



Q-VGM: Q-Guided Value-Gradient Matching for Flow-Matching VLA Policies
few-shot SFT된 π0.5 flow-matching VLA를 고정된 self-rollout buffer와 learned Q-critic의 action-gradient로 offline RL fine-tuning하되, Q-gradient를 terminal action label이 아니라 denoising-time residual velocity supervision으로 바꾸어 학습
Overview Figure
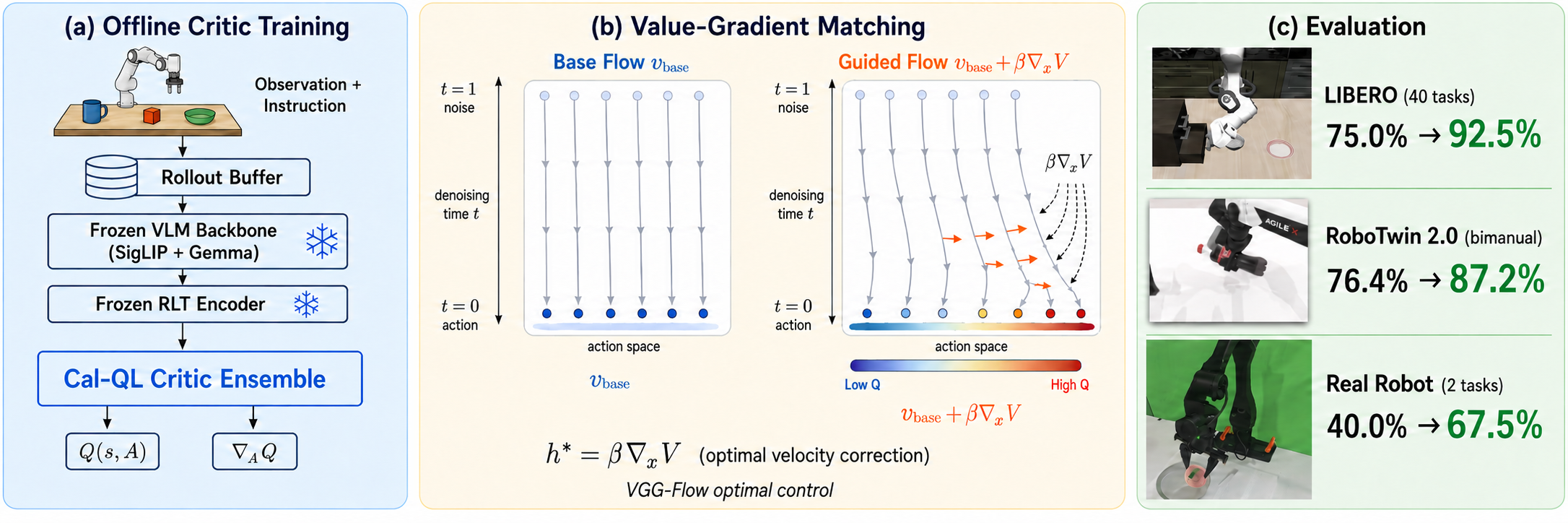
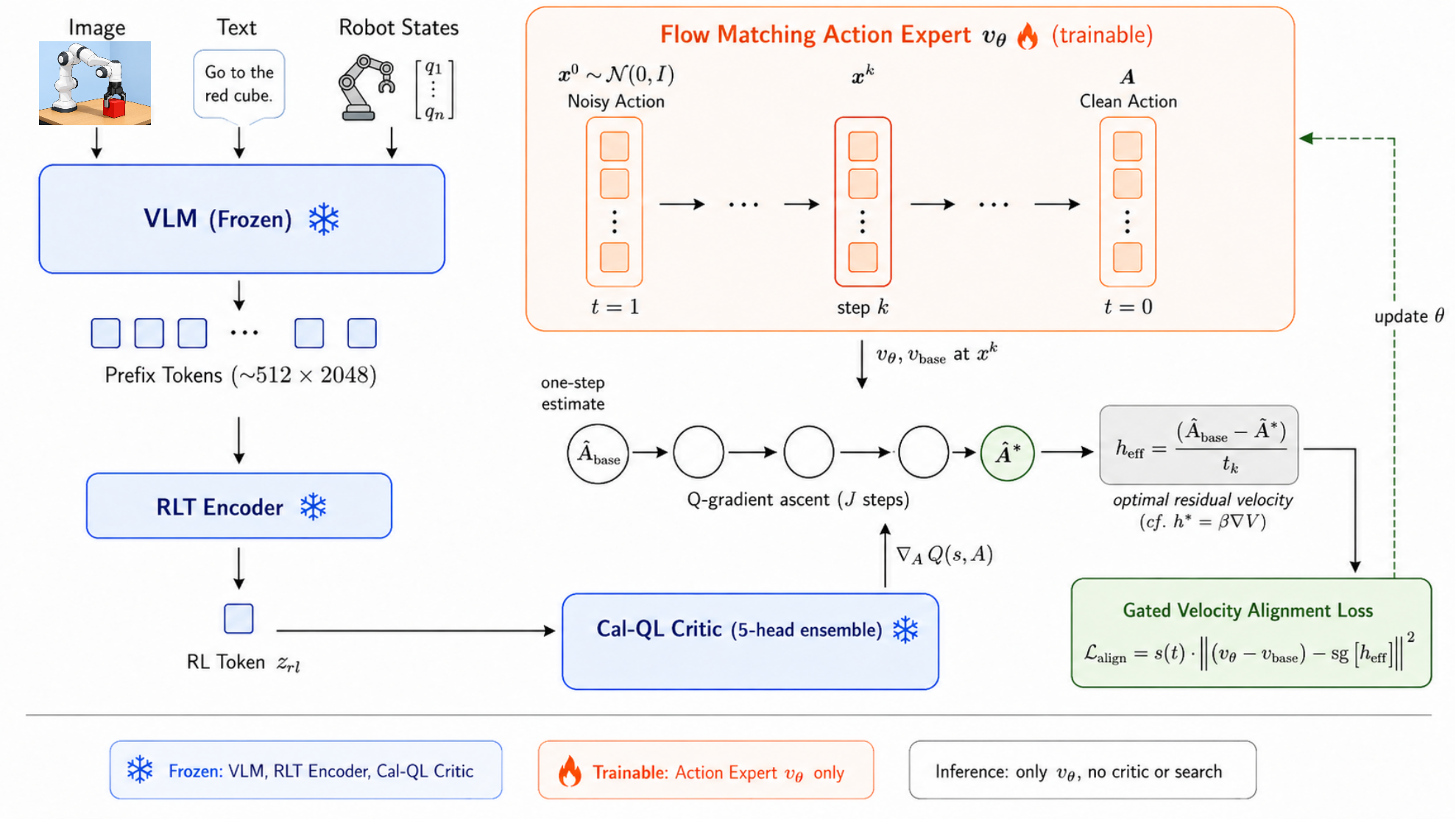
Summary
- 기존 flow-matching VLA policy는 continuous action chunk를 잘 생성하지만, policy-gradient RL에는 tractable action likelihood가 없고, direct Q-maximization은 multi-step denoising chain 전체로 critic gradient를 backpropagate해야 해서 VLA scale에서 불안정하다는 문제가 있다.
- 이 논문은 pretrained / few-shot-SFT $\pi_{0.5}$ VLA를 추가 expert demonstration 없이 self-generated rollout data만으로 task success가 높아지도록 offline value-guided fine-tuning하는 문제를 다룬다.
- 핵심 아이디어는 learned Q-function의 action-space gradient $\nabla_{A}Q(s, A)$를 clean action에서만 쓰는 것이 아니라, denoising 중간 상태마다 value-improved clean-action estimate를 만들고 이를 residual velocity target으로 변환해 flow action expert를 학습시키는 것이다.
- 구체적으로는 frozen VLM/RLT feature 기반의 action-sensitive Cal-QL critic을 먼저 학습하고, 이후 각 denoising state에서 frozen base velocity로 clean-action estimate를 만든 뒤 Q-gradient ascent, keep-best selection, gated residual velocity matching을 수행한다.
- LIBERO 평균 성공률은 75.0% → 92.5%, RoboTwin 2.0은 76.4% → 87.2%, real robot tabletop tasks는 40.0% → 67.5%로 개선되며, 같은 backbone / 같은 critic을 쓰는 test-time Q-selection, Q-guidance, Q-distillation, Diffusion-QL보다 높은 성능을 보인다.