



Geometric Action Model for Robot Policy Learning
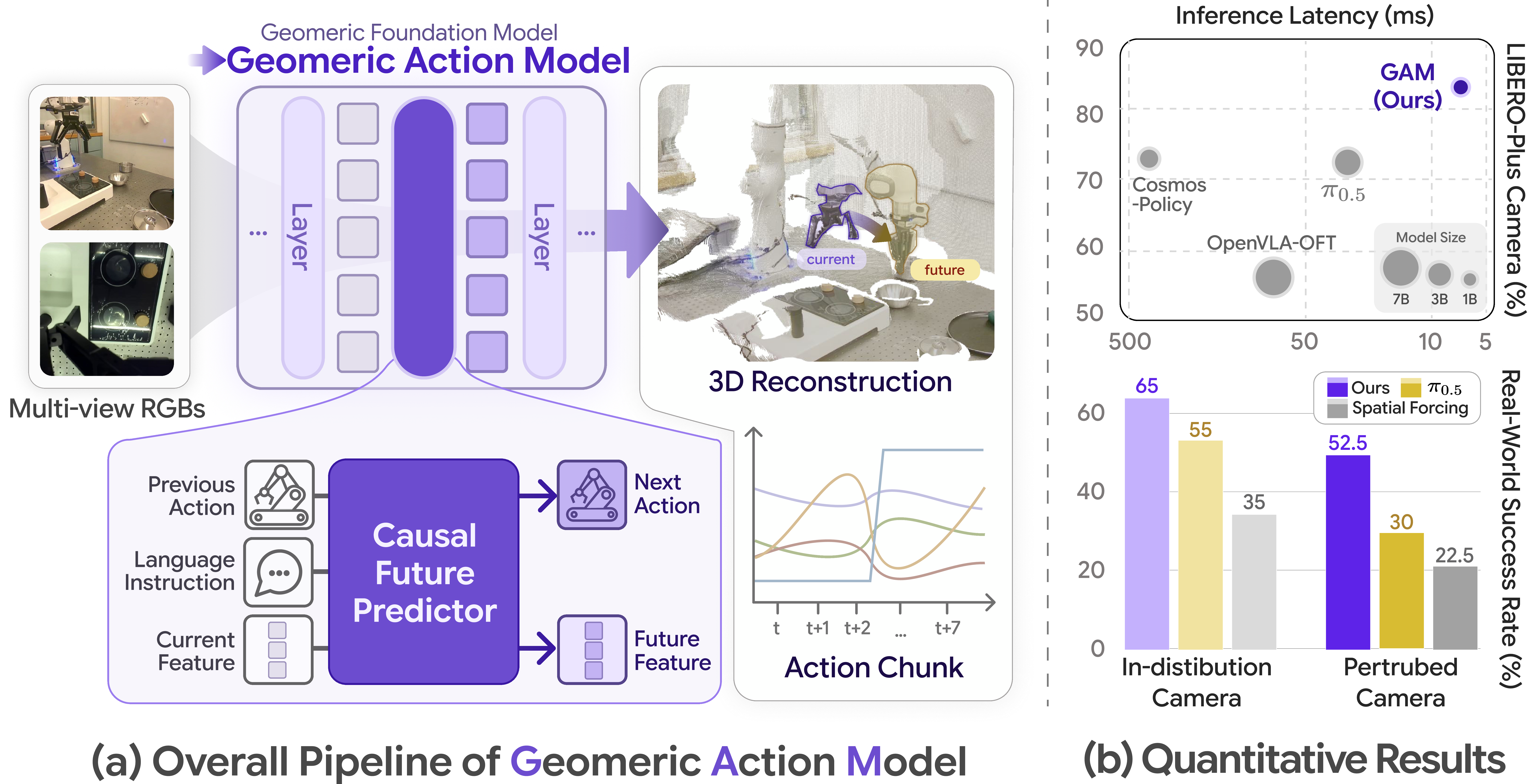
pretrained Geometric Foundation Model(GFM)을 단순 feature extractor가 아니라 robot policy backbone 자체로 재활용해, GFM latent space 안에서 future geometry와 action chunk를 함께 예측하는 geometry-grounded World-Action Policy
Overview Figure
Summary
- 기존 VLA와 video WAM은 semantic prior 또는 temporal prior는 강하지만, 주로 2D image frame 또는 2D-derived latent space에서 작동하기 때문에 depth, scale, occlusion 같은 3D geometry가 action decoder에 implicit하게만 남는다는 문제가 있다.
- 이 논문은 contact-rich manipulation에서 필요한 3D physical reasoning을 robot policy 내부에 더 직접적으로 주입하는 문제를 다룬다.
- 핵심 아이디어는 pretrained Geometric Foundation Model(GFM)을 중간 layer에서 split하고, 그 사이에 causal future predictor를 삽입해 language, proprioception, previous action을 조건으로 future geometric latent token과 action token을 함께 autoregressive하게 예측하는 것이다.
- 예측된 future token은 remaining GFM deep blocks를 통과하면서 future depth와 executable action chunk로 decode되며, action loss, future-feature loss, future-depth loss로 causal future predictor, action head, trainable GFM deep blocks를 함께 학습한다.
- GAM은 LIBERO-Plus 85.5% success rate, camera perturbation 83.1%, 1.4B total parameters, CUDA Graph deployment 기준 6.9 ms model-only latency를 달성하며, 특히 camera-viewpoint robustness에서 기존 VLA/WAM 대비 강한 결과를 보인다.