



PolicyTrim: Boosting Intrinsic Policy Efficiency of Vision-Language-Action Models
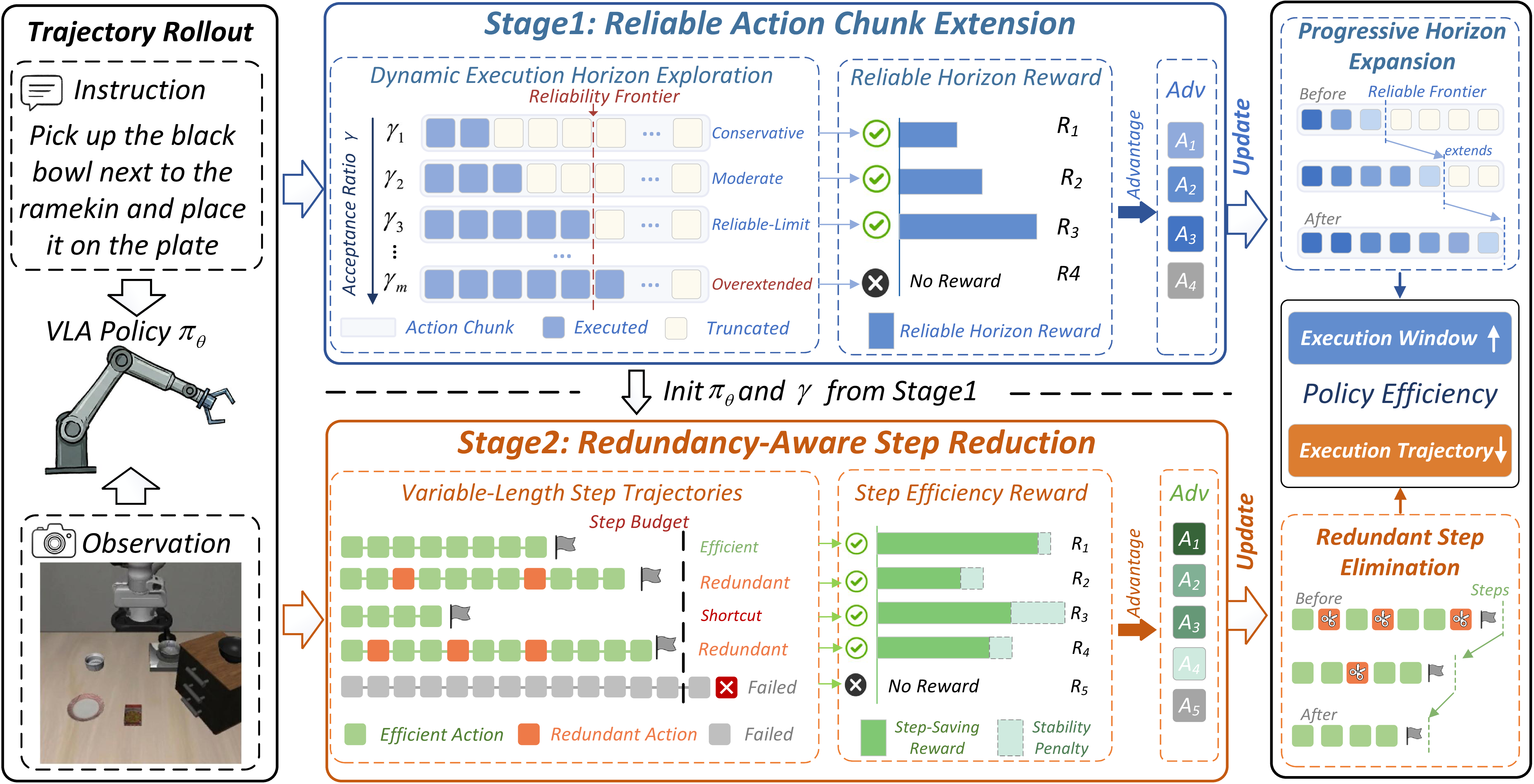
pretrained VLA를 두 단계의 GRPO 기반 RL post-training으로 fine-tuning하여, 한 번의 inference에서 안전하게 실행할 수 있는 action chunk 길이를 늘리고 전체 physical control step은 줄임
Overview Figure
Summary
- 기존 VLA 효율화 연구는 주로 token pruning, quantization, caching처럼 한 번의 forward pass latency를 줄였지만, task 완료까지 필요한 forward 횟수 자체는 거의 다루지 않았다.
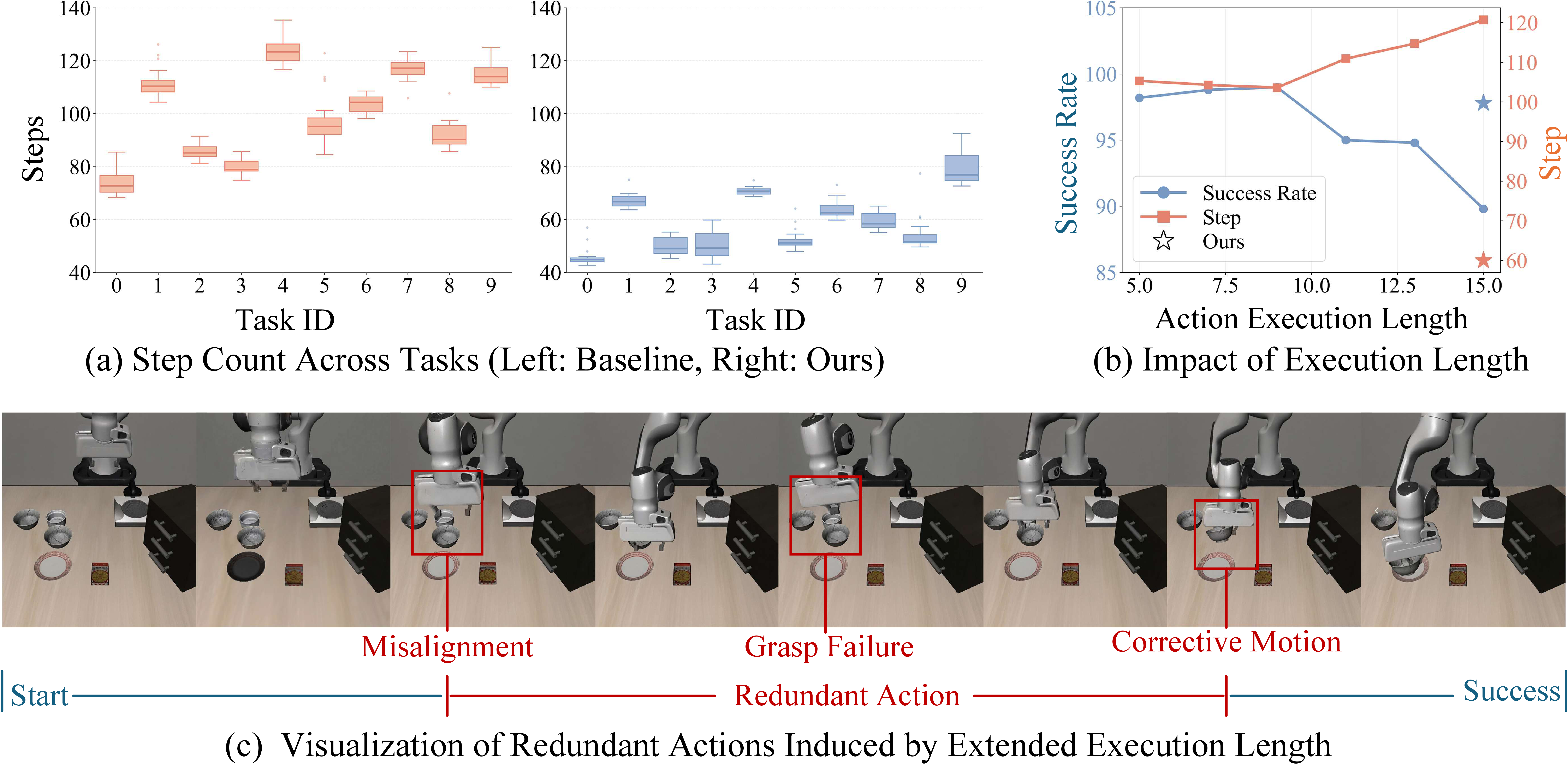
- 저자들은 forward 횟수가 action chunk 중 실제로 실행 가능한 길이와 task를 끝내기 위한 전체 physical step 수에 의해 결정되며, 기존 VLA는 chunk tail degradation과 redundant corrective motion을 동시에 가진다고 본다.
- PolicyTrim의 첫 단계는 동일 task의 rollout group에서 서로 다른 execution horizon을 시험하고, 긴 chunk를 실행하고도 성공한 trajectory에 더 높은 보상을 주어 reliable horizon을 확장한다.
- 두 번째 단계는 성공 trajectory 중 더 적은 step으로 완료한 rollout을 보상하되, group 평균 step 수에서 지나치게 벗어난 trajectory를 penalize하여 우연히 발견된 불안정한 shortcut으로 policy가 collapse하는 것을 막는다.
- LIBERO·ManiSkill·Meta-World 및 세 종류의 VLA에서 성공률을 대체로 유지하면서 inference-call 기준 최대 5.83× speedup을 달성했고, 실제 로봇에서는 평균 1.86× wall-clock speedup을 보였다.
Further Analysis
- Stage 1은 더 긴 open-loop 구간을 견딜 수 있는 policy를 만들고, Stage 2는 전체 path 자체를 짧게 만든다.
- Stage 1만 사용하면 inference 횟수는 감소하지만 tail error 때문에 오히려 physical step이 늘어날 수 있다. Stage 2만 사용하면 shortcut exploitation으로 성공률이 떨어진다. 두 단계를 순차적으로 적용해야 성능과 효율이 함께 개선된다.
- 논문의 “dynamic horizon”은 deployment-time adaptive scheduler가 아니다. Training 중 rollout별로 horizon을 다르게 시험하고, 최종 deployment에서는 선택된 fixed horizon을 사용하는 방식이다.