



See Less, Specify More: Visual Evidence Budgets for Generalizable VLAs
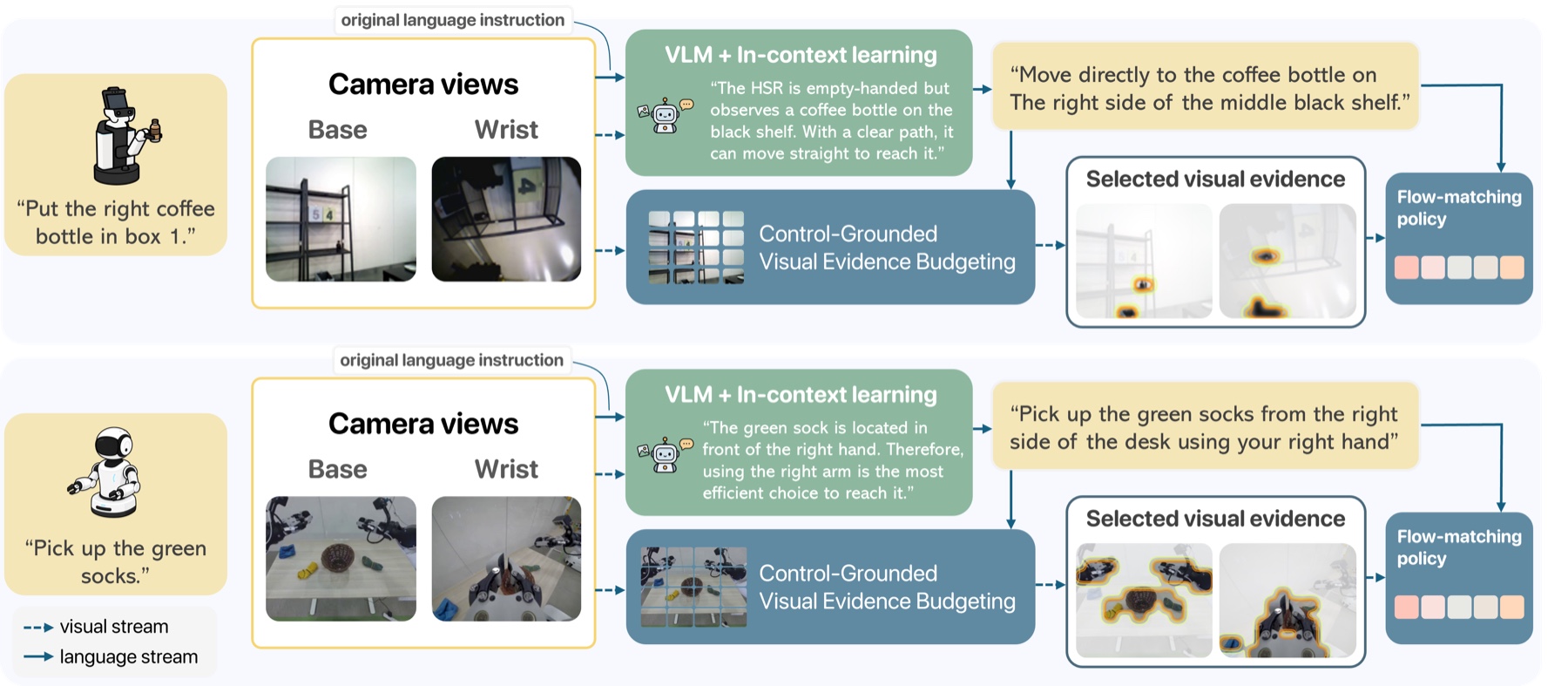
VLA executor가 coarse goal과 full image에서 “무엇을 할지/무엇을 볼지”를 스스로 추론하지 않도록 goal-preserving local language와 learned visual evidence budget을 함께 학습시키는 planner-executor VLA generalization framework
Overview Figure
Summary
- Generalist VLA executor에게 planner, local disambiguation, visual selection, continuous control을 모두 맡기는 것은 finite robot data regime에서 좋지 않은 scaling strategy다(같은 coarse instruction $g$가 여러 valid trajectory를 허용하기 때문).
- Specify More는 원래 instruction $g$를 버리지 않고 유지한 채, demonstration trajectory를 refined trajectory instruction $\tilde{g}$와 active subtask instruction $s_i$로 relabeling해 execution mode ambiguity를 줄인다.
- See Less는 base/wrist image token마다 learned soft gate를 두고, 평균 keep ratio가 visual budget $\rho$에 맞도록 regularization하면서 gated action loss로 task-sufficient evidence만 남기도록 학습한다.