



GEAR-VLA: Learning Geometry-Aware Action Representations for Generalizable Robotic Manipulation
Qwen2.5-VL 기반 VLA에 latent action token K/V cache-conditioned stop-gradient DiT flow action expert, VGGT 기반 3D spatial encoder, relative end-effector action 기반 embodiment canonicalization을 결합해 unseen object / background shift / pretraining-unseen robot embodiment transfer를 개선하는 geometry-aware manipulation policy
Overview Figure
Summary
- 기존 VLA는 action tokenization, 3D spatial feature, cross-embodiment learning을 각각 다루지만, low-level trajectory token에 overfitting되거나, 3D feature가 VLM semantic space와 어긋나거나, robot-specific prompt/head가 shared policy representation을 오염시키는 문제가 있다.
- 이 논문은 semantically grounded + geometry-aware + embodiment-shareable action representation을 학습하는 것이 real-world manipulation generalization의 핵심이라고 주장한다.
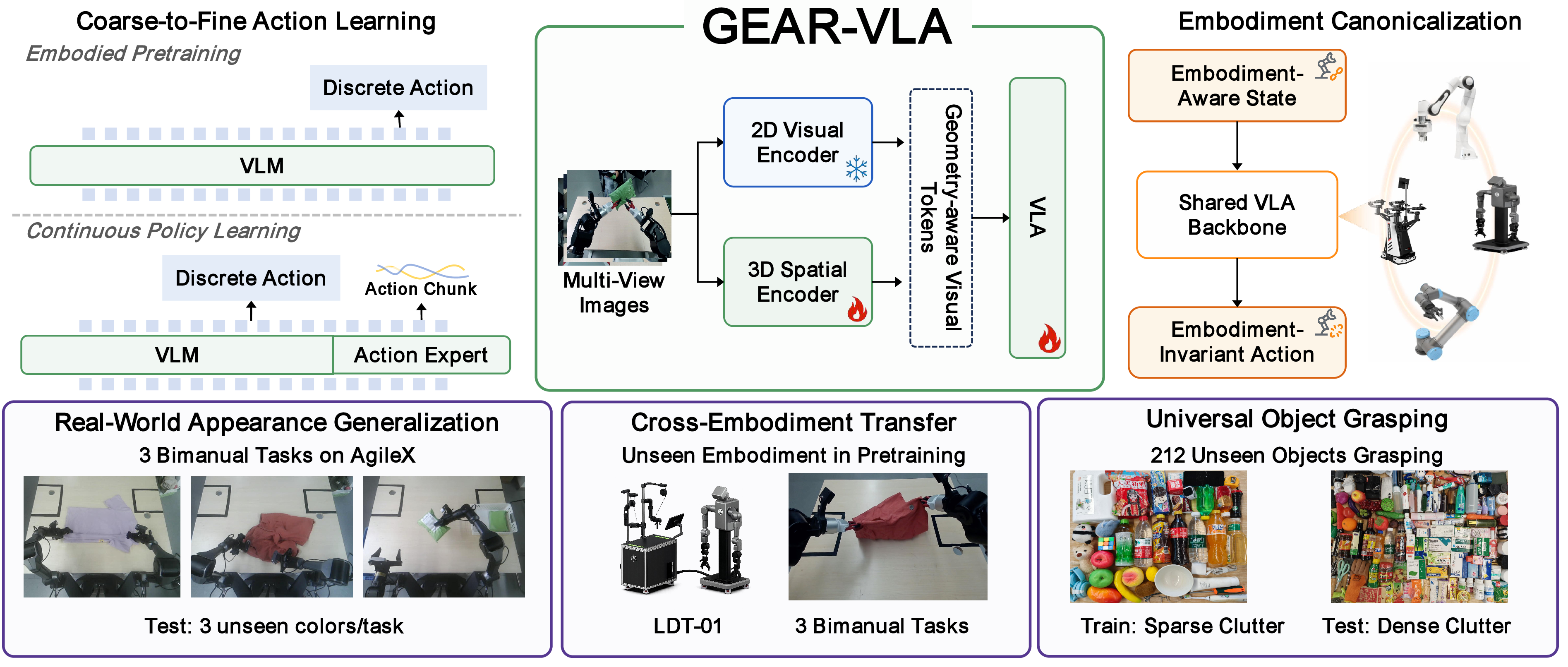
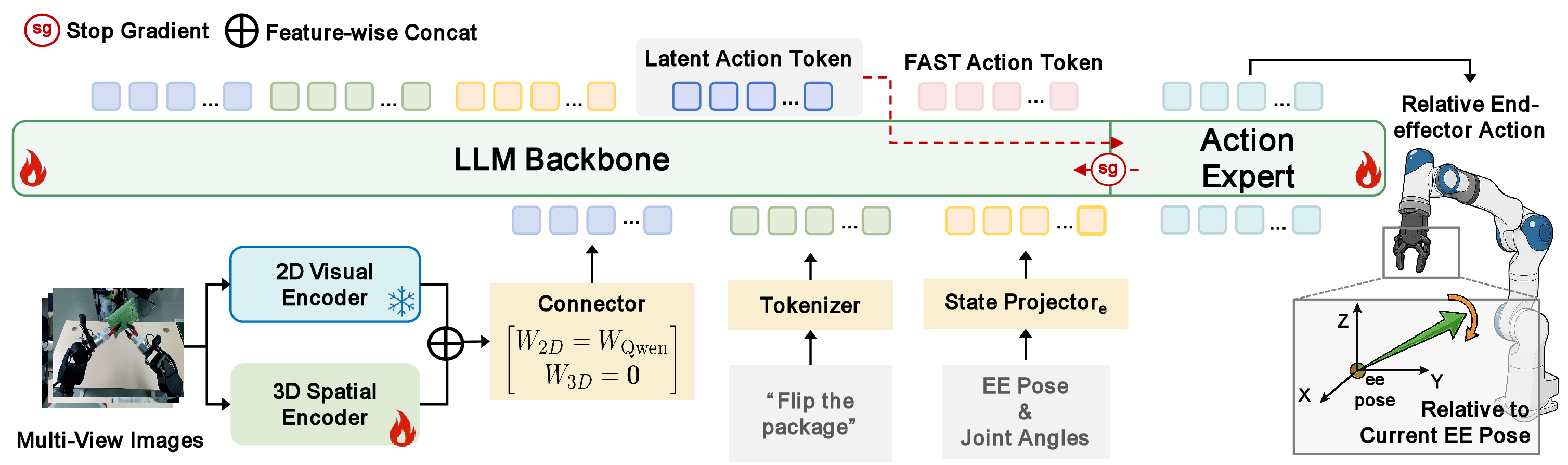
- 핵심 아이디어는 먼저 VLM을 embodied reasoning / FAST-style action token / video-derived latent action ID로 pretrain한 뒤, latent action token의 K/V cache만 DiT-based continuous action expert에 넘기고 stop-gradient를 걸어 continuous action loss가 VLM backbone을 직접 업데이트하지 못하게 하는 것이다.
- 여기에 frozen 2D VLM visual pathway와 trainable VGGT 3D spatial encoder를 zero-initialized connector로 결합하고, robot별 차이는 embodiment-specific state projector와 embodiment-invariant relative end-effector action으로 low-level interface에 가둔다.
- LIBERO 평균 98.7%, zero-shot LIBERO-Plus 88.7%, RoboTwin 2.0 clean/randomized 91.1%/89.9%, AgileX real-world bimanual 85.9%, pretraining-unseen LDT-01 lightweight adaptation 81.0%, 212 unseen object universal grasping 90.1%를 달성한다.