



Elastic Queries Reinforcement Learning: Self-Aware Policy Execution for VLA Models
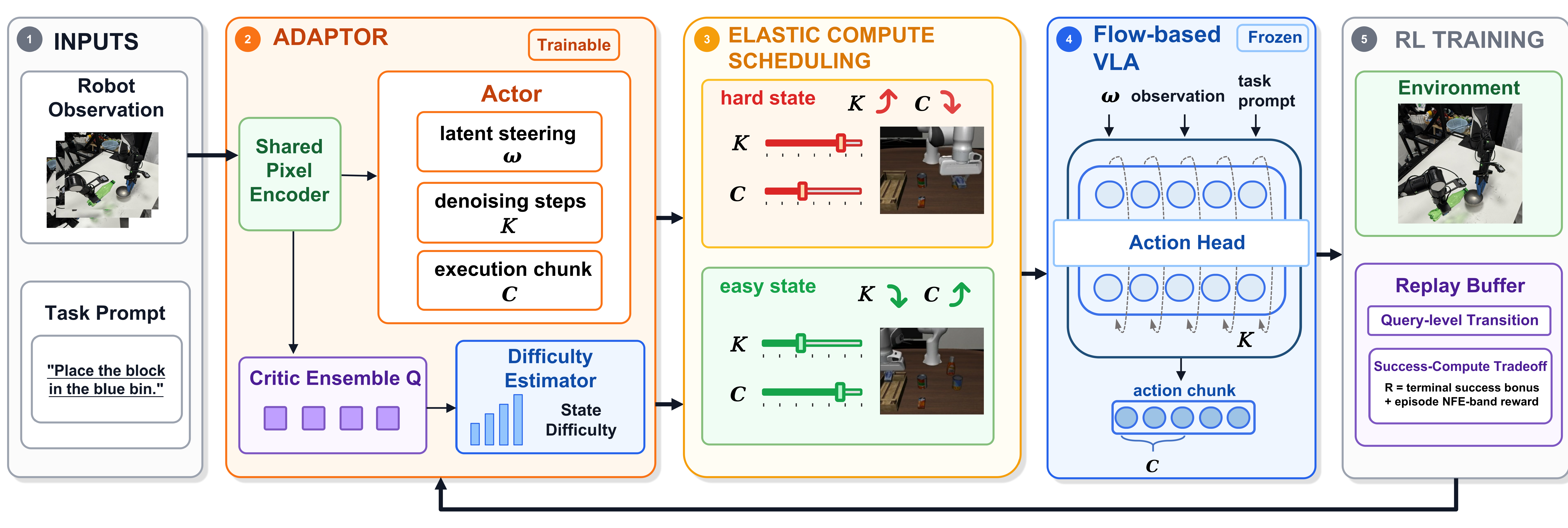
frozen flow-based VLA는 그대로 둔 채, lightweight RL adaptor가 매 query마다 latent steering w, denoising steps K, execution chunk length C를 동적으로 선택해 hard state에서는 더 많은 compute와 잦은 replanning을, easy state에서는 낮은 compute와 긴 open-loop execution을 수행하도록 만드는 elastic VLA execution framework
Overview Figure
Summary
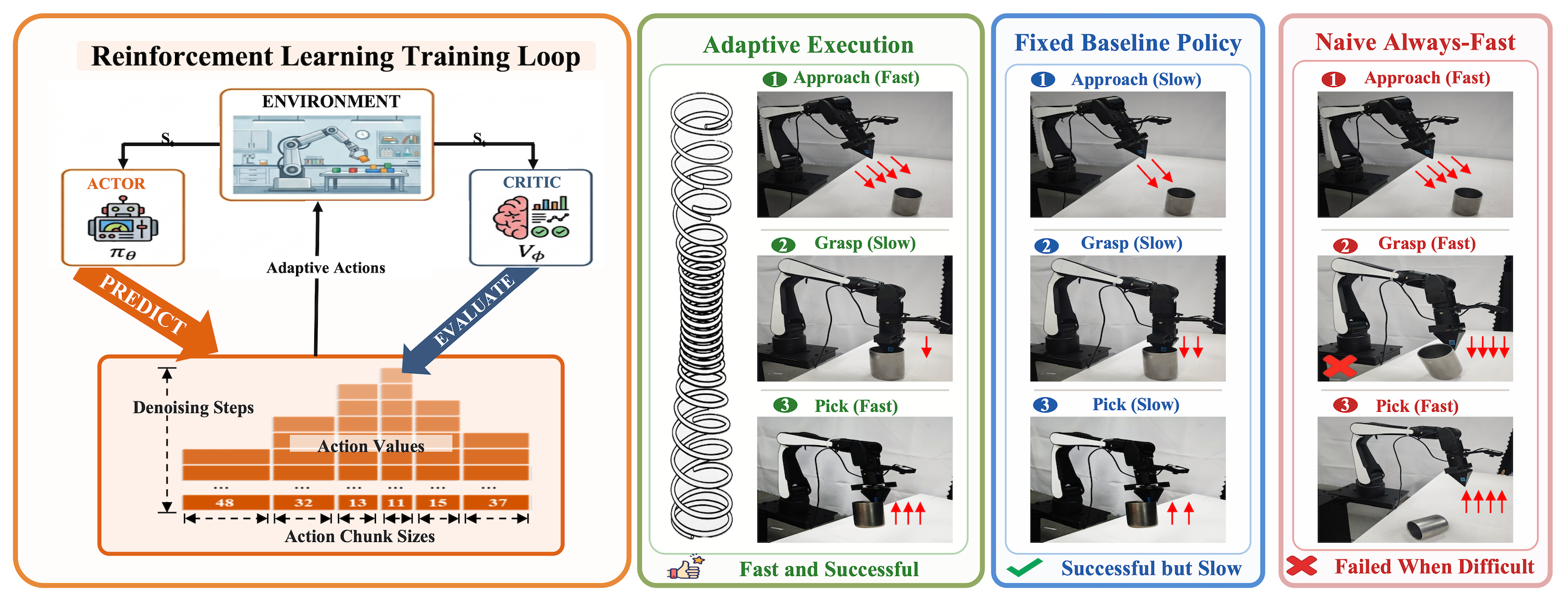
- 기존 VLA / diffusion-policy / flow-policy 기반 robot policy는 보통 매 query마다 고정된 denoising step과 고정된 action chunk length를 사용하기 때문에, free-space motion처럼 쉬운 구간과 contact-rich alignment처럼 어려운 구간을 같은 compute와 같은 feedback 주기로 처리한다.
- 이 논문은 이러한 fixed inference / fixed replanning schedule이 manipulation의 uneven difficulty와 맞지 않는다고 보고, VLA execution 자체를 state-dependent resource allocation problem으로 재정의한다.
- 핵심 아이디어는 frozen $\pi_0$ VLA policy 위에 lightweight RL adaptor를 얹어, 각 query에서 latent steering variable $w$, denoising budget $K$, chunk execution length $C$를 joint latent-schedule action으로 선택하는 것이다.
- 이를 안정적으로 학습하기 위해 critic ensemble disagreement에서 state difficulty signal을 만들고, variable-length chunk execution을 query-level macro-action RL로 처리하며, chunk-dependent discounting과 episode-level amortized NFE budget을 사용한다.
- 실험에서는 LIBERO와 ALOHA simulation에서 success / success AUC를 유지하거나 개선하면서 relative NFE를 줄였고, real-robot offline 평균에서도 DSRL 대비 success를 0.813→0.838로 소폭 높이면서 relative NFE를 0.500→0.338, trajectory time을 7.15→6.00으로 줄였다.