



ReactVLA: Fast and Lightweight Reactive Robot Manipulation via Improved Mean Flow Action Generation
diffusion / flow 기반 VLA policy의 inference latency 병목을 줄이기 위해, action generation을 improved Mean Flow(iMF) 기반 one-to-few-step continuous action chunk generation으로 바꾸고 Attention Residuals(AttnRes) Transformer를 결합한 low-latency reactive robot manipulation policy
Overview Figure
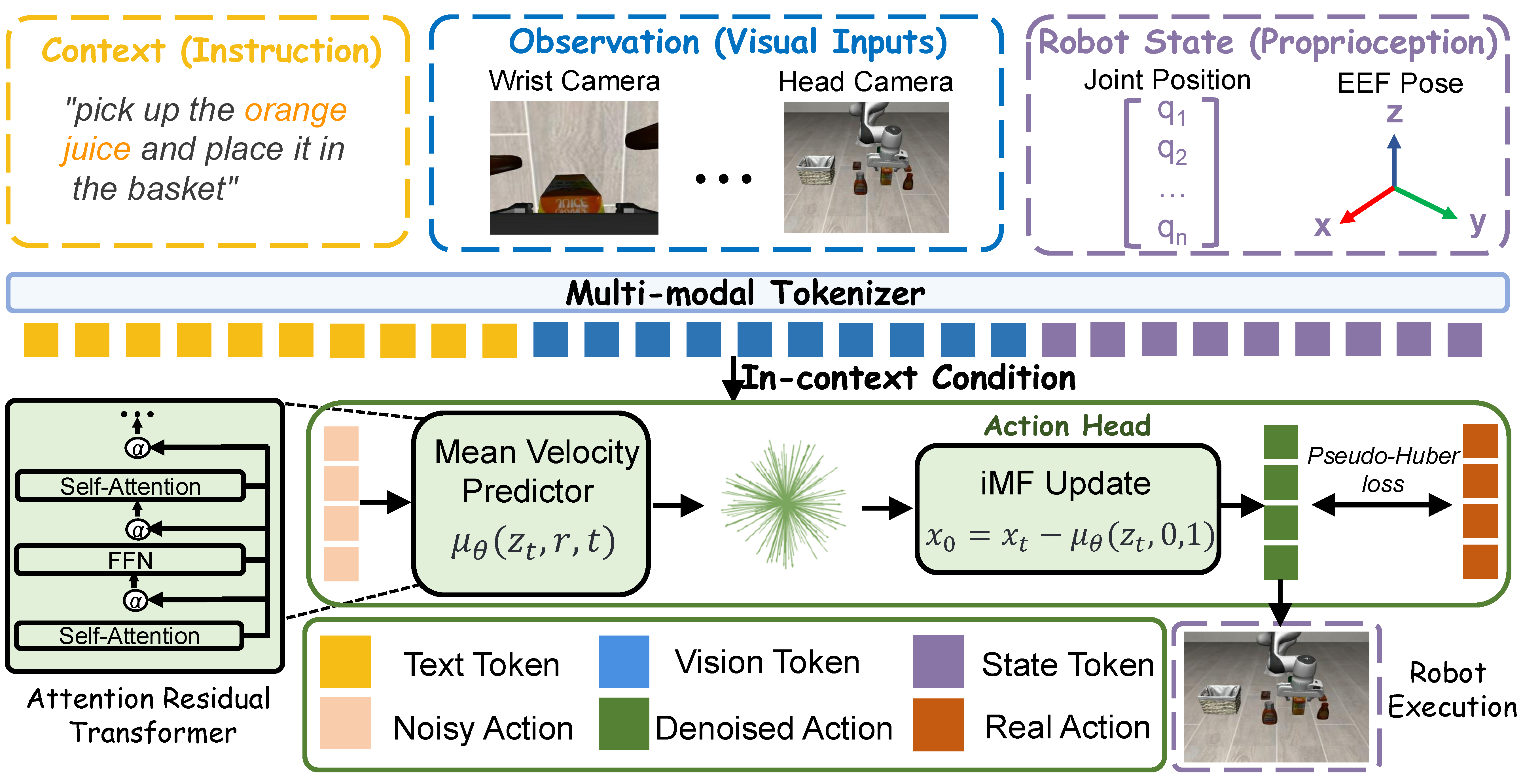
Summary
- 기존 diffusion-based VLA / visuomotor policy는 expressive하고 multimodal한 action distribution을 잘 모델링하지만, deployment 시 여러 번의 denoising / integration step이 필요해서 closed-loop robot control의 latency bottleneck이 크다.
- ReactVLA는 이 문제를 reactive manipulation 관점에서 보고, action quality를 유지하면서 inference evaluation 수를 1~수 회로 줄이는 것을 목표로 한다.
- 핵심 아이디어는 instantaneous velocity field를 따라 작은 step으로 적분하는 대신, finite interval 평균 transport velocity를 예측하는 improved Mean Flow(iMF) action generator를 사용하는 것이다.
- 여기에 low-step generation에서 각 forward pass가 더 많은 표현력을 가져야 한다는 점을 고려해, fixed residual accumulation 대신 layer-depth 방향으로 유용한 intermediate representation을 선택적으로 가져오는 Attention Residuals(AttnRes)를 policy transformer에 넣는다.
- 실험적으로 LIBERO, RoboIMI, Diana 7 real robot에서 SmolVLA, $\pi_{0}$, Diffusion Policy 등과 비교해 비슷하거나 더 높은 success / reward를 훨씬 낮은 latency로 달성하며, LIBERO 평균 88.0%, 18.3 ms, RoboIMI 15.1 ms, real-world 38.6 ms latency를 보고한다.
Key Components
-
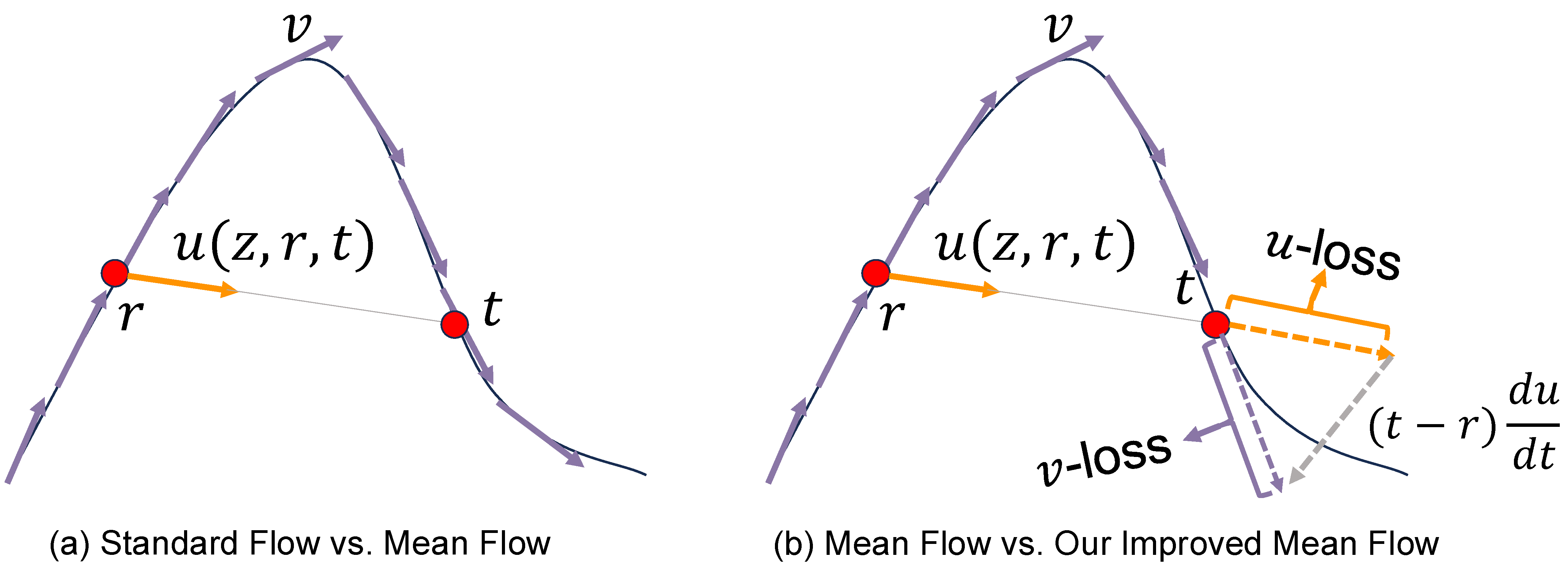
Mean Flow Standard Flow Matching은 noisy action trajectory $z_t$의 각 시점에서 instantaneous velocity field $v(z_t,t)$를 예측하고, inference 때 여러 작은 step으로 ODE를 적분한다. 반면 Mean Flow는 구간 $[r,t]$ 전체를 한 번에 이동시키는 finite-interval average transport velocity
\[u(z_t,r,t)=\frac{1}{t-r}\int_r^t v(z_\tau,\tau)d\tau\]를 직접 예측한다. 직관적으로는 “지금 순간의 작은 이동 방향”이 아니라 “noise action에서 target action으로 크게 이동하기 위한 평균 방향”을 배우는 방식이다. 그래서 diffusion / flow policy의 expensive multi-step sampling을 one-to-few-step generation으로 줄이기 좋다.
-
Improved Mean Flow (iMF) Mean Flow를 그대로 학습하면 conditional average transport와 underlying instantaneous vector field 사이에 path inconsistency가 생길 수 있다. iMF는 이를 완화하기 위해 Jacobian-Vector Product(JVP) correction을 넣어 corrected velocity prediction
\[V_\theta(z_t,r,t) = u_\theta(z_t,r,t) + (t-r)\mathrm{JVP}_{\text{sg}}(u_\theta;v_\theta)\]를 학습한다. 여기서 $v_\theta(z_t,t)=u_\theta(z_t,t,t)$는 같은 network에서 얻은 instantaneous velocity prediction이고, $sg$는 stop-gradient를 의미한다. 중요한 점은 JVP correction은 주로 training objective의 consistency / stability를 위한 장치이고, inference에서는 learned mean-flow predictor를 이용해 $1.0 \rightarrow 0.5 \rightarrow 0.0$ 같은 few-step update로 action chunk를 생성한다는 것이다.
-
Attention Residuals (AttnRes) Standard PreNorm Transformer의 residual connection은 이전 layer output들을 fixed unit weight로 계속 더한다. 깊은 multimodal policy transformer에서는 이 방식이 vision / language / proprioception feature를 점점 희석시키는 representation dilution을 만들 수 있다. AttnRes는 이전 layer representation들을 cache하고, 현재 layer가 softmax routing weight
\[\alpha_{i\rightarrow l} = \frac{\exp(w_l^\top \mathrm{RMSNorm}(v_i))} {\sum_j \exp(w_l^\top \mathrm{RMSNorm}(v_j))}\]로 필요한 intermediate feature를 선택적으로 retrieve한다. ReactVLA에서 AttnRes가 중요한 이유는 low-step action generation에서는 한 번의 policy evaluation이 충분히 강한 multimodal context를 보존해야 하기 때문이다.