



Dynamic Execution Horizon Prediction for Chunk-based Robot Policies
pretrained action-chunking robot policy의 action generator는 완전히 고정하고, 현재 observation과 예측된 action chunk를 보고 “이번에 몇 step을 open-loop로 실행할지”를 PPO로 학습하는 lightweight execution-horizon predictor
Overview Figure
Summary
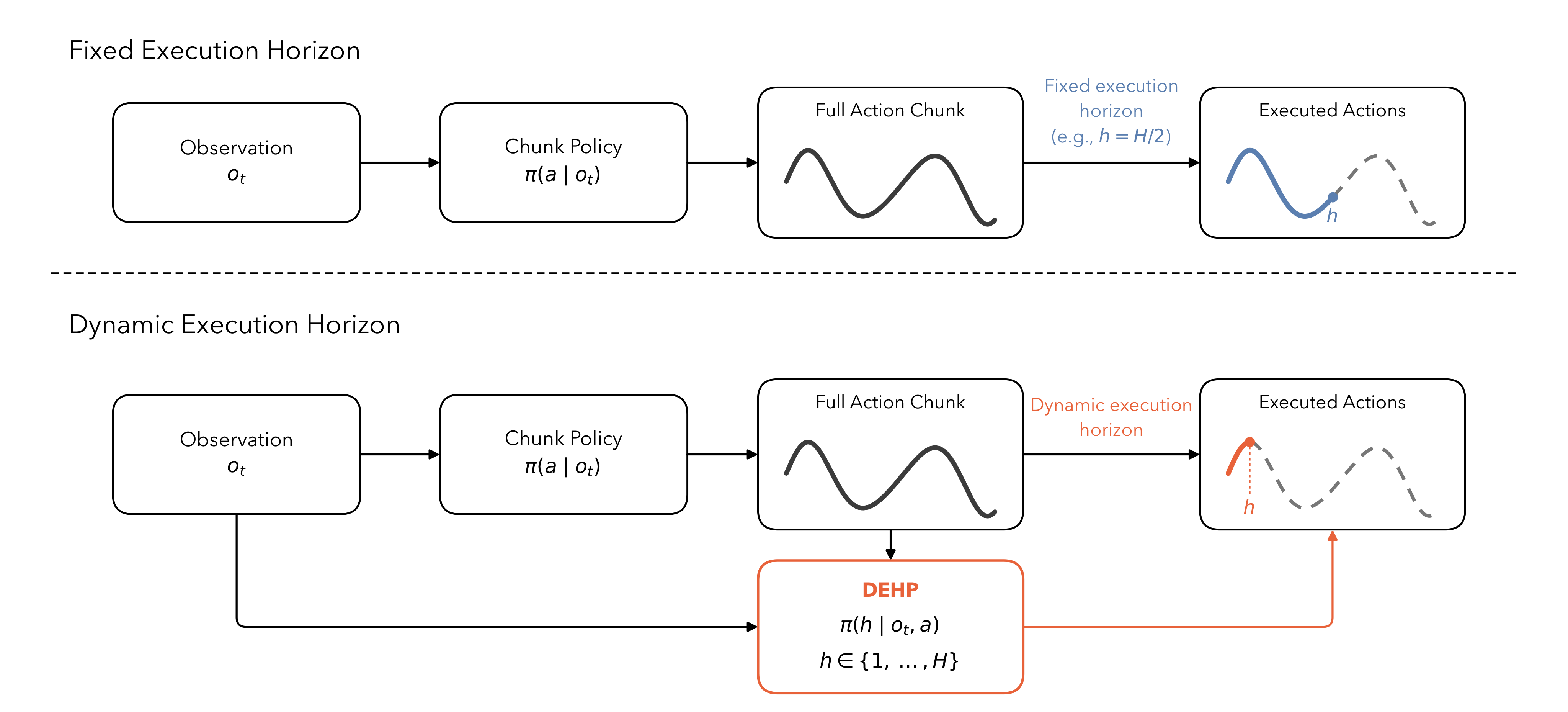
- 기존 chunk-based robot policy는 Diffusion Policy, flow policy, VLA처럼 여러 action을 한 번에 예측하지만, 실제 실행 시에는 고정된 개수의 action만 실행하는 fixed execution horizon에 의존한다.
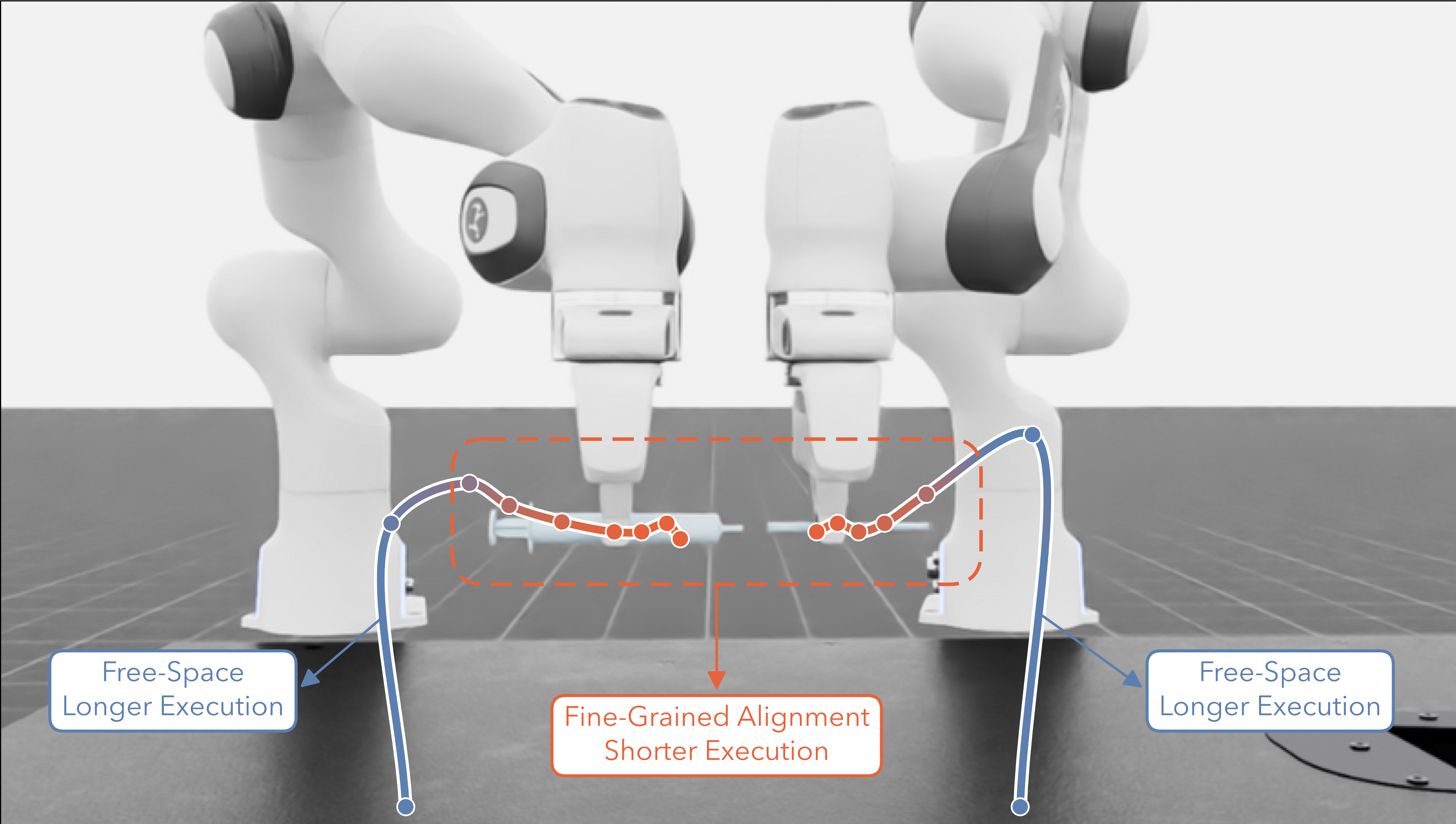
- 이 고정 horizon은 free-space motion에서는 효율적일 수 있지만, grasp alignment, insertion, contact-rich manipulation처럼 feedback이 중요한 단계에서는 open-loop 실행이 길어져 작은 오차가 누적되는 문제가 있다.
- 이 논문은 execution horizon 자체를 state-dependent decision으로 보고, pretrained base chunk policy가 만든 full action chunk와 현재 observation을 입력으로 받아 실행 길이 $h \in \{1, \dots, H\}$를 선택하는 Dynamic Execution Horizon Prediction, DEHP를 제안한다.
- 학습은 base policy $\pi_{\text{act}}$를 frozen으로 유지한 채, categorical horizon policy $\pi_{\text{len}}(h | s, \mathbf{a}_{1:H})$와 state-value critic만 online PPO로 학습하며, variable horizon rollout을 semi-Markov decision process로 정식화한다.
- 실험에서는 state-based Diffusion Policy를 base policy로 사용하고, multi-stage peg insertion, bimanual needle-syringe insertion, FurnitureBench one-leg / round-table assembly에서 tuned fixed-horizon baseline보다 높은 success rate를 보였으며, learned horizon이 free-space에서는 길고 alignment/insertion에서는 짧아지는 해석 가능한 패턴을 보였다.