



3DThinkVLA: Endowing Vision-Language-Action Models with Latent 3D Priors via 3D-Thinking-Guided Co-training
pretrained VLA를 VLA data + real-world 3D reasoning data로 co-training하면서, 3D foundation model과 reasoning-prompt teacher를 학습 중에만 사용해 2D image-only inference에서도 implicit 3D spatial reasoning을 action prediction에 주입
Overview Figure
Summary
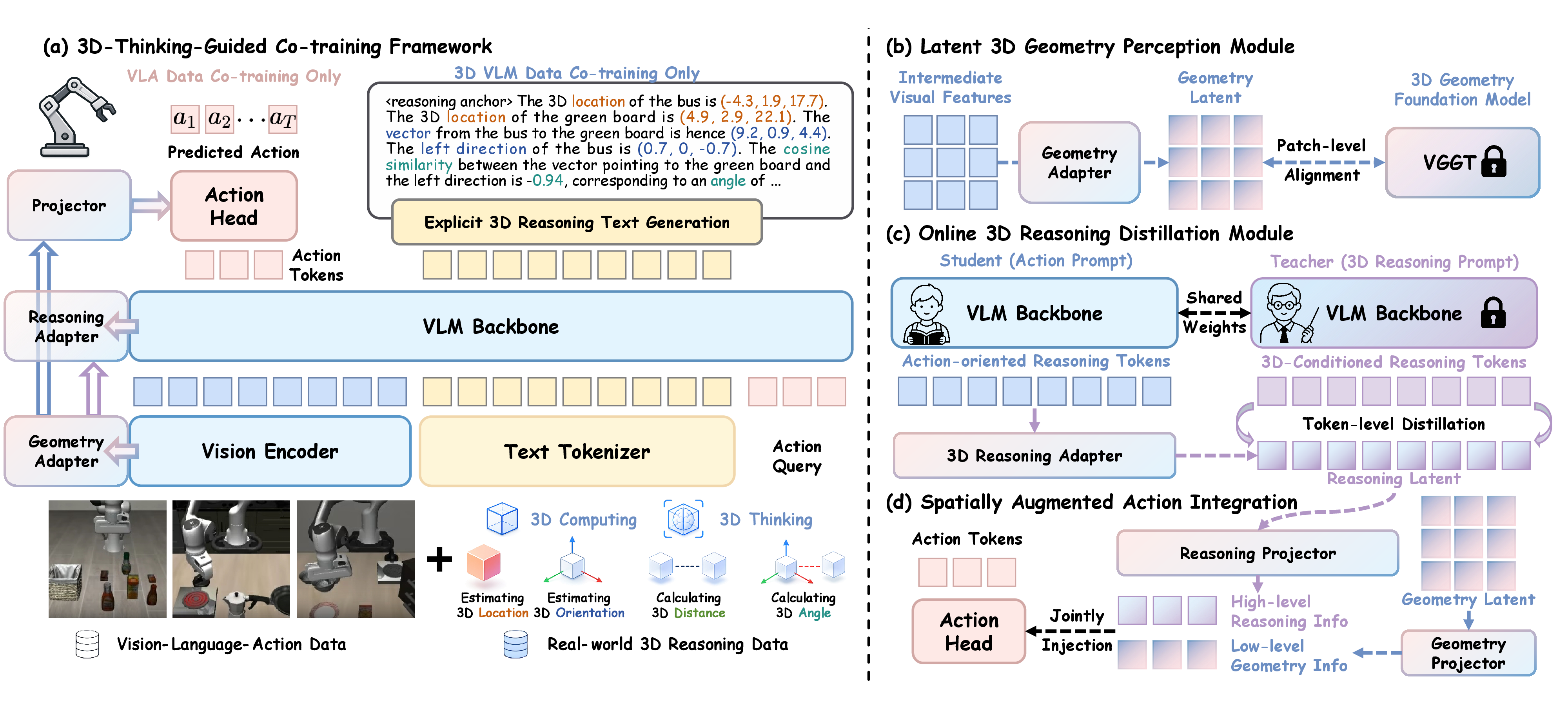
- 기존 2D-image 기반 VLA는 semantic recognition은 강하지만, object height, relative pose, orientation, distance 같은 3D spatial reasoning이 약해서 manipulation에서 2D semantic/action shortcut에 의존하기 쉽다.
- Explicit 3D input을 쓰는 방법은 depth/point cloud sensor나 backbone modification이 필요하고, 단순 3D data co-training은 action prompt가 들어올 때 3D reasoning이 비활성화되는 prompt-induced reasoning gap을 만든다.
- 3DThinkVLA는 3D geometry perception과 3D spatial reasoning을 분리해서, 전자는 VGGT feature alignment로, 후자는 reasoning-anchor token 기반 online latent distillation으로 학습한다.
- Inference에서는 VGGT, teacher reasoning pathway, explicit CoT text generation을 모두 제거하고, geometry/reasoning adapters와 projection path만 남겨 action query token에 low-level geometry + high-level reasoning latent를 더한다.
- 실험적으로 LIBERO 평균 98.7%, LIBERO-PLUS 평균 81.0%, SimplerEnv 평균 72.9%, real-world task에서 $\pi_{0}$/OpenVLA-OFT보다 높은 성공률을 보고하지만, training cost가 1.5배 증가하고 일부 perturbation/task에서는 성능 우위가 약하다.