



AHA-WAM: Asynchronous Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing
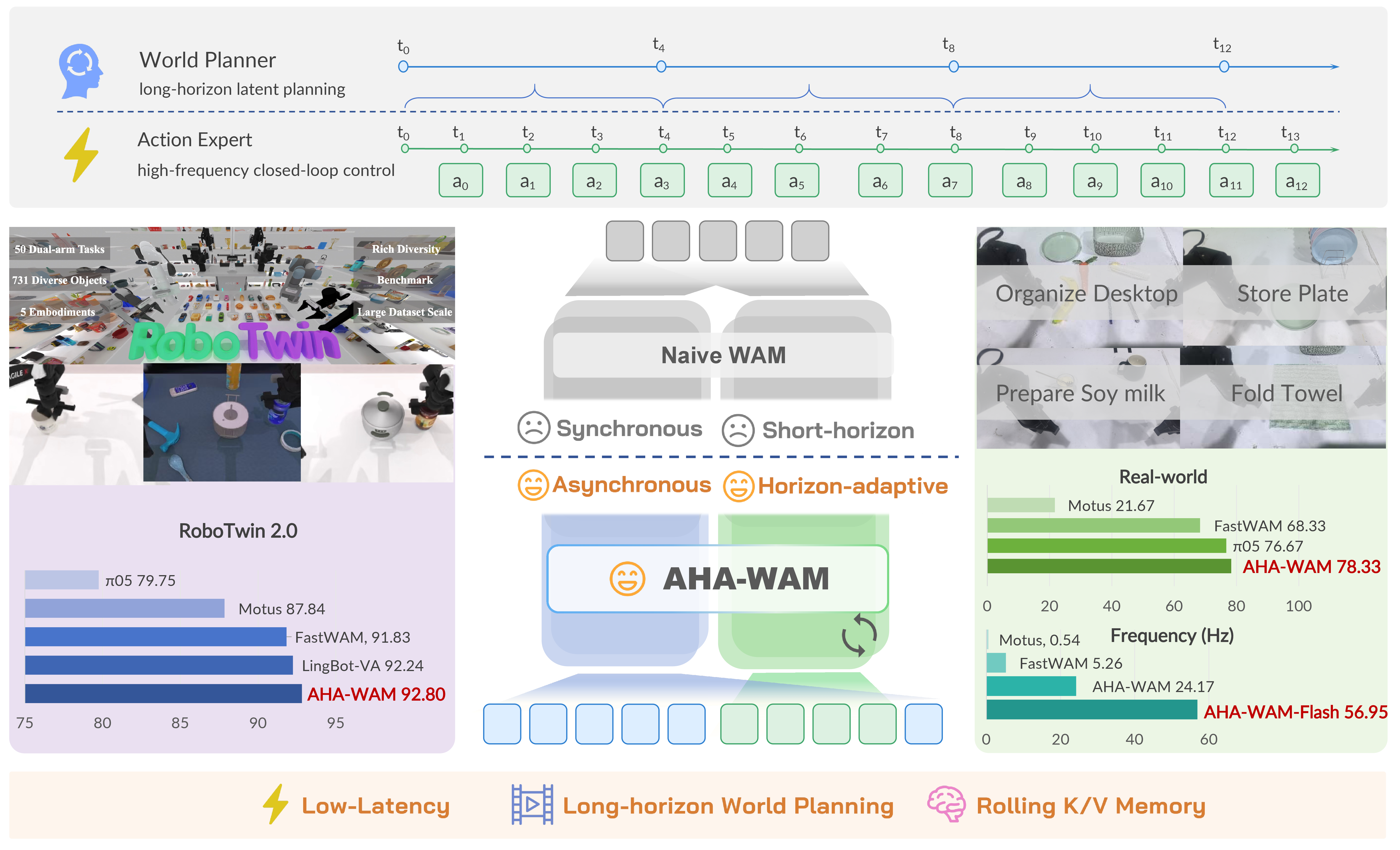
Video-DiT world planner는 low-frequency로 long-horizon latent context를 만들고, Action-DiT executor는 OVCR로 최신 observation에 맞게 context를 보정해 short action chunk를 high-frequency closed-loop로 실행하는 asynchronous WAM
Overview Figure
Summary
- 기존 WAM은 future video prediction과 action generation을 같은 짧은 horizon / temporal rhythm에 결합해, video branch가 실제 제어에 덜 중요한 dense adjacent-frame variation까지 매 control step마다 처리해야 한다는 inefficiency가 있었다.
- AHA-WAM은 video branch는 느리지만 긴 horizon의 latent world planning을 하고, action branch는 빠르게 최신 observation/proprioception을 반영해 short action chunk를 실행해야 한다는 temporal asymmetry를 문제의 핵심으로 본다.
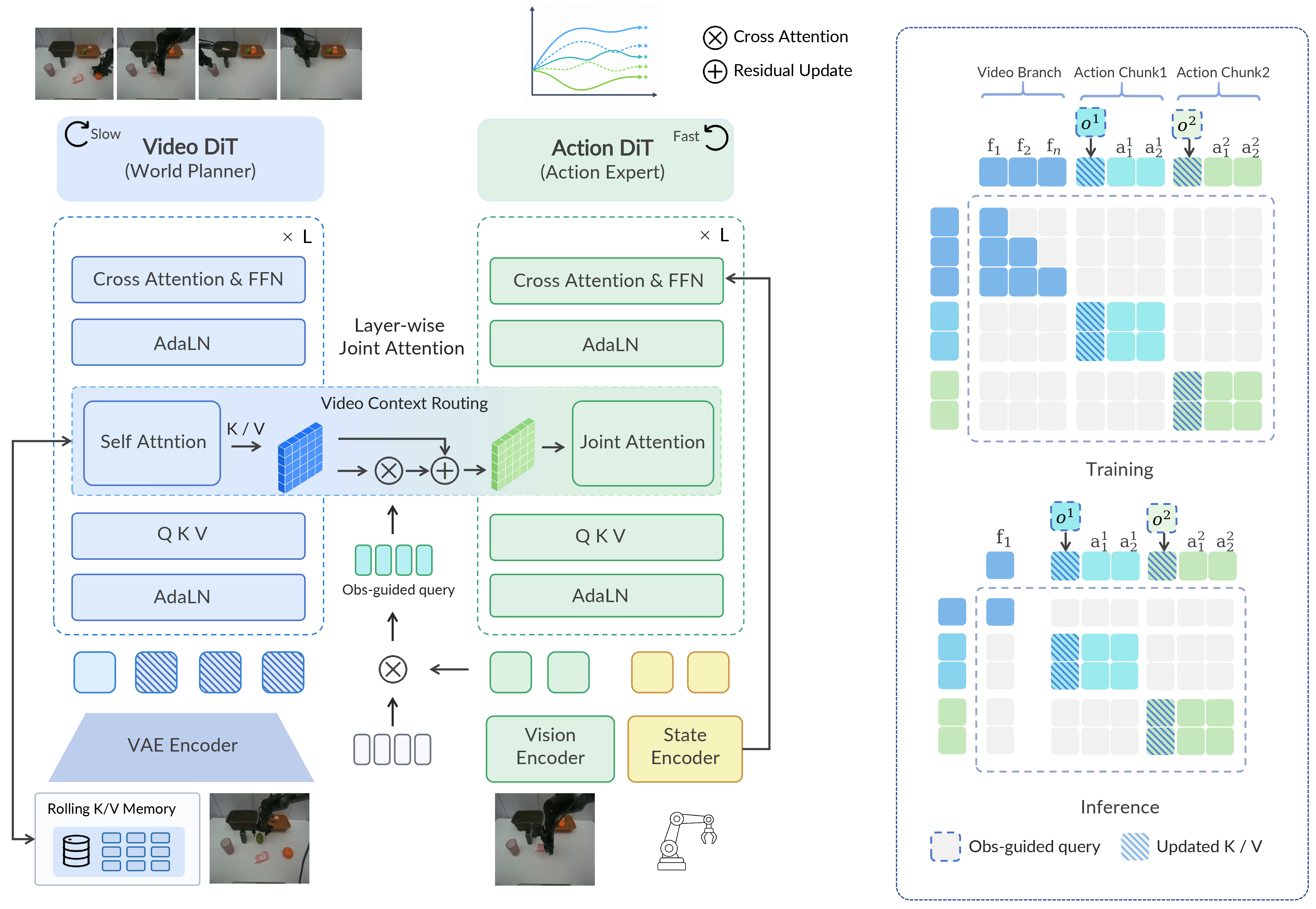
- 핵심 아이디어는 low-frequency Video-DiT world planner가 layerwise K/V planner context를 만들고, high-frequency Action-DiT executor가 이 context를 OVCR(Observation-Guided Video-Context Routing)로 최신 observation에 맞게 route/update한 뒤 action chunk를 denoise하는 것이다.
- 학습은 action chunk와 future video latent에 대한 joint flow matching으로 수행되며, horizon-adaptive offset training을 통해 asynchronous inference에서 생기는 planner-executor phase mismatch에 robust하게 만든다. 여기서 horizon-adaptive는 test-time에 horizon을 동적으로 고르는 의미가 아니라, video planning horizon과 action execution horizon을 분리한 뒤 다양한 phase offset을 학습하는 의미다.
- RoboTwin 2.0에서 92.80% 평균 성공률, real-world 4개 bimanual task에서 78.33% 성공률을 보고하며, AHA-WAM은 24.17 Hz, ODE distillation과 CUDA optimization을 적용한 AHA-WAM-Flash는 56.95 Hz closed-loop action-update frequency를 달성한다.