



ActionMap: Robot Policy Learning via Voxel Action Heatmap
VLA의 기존 single-point action decoder를 3D translation / 3D rotation / gripper voxel heatmap action head로 교체해, action space의 geometric proximity(인접성)를 학습 신호로 활용
Overview Figure
Summary
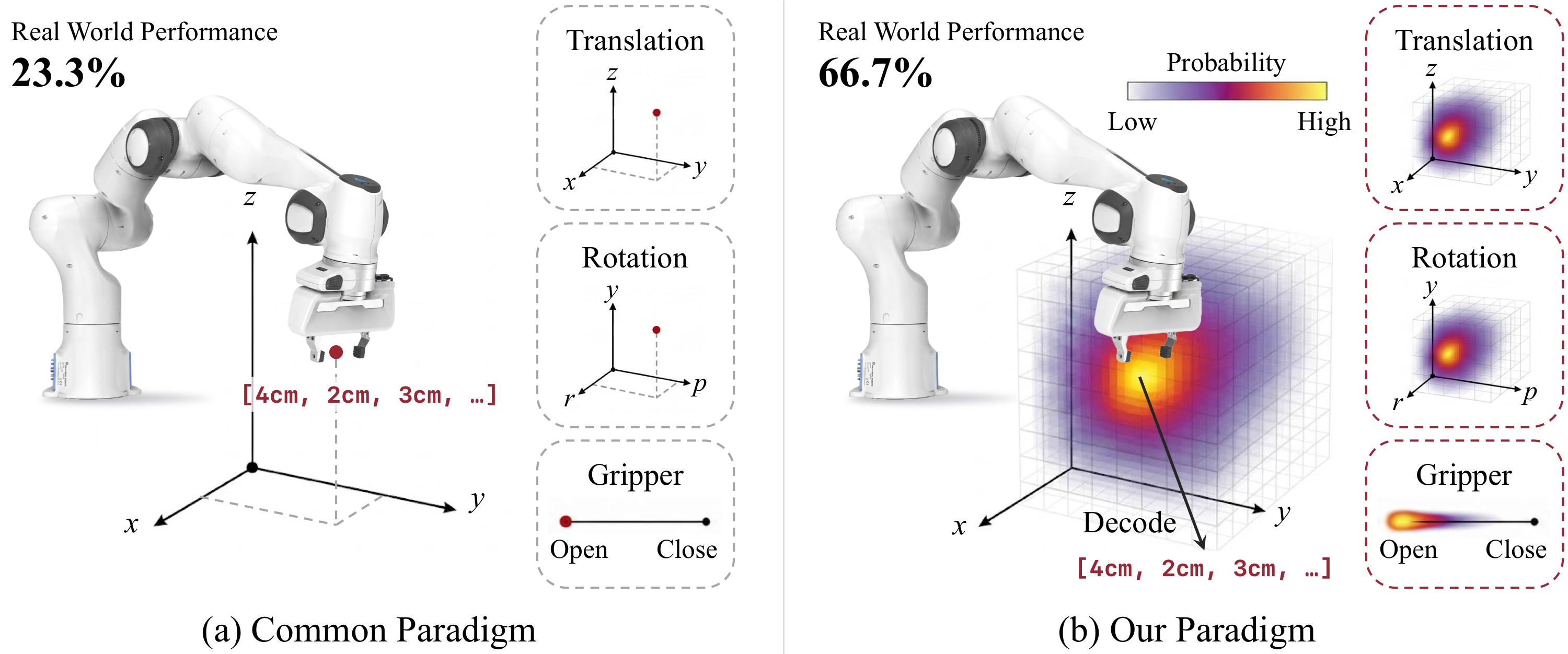
- 기존 VLA는 backbone, dataset, training recipe는 빠르게 커졌지만, action decoder는 여전히 autoregressive token, L1 regression, flow-matching denoising처럼 최종적으로 하나의 point action을 예측하는 구조가 많아 action space의 spatial structure를 충분히 활용하지 못한다.
- 이 논문은 end-effector action이 연속적인 기하 공간에 놓여 있고, 서로 가까운 action들이 물리적으로 비슷한 의미를 갖는다는 점을 action head 설계에 직접 넣으려 한다.
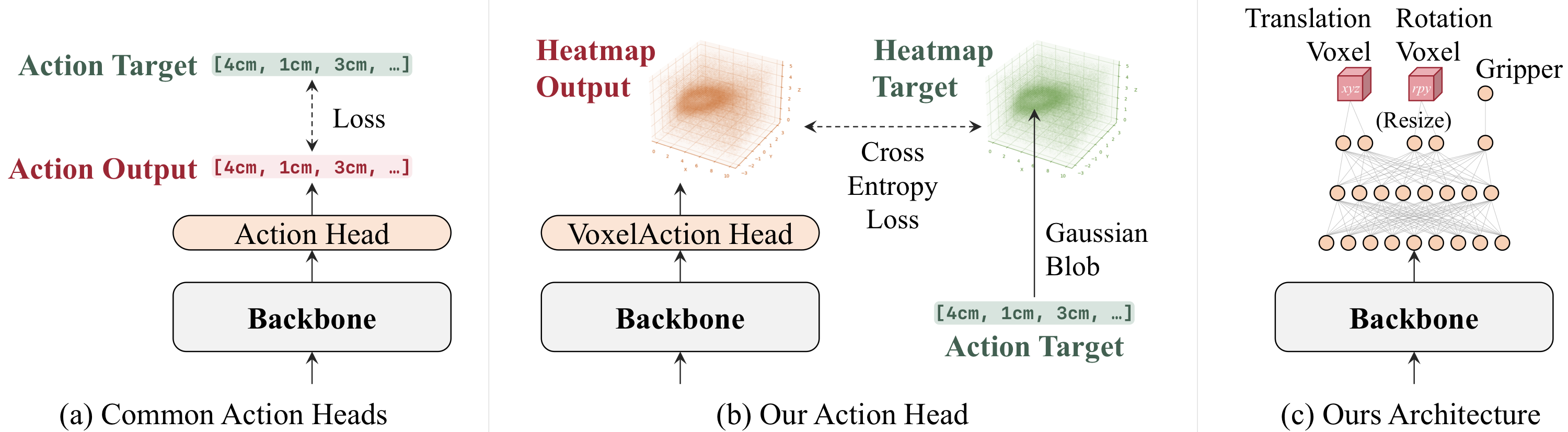
- 핵심 아이디어는 action을 직접 회귀하지 않고, translation voxel grid, rotation voxel grid, gripper distribution 위의 probability heatmap으로 예측한 뒤 Gaussian-blob soft target과 cross-entropy로 학습하고 top-k soft-argmax로 continuous action을 복원하는 것이다.
- 이 head는 OpenVLA-OFT의 L1 regression head와 $\pi_{0.5}$의 flow-matching action expert를 대체하는 drop-in component로 제안되며, backbone 자체는 크게 바꾸지 않는다.
- 실험에서는 LIBERO와 real-world Franka에서 OpenVLA-OFT 및 $\pi_{0.5}$ baseline보다 success rate, data efficiency, convergence 면에서 개선을 보였고, 특히 OpenVLA-OFT + low-data / long-horizon setting에서 gain이 크다.