



Start Right, Arrive Right: Asynchronous Execution via Initial Noise Selection
frozen flow-matching robot policy의 initial action noise를 backward ODE inversion과 repainting으로 조정하여, 이미 실행된 action prefix와 새 action chunk를 gradient·retraining 없이 연속적으로 연결하는 asynchronous inference method
Overview Figure
Summary
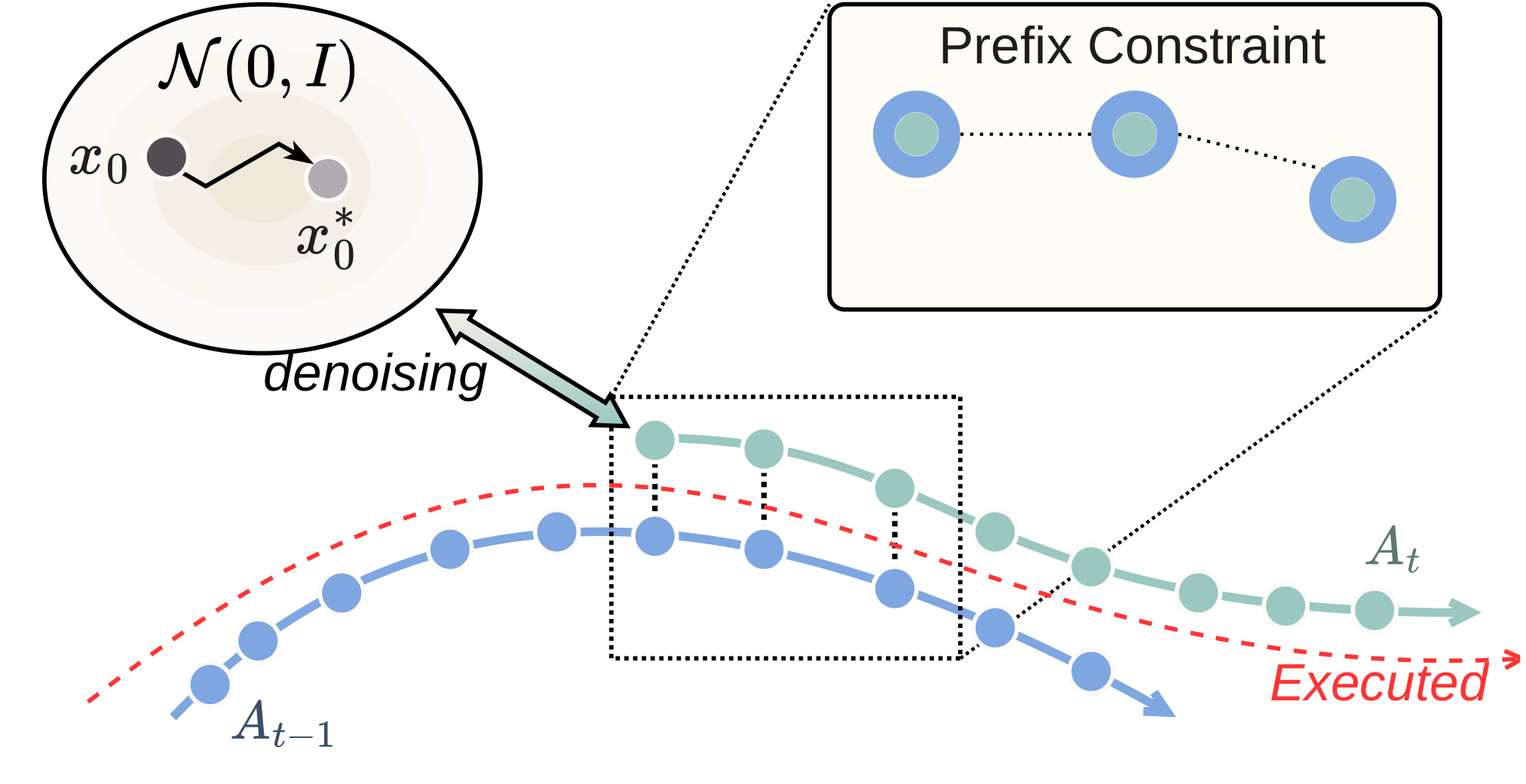
- Flow-based VLA가 여러 denoising step으로 action chunk를 생성하는 동안 로봇이 이전 chunk를 계속 실행하면, 새 chunk의 시간적으로 이미 지나간 prefix가 실제 실행된 action과 달라져 chunk boundary에서 급격한 command jump가 발생한다.
- 이 논문은 policy retraining이나 deployment-time gradient guidance 없이 이 prefix constraint를 만족시키는 것을 목표로 한다.
- 핵심 아이디어는 optimal-transport flow matching의 approximate locality를 이용하여, 원하는 action prefix를 역으로 생성하는 initial noise prefix를 ODE inversion으로 찾는 것이다.
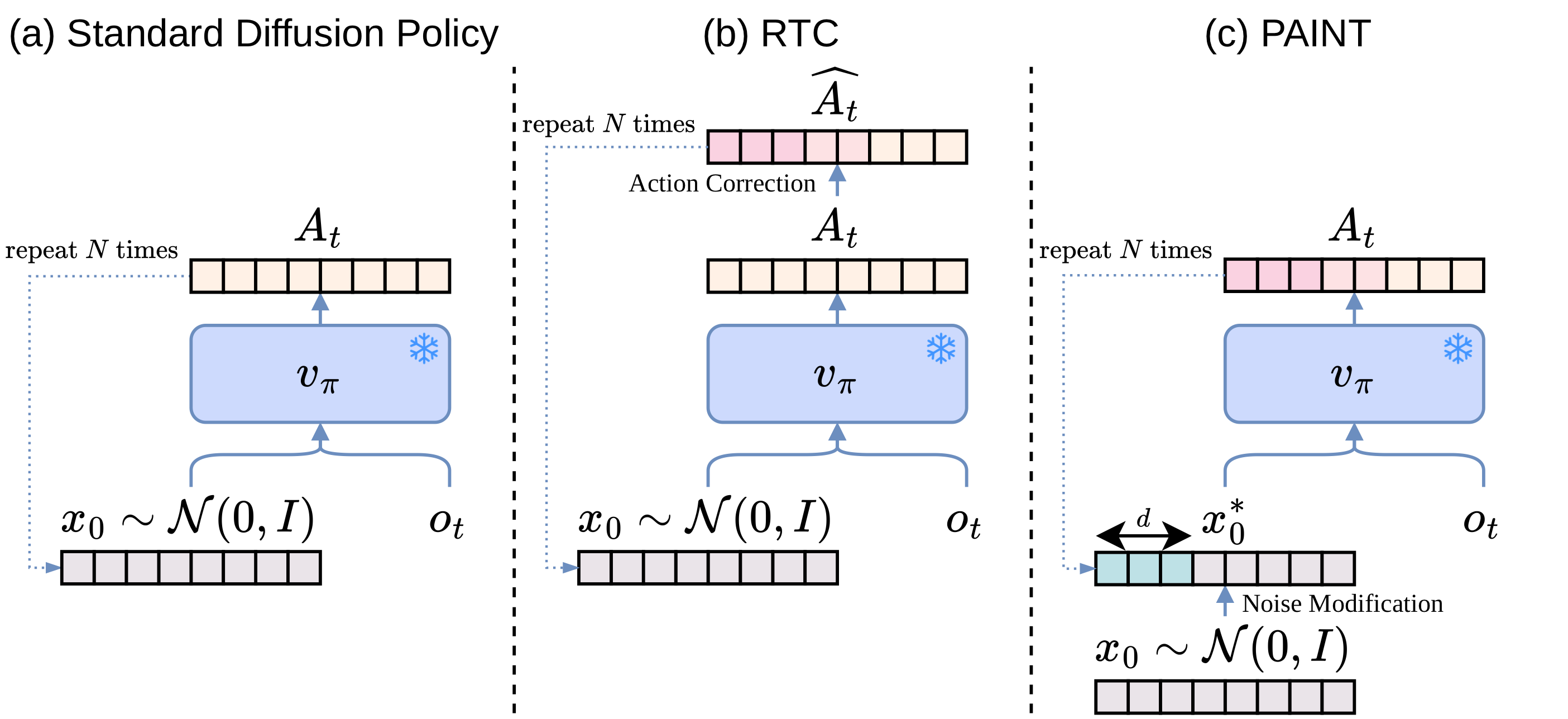
- PAINT는 fresh noise로 naive chunk를 한 번 생성하고, 실행된 prefix와 naive suffix를 합친 target chunk를 backward Euler로 invert한 뒤, inverted noise prefix와 원래 noise suffix를 합쳐 표준 forward flow를 다시 실행한다.
- 12개 Kinetix simulation environment와 6개 real-robot task에서 PAINT는 RTC와 동등하거나 더 높은 task performance와 더 낮은 prefix mismatch를 보였지만, 총 $3N$번의 velocity-network evaluation과 noise–action locality 가정이라는 비용과 제약이 남는다.
Further Analysis
- PAINT는 여러 noise를 생성해 고르는 Best-of-$N$ 방식이 아니다. 하나의 naive sample을 만든 뒤, desired prefix에 대응하는 noise를 approximate inversion으로 구성한다.
- 외부 verifier, reward model, critic 또는 task success estimator가 필요하지 않다. 최적화하려는 대상이 task reward가 아니라 명확히 정의된 temporal consistency constraint이기 때문이다. initial noise를 task score search가 아니라 physical control constraint를 만족시키는 control interface로 사용한다.
- 이 논문이 보존하는 것은 엄밀히 말해 learned velocity field다. PAINT로 구한 initial noise $x_{0}^{*}$ 자체가 원래 prior $\mathcal{N}(0,I)$를 따른다는 보장은 없으므로, “원래 policy distribution을 보존한다”는 주장은 제한적으로 해석해야 한다.
- PAINT는 inference latency를 제거하지 않는다. 오히려 standard inference의 $N$회 evaluation을 $3N$회로 늘리면서 gradient/VJP를 forward-only compute로 교환한다.
- PAINT가 직접 해결하는 것은 action-command seam이다. Observation staleness, contact disturbance, actual state tracking error, long-horizon planning 자체를 해결하지는 않는다.