



GRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
3D asset과 video foundation model prior를 이용해 humanoid loco-manipulation용 4D human-object interaction 데이터를 완전 디지털로 생성하고, 이를 Unitree G1용 tracking policy와 egocentric visual policy로 변환해 실제 로봇에 배포하는 data-generation / sim-to-real framework
Overview Figure
Summary
- 기존 humanoid loco-manipulation 데이터는 teleoperation, motion capture, in-the-wild video reconstruction에 의존하는데, 이는 물리적 세팅 변경, actor instrumentation, robot operation, monocular depth/scale/contact ambiguity 때문에 scale-up이 어렵다.
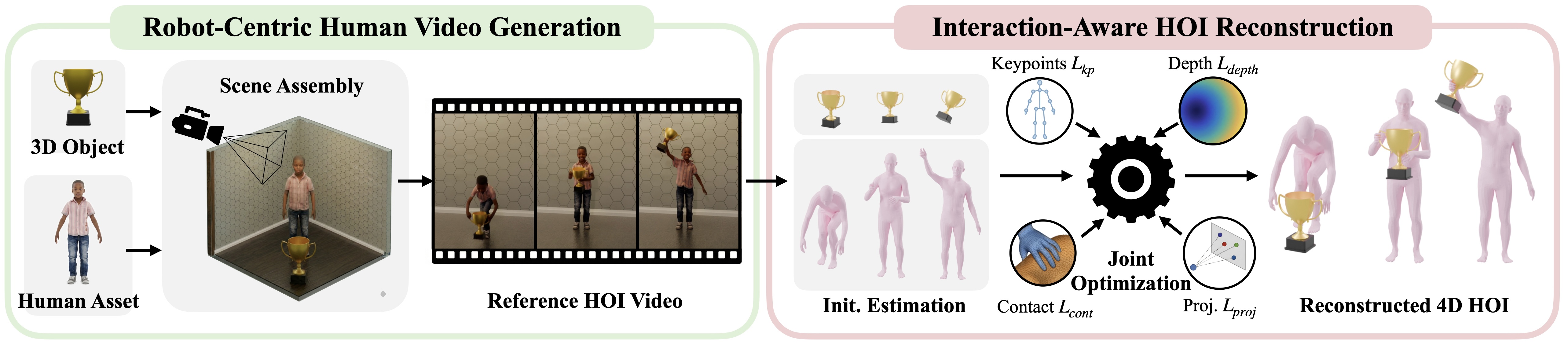
- GRAIL은 “먼저 3D scene을 완전히 지정하고, 그 위에서 VFM(Video Foundation Model)이 interaction video를 만들게 한 뒤, 알려진 geometry/camera/scale/depth를 이용해 4D HOI(4D Human-Object Interaction, 시간에 따라 변하는 human pose와 object pose를 함께 복원하는 문제)를 복원한다”는 방향으로 문제를 바꾼다.
- 핵심 아이디어는 uncontrolled video를 4D로 억지 복원하는 대신, privileged 3D configuration 안에서 video prior를 interaction prior로만 사용하고 metric reconstruction은 known 3D assets와 scene geometry에 anchor하는 것이다.
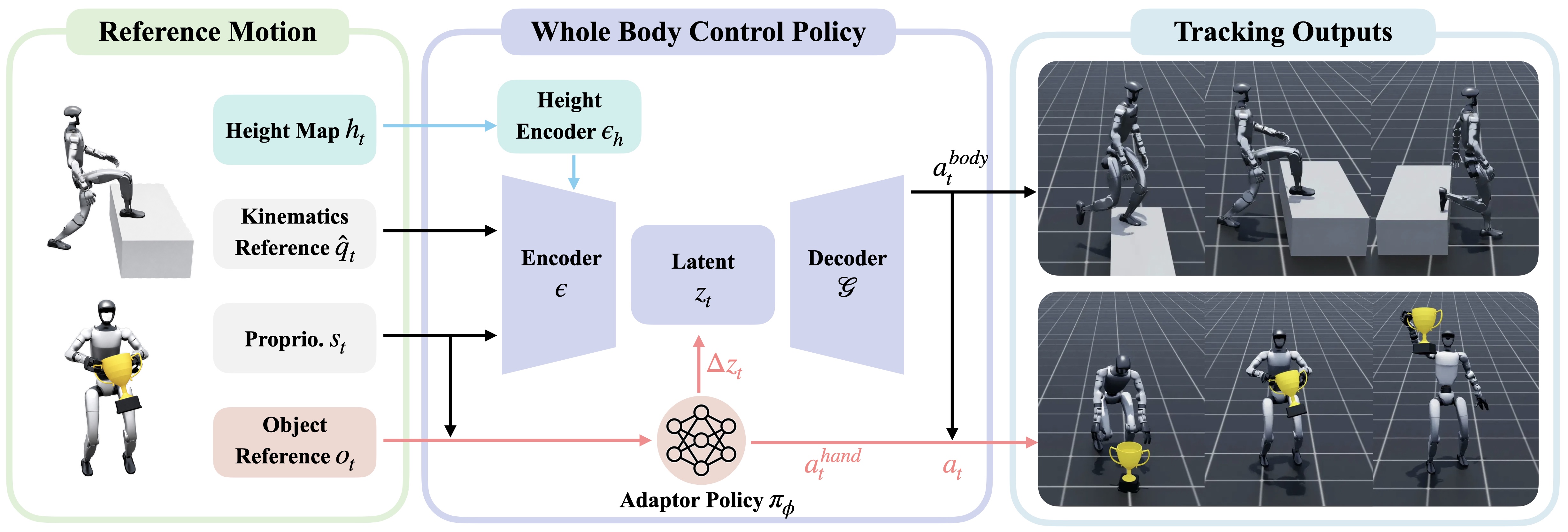
- 이후 복원된 4D HOI를 Unitree G1에 retargeting하고, pretrained whole-body controller SONIC 위에 object-aware latent adaptor와 scene-aware tracker를 학습해 task-general tracking policy를 만든다.
- 결과적으로 GRAIL은 20,000개 이상의 generated sequence를 만들고, 이 데이터만으로 학습한 egocentric visual policy를 실제 Unitree G1에 배포해 object pick-up 84%, stair-climbing 90% real-world success를 보고한다.