



InSight: Self-Guided Skill Acquisition via Steerable VLAs
기존 demonstration을 자동으로 primitive 단위로 분해해 pretrained π0.5를 primitive-steerable policy로 만들고, novel task에서 VLM이 발견한 missing primitive를 single-axis controller로 자율 수집·검증한 뒤 VLA에 재학습하여 영속적인 skill vocabulary로 편입하는 VLM-guided continual skill acquisition framework
Overview Figure
Summary
- 기존 VLA는 demonstration에 포함된 task는 수행할 수 있지만, 그 안에 암묵적으로 존재하는 reusable primitive가 full-task language instruction에 얽혀 있어 개별적으로 호출하거나 새로운 skill에 재조합하기 어렵다.
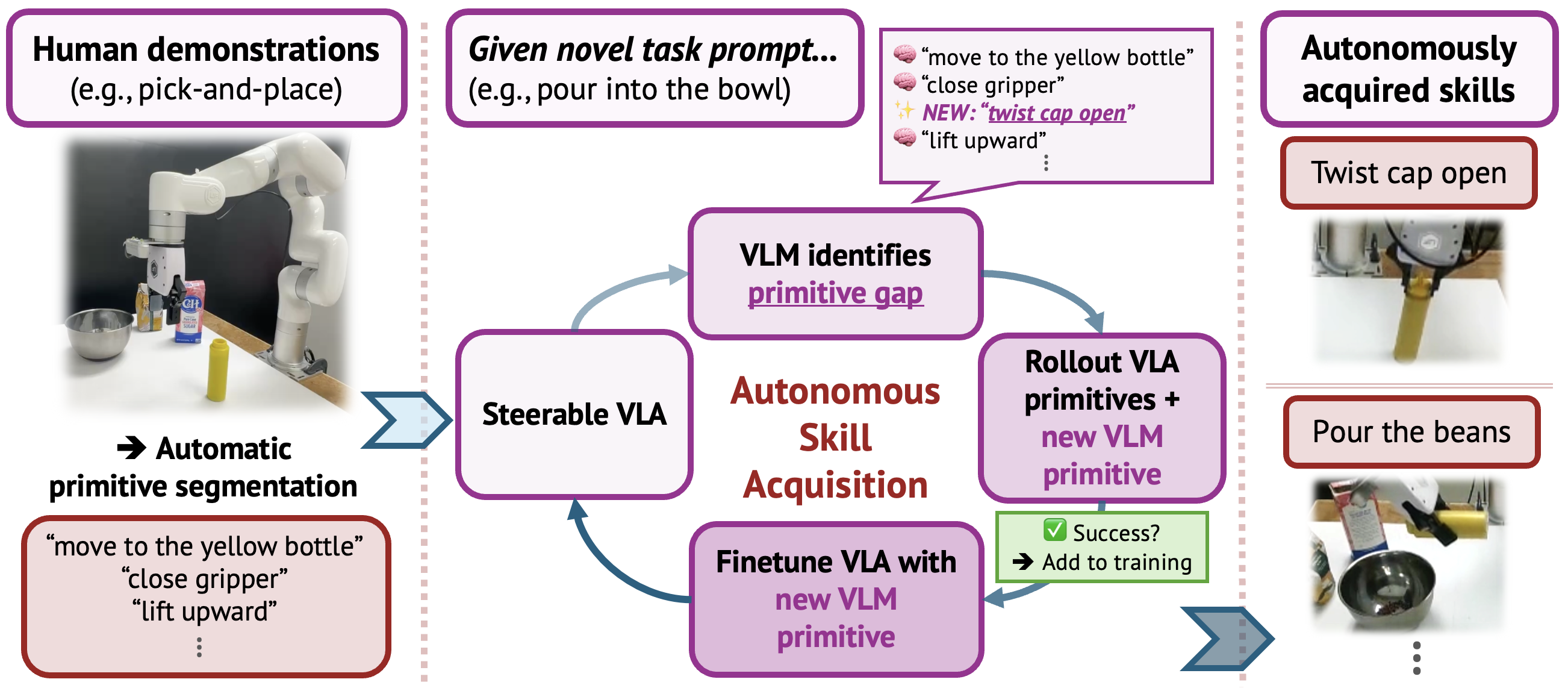
- 이 논문은 target skill의 추가 human demonstration 없이도, robot이 자신에게 부족한 primitive를 찾아 상호작용으로 획득하고 이후 재사용할 수 있는 continual skill acquisition 문제를 다룬다.
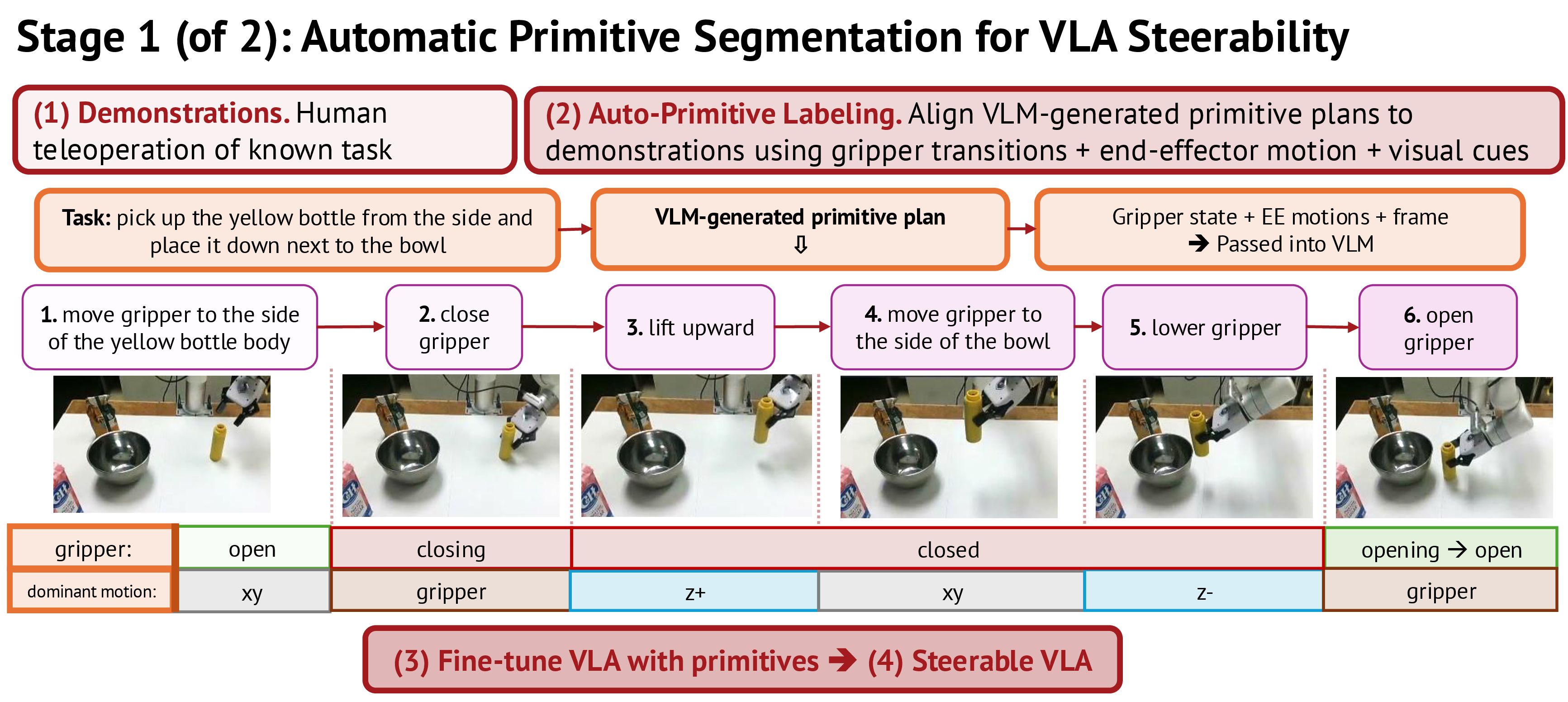
- 핵심 아이디어는 기존 demonstration을 VLM과 end-effector motion signal로 primitive-labeled episode로 자동 분할해 VLA를 steerable하게 만든 뒤, novel task plan에서 현재 vocabulary에 없는 primitive를
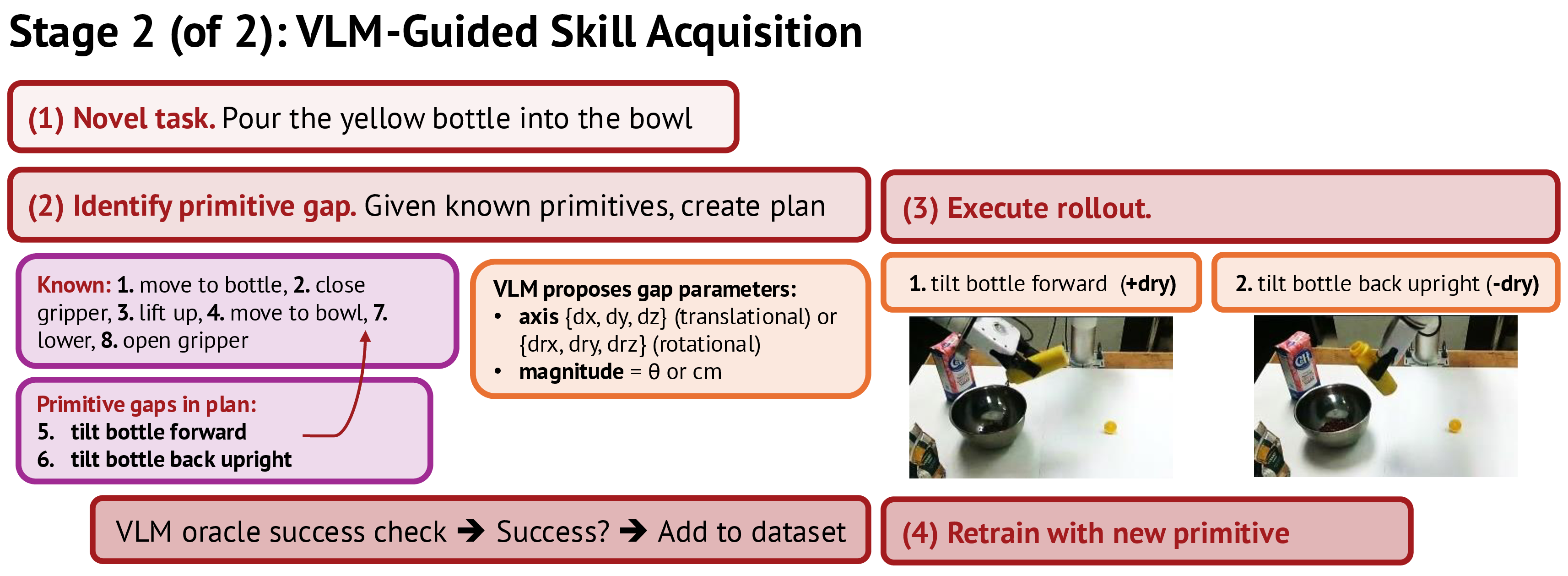
primitive gap으로 정의하는 것이다. - VLM이 missing primitive의 single-axis translation/rotation과 magnitude를 제안하고 scripted controller가 이를 실행하며, VLM oracle이 성공 rollout만 필터링해 기존 데이터와 함께 $\pi_{0.5}$에 LoRA fine-tuning한다.
- Simulation과 xArm 실험에서 twist 92%, pour 96%, 14-primitive twist-then-pour composition 80%를 달성했고, 기존 pick-and-place 성능도 유지했지만, 획득 가능한 primitive가 single-axis motion에 제한되고 manual reset과 VLM 판단에 크게 의존한다.
Further Analysis
- “새 task를 zero-shot으로 수행”하는 방법은 아니다
- 처음에는 VLM과 controller가 target task rollout을 생성하고, 성공 데이터를 모은 뒤 VLA를 재학습한다.
- 즉, 정확한 표현은 zero target-skill human demonstrations이지, zero interaction이나 zero training이 아니다.
- 이 논문의 핵심은 VLM-guided demonstration synthesis + policy distillation이다
- VLM이 행동을 직접 지속적으로 제어하는 대신, 제한된 controller로 successful primitive demonstration을 만들고 이를 learned policy에 distill한다.
- acquisition과 deployment의 구조가 다르다
- Acquisition 중에는 missing primitive를 scripted controller가 수행하지만, retraining 후에는 해당 primitive도 language-conditioned VLA가 수행한다.
- progress channel은 semantic completion detector보다는 temporal phase predictor에 가깝다
- Target이 primitive 내부의 normalized timestep이기 때문이다. 실제로 OOD drawer 상태에서는 progress prediction이 저하되어 별도 VLM completion check가 필요했다.
- continual learning claim은 아직 제한적이다
- 새로운 continual-learning objective, routing, regularization을 제안한 것이 아니라, 기존 primitive data를 replay하면서 새 data를 함께 재학습하는 data-centric 방식이다.