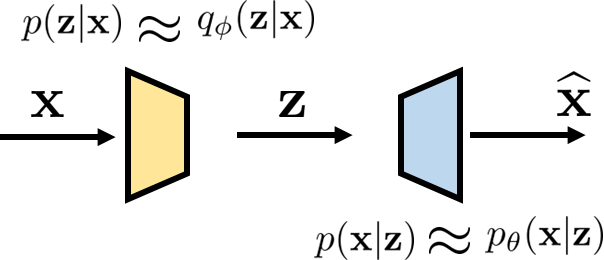 encoder & decoder
encoder & decoder