



Efficient-WAM: A 1B-Parameter World-Action Model with Low-Cost Future Imagination
WAM의 미래 영상 예측을 photorealistic video generation이 아니라 action generation을 돕는 저비용 coarse future guidance로 재정의하고, compact video expert + low-resolution future latent + asymmetric video-action denoising으로 약 1B 규모에서 real-world policy inference latency를 약 98 ms/chunk까지 낮춤
Overview Figure
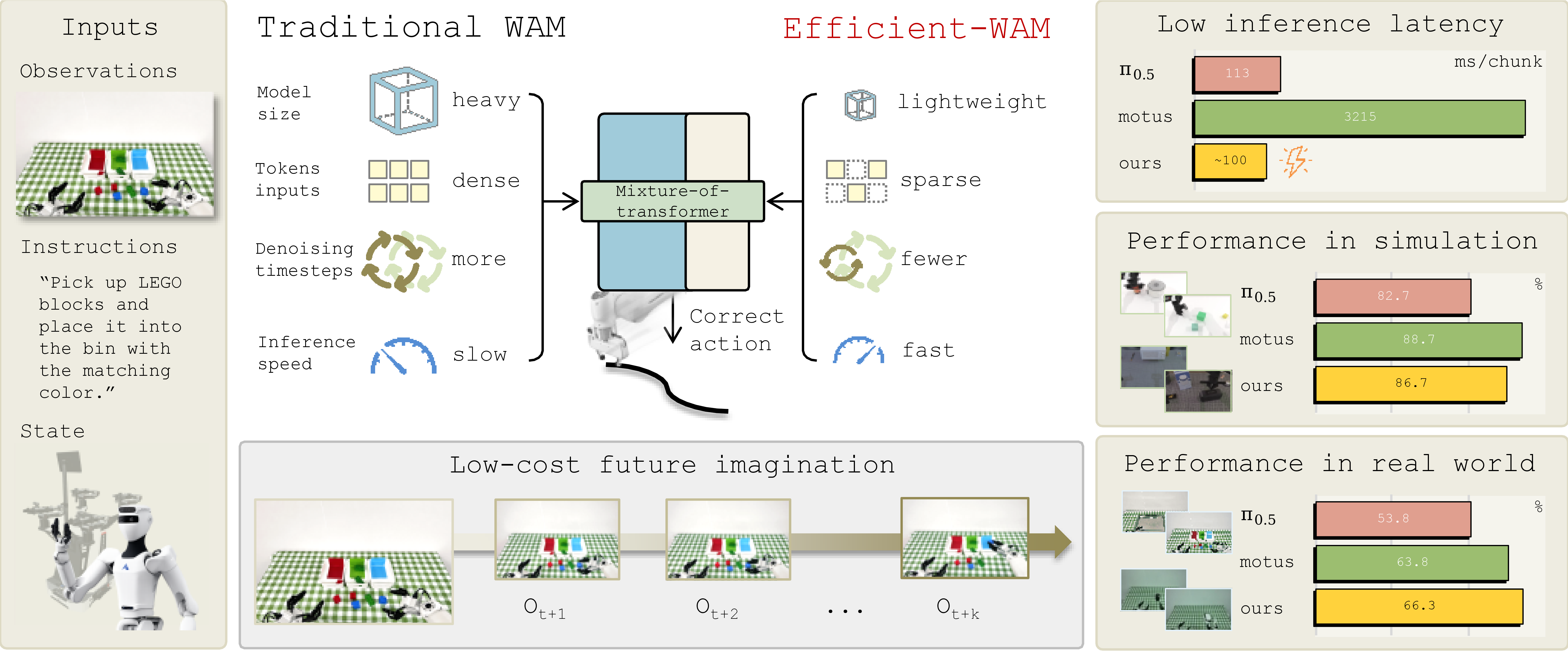
Summary
- 기존 WAM은 future video prediction과 action generation을 결합해 robot control에 world prior를 주입하지만, 대형 video generator, dense visual token, 반복 denoising 때문에 real-time robot deployment가 어렵다.
- 이 논문은 “좋은 action을 위해 photorealistic future video가 꼭 필요한가?”라는 문제를 제기하고, policy가 실제로 필요한 것은 선명한 픽셀이 아니라 task-relevant geometry, motion tendency, contact cue라고 주장한다.
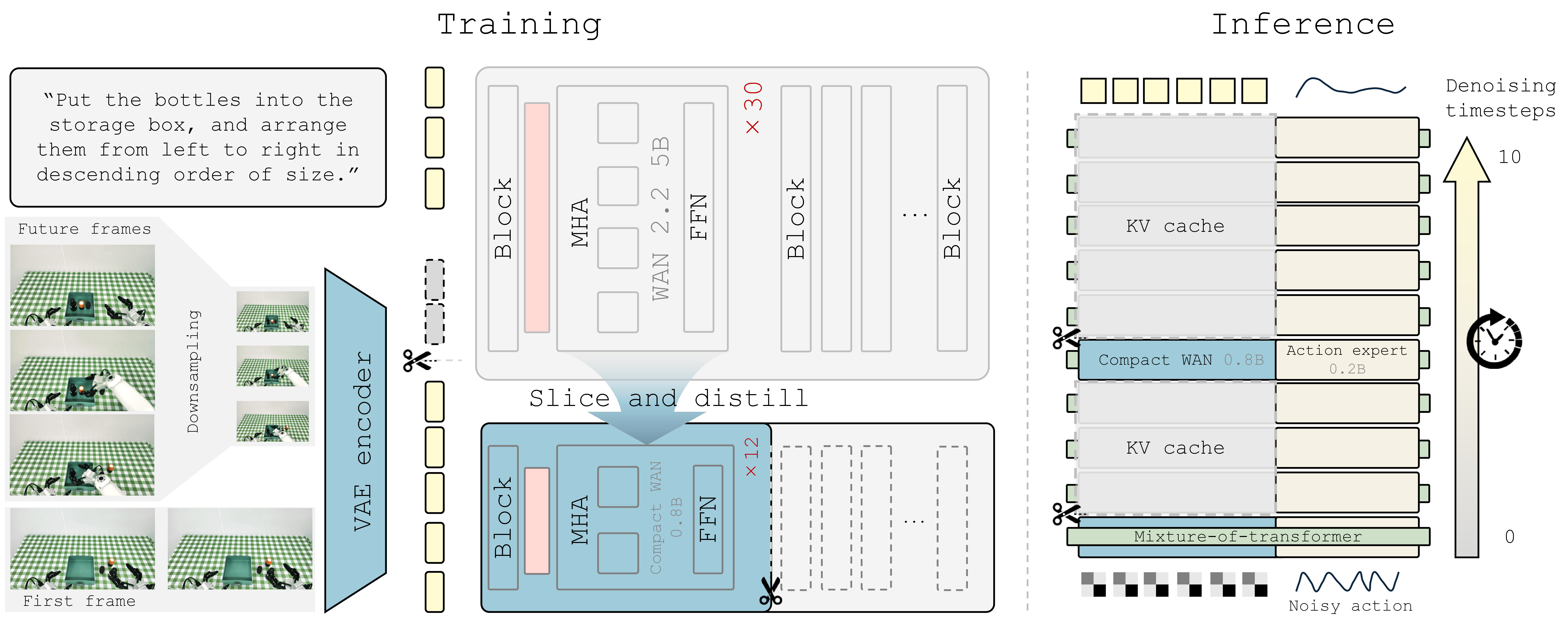
- 핵심 아이디어는 WAN-2.2-5B에서 잘라낸 compact video expert를 teacher-guided distillation으로 만들고, future latent를 저해상도로 만들며, inference 때 video branch는 적은 step만 denoise하고 action branch는 더 많은 step을 쓰는 action-centric future imagination이다.
- 모델은 compact WAN 0.8B video expert와 0.2B action expert가 layer-wise Mixture-of-Transformers(MoT) 방식으로 상호작용하고, conditional flow matching으로 future video latent와 action chunk를 학습한다.
- RoboTwin 2.0에서는 Efficient-WAM이 86.7% clean / 85.7% randomized success를 보이고, Efficient-WAM-RT는 83.1% / 82.0%로 약간 낮아지지만, real-world Astribot S1에서는 66.25% average success와 98 ms/chunk policy-side latency를 달성했다.