



Acting While Understanding: Asynchronous Semantic-Action Decoupling for Real-Time Vision-Language-Action Models
VLA 내부 semantic-action interface를 slow semantic understanding과 fast action generation으로 분리하고, stale semantic cache를 action history와 delay-aware training으로 보완해 full VLA를 control rate로 돌리지 않는 high-frequency state-feedback VLA deployment framework
Overview Figure
Summary
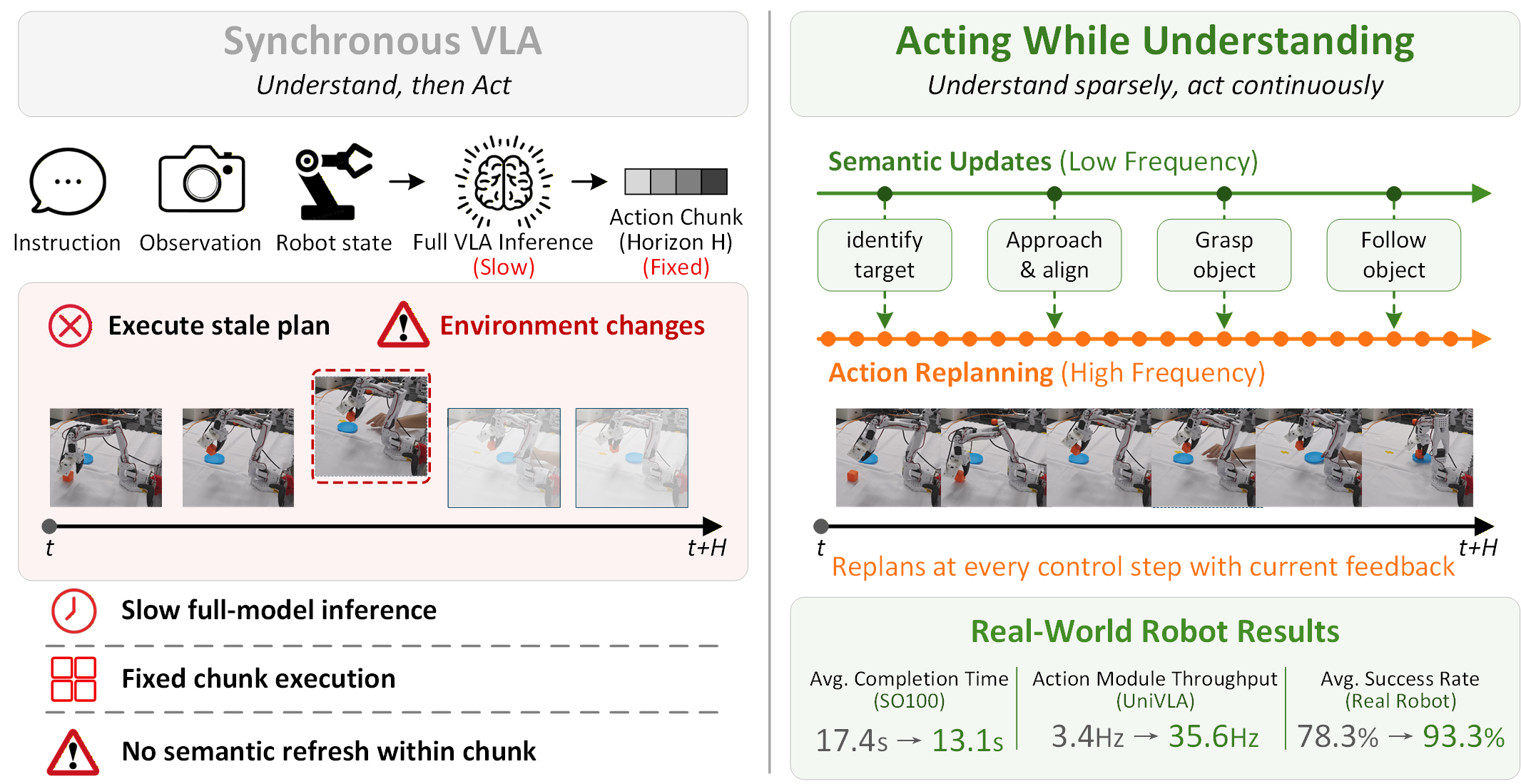
- 기존 Vision-Language-Action model, 즉 VLA는 image / language / robot state를 함께 사용해 강한 task understanding과 generalization을 보이지만, full vision-language backbone inference가 무거워 real robot의 low-latency, high-frequency closed-loop control에 직접 쓰기 어렵다.
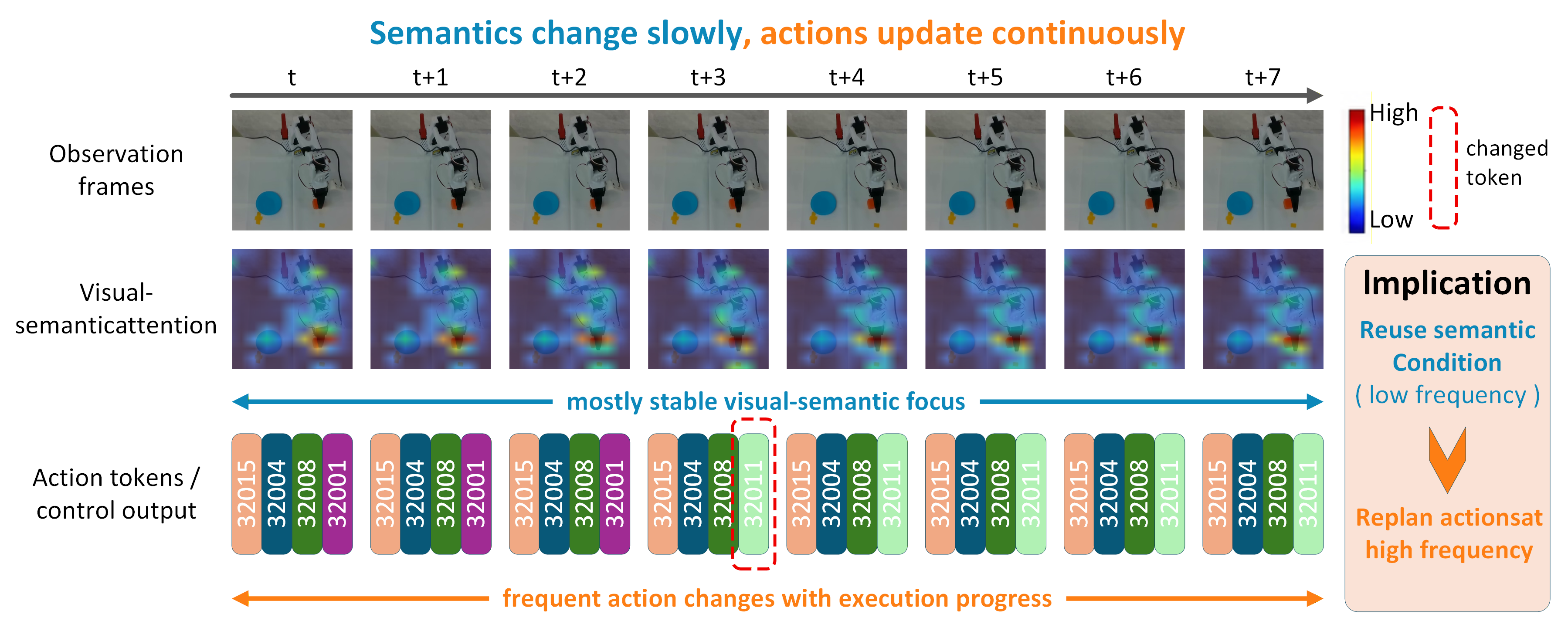
- 기존 action chunking은 한 번의 full inference로 여러 step의 action을 생성해 실행 주파수 문제를 완화하지만, chunk 실행 중 semantic judgment가 고정되어 environment change나 execution progress를 빠르게 반영하지 못한다.
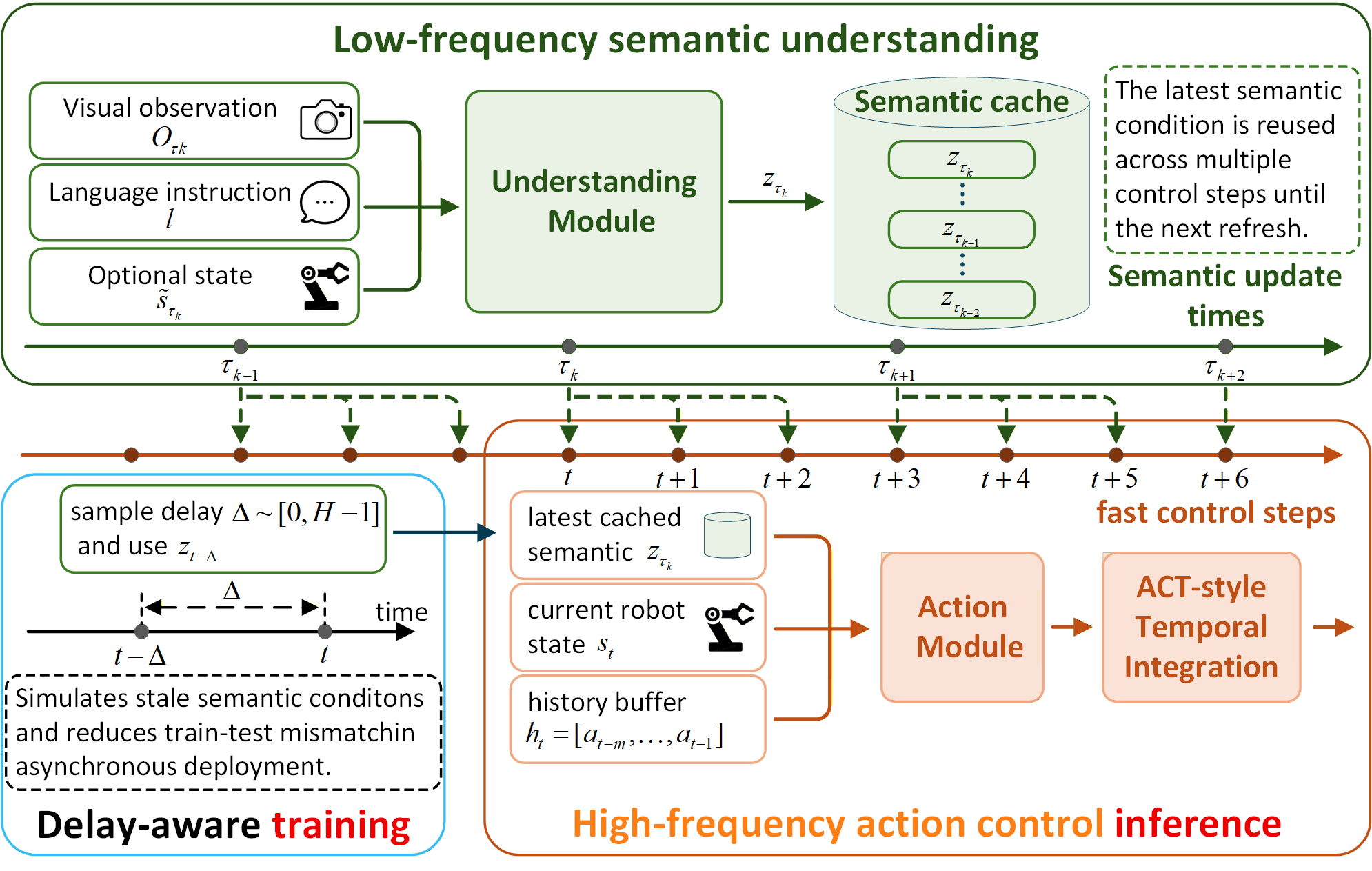
- 이 논문은 VLA 내부의 semantic-action interface를 기준으로 low-frequency understanding module과 high-frequency action module을 분리하고, understanding module이 만든 reusable semantic condition을 cache로 저장해 action module이 매 control step마다 재사용하게 한다.
- stale semantics 때문에 생기는 temporal mismatch는 historical action conditioning과 time-misalignment training으로 완화하며, UniVLA에서는 last-layer VLM hidden state를, $\pi_{0.5}$에서는 vision-language-conditioned prefix KV-cache를 reusable semantic condition으로 사용한다.
- LIBERO와 real robot 실험에서 UniVLA 기준 synchronous full-model server-side throughput은 3.4 Hz였고, UniVLA-Async의 action-side server throughput은 35.6 Hz까지 증가했다. 또한 SO100 weighted completion time은 17.4 s에서 13.1 s로 줄었고, real robot 평균 success rate도 UniVLA 78.3%에서 UniVLA-Async 93.3%로 개선되었다.