



ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
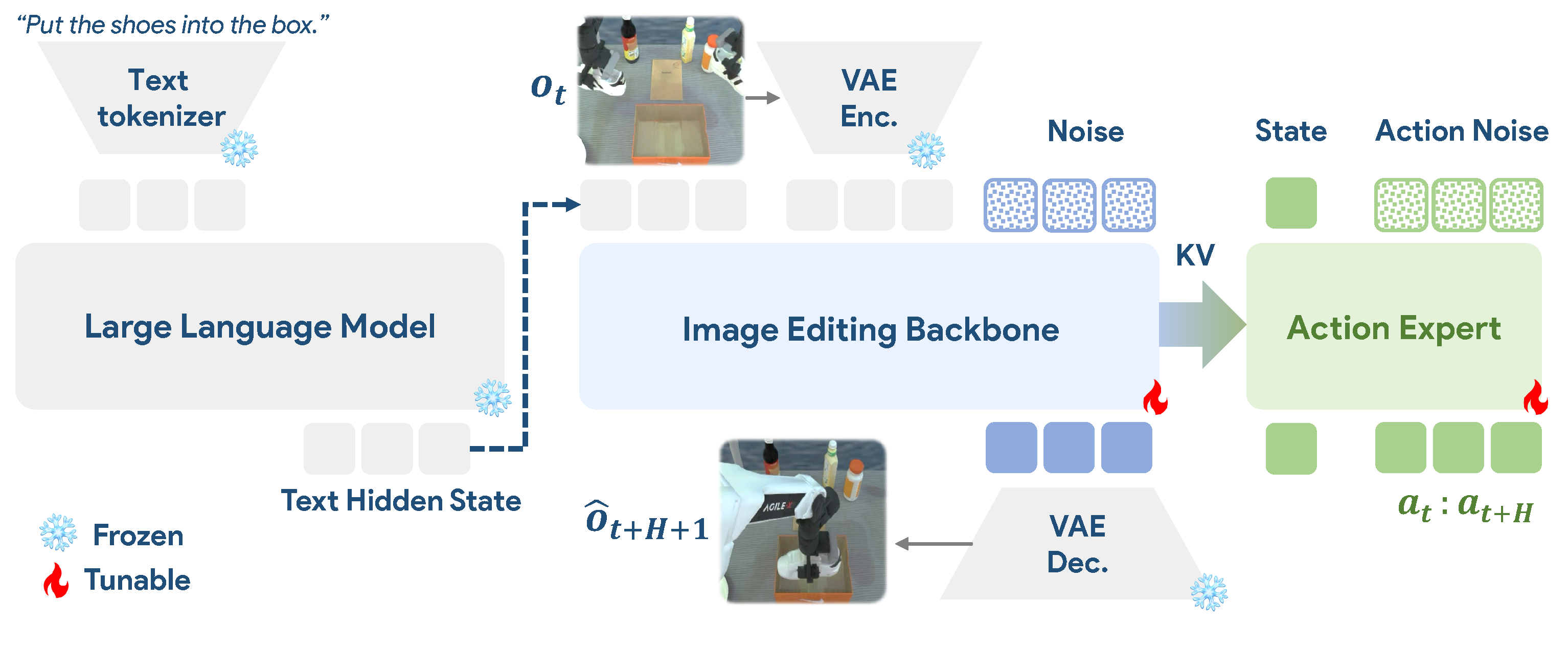
pretrained image-editing model을 robot policy backbone으로 fine-tuning하고, future video를 생성하는 대신 single future endpoint를 학습할 때 형성되는 layer-wise KV cache를 flow-matching Action Expert에 전달하여 action chunk를 생성하는 경량 WAM
Overview Figure
Summary
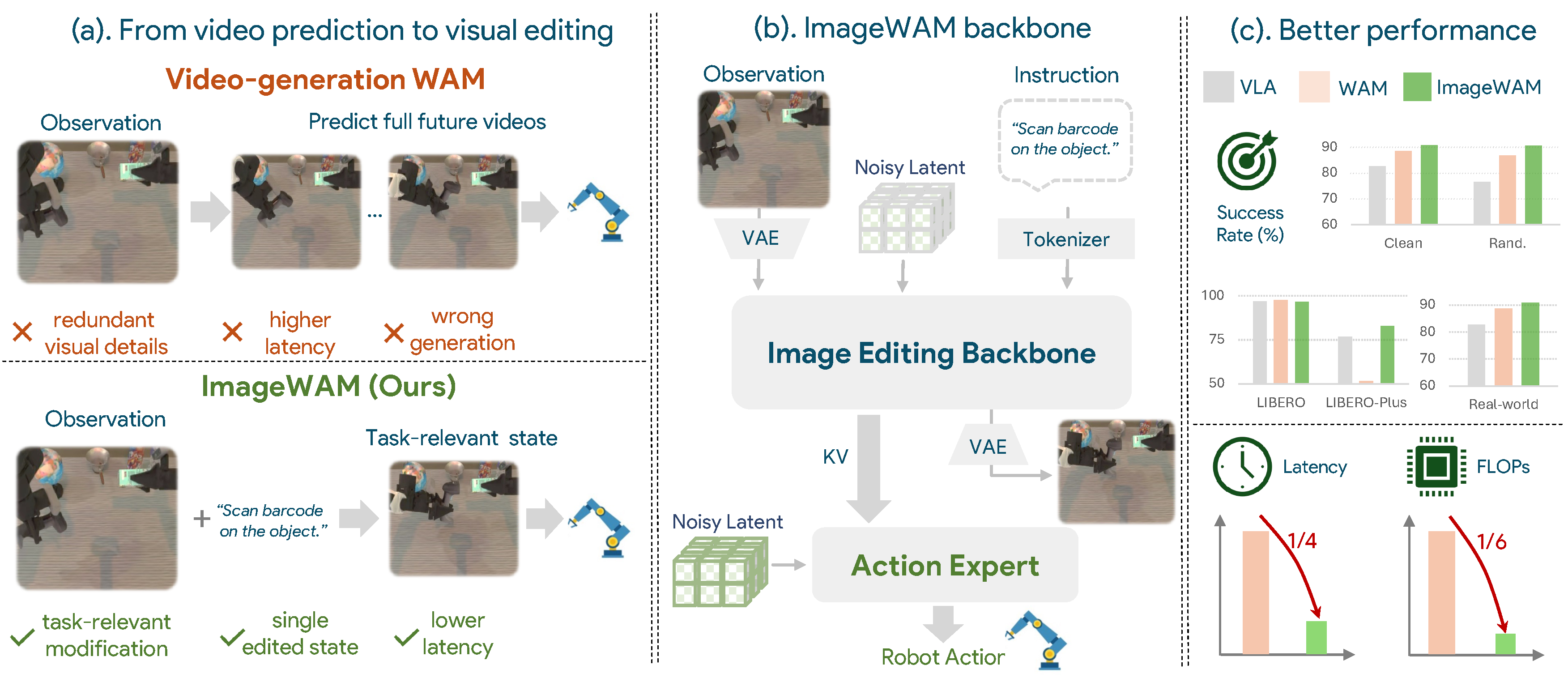
- 기존 video-generation WAM은 다수의 future frame token을 처리하므로 느리고, 행동과 무관한 appearance·background·temporal detail까지 모델링하며, 잘못 생성된 미래가 action prediction을 mislead할 수 있다.
- 이 논문은 robot policy에서 정말 필요한 것이 photorealistic future video인지, 아니면 instruction에 따라 현재 장면에서 무엇이 변해야 하는지를 나타내는 compact representation인지 묻는다.
- 핵심 아이디어는 pretrained image-editing model을 현재 observation에서 task-consistent endpoint로의 instruction-guided visual transformation model로 사용하고, 그 내부 KV cache를 action conditioning으로 재활용하는 것이다.
- VLM/LLM과 VAE는 고정하고 image diffusion branch와 flow-matching Action Expert를 joint training하며, inference에서는 최종 edited image를 decode하지 않고 고정된 editing timestep에서 한 번의 visual forward로 cache만 얻는다.
- ImageWAM은 RoboTwin random 93.56%, LIBERO 98.4%, LIBERO-Plus 83.1%, real robot 84.5%를 기록했고, full-video FastWAM-IDM 대비 latency와 FLOPs를 각각 약 4.1배와 6.5배 줄였다.