



SANTS: A State-Adaptive Scheduler for World Action Models
WAM이 매번 미래 영상을 끝까지 denoise하지 않고, 현재 로봇 상태에 따라 “여기서 멈출지”와 “얼마나 크게 건너뛸지”를 결정해 full-denoising WAM 대비 success-latency tradeoff를 개선하는 state-adaptive video denoising scheduler
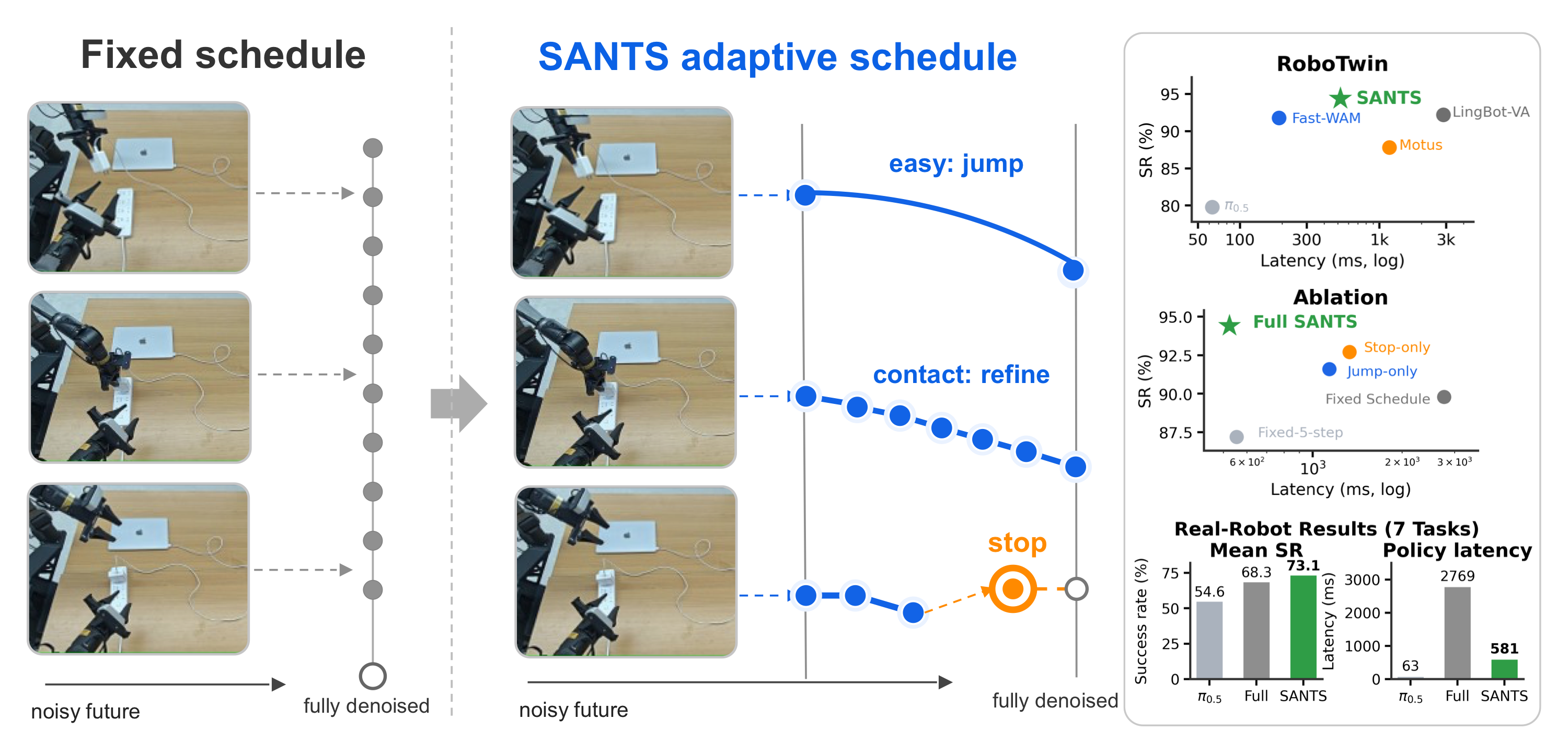 Key Concept Figure
Key Concept Figure
기존의 World Action Model(WAM)은 로봇이 바로 action을 예측하는 대신 미래 video representation을 먼저 만들고 이를 action generation에 사용하지만, pixel-space video denoising이 매우 비싸서 inference latency가 크다. 더 중요한 문제는 fully denoised video가 항상 action에 가장 좋은 조건이 아니라는 점이다. 이 논문에서는 denoising depth를 스캔해보니 coarse motion에서는 얕은 denoising만으로도 충분하고, contact/alignment 같은 fine phase에서는 더 깊은 denoising이 유리하지만, 일부 상태에서는 후반 denoising이 물리적으로 부정확한 미래를 만들어 action error를 오히려 키운다는 점을 보인다.
SANTS(State-Adaptive Noise Trajectory Scheduler)는 frozen video-action diffusion policy 위에 붙는 lightweight scheduler로, 현재 video token representation과 noise level을 보고 cumulative stopping hazard와 relative noise-progression ratio를 예측한다. SANTS는 video fidelity가 아니라 frozen action branch가 만든 최종 action chunk의 품질과 video update cost를 기준으로 PPO post-training된다.
Introduction
WAM은 observation에서 바로 action을 뽑는 direct policy와 달리, 중간에 미래 장면이 어떻게 변할지에 대한 video/future representation을 만든 뒤, 그 representation을 condition으로 action을 생성한다. 이런 future-evolution interface가 object motion, contact change, scene dynamics와 같은 spatiotemporal prior를 manipulation policy에 전달할 수 있다. 문제는 많은 WAM들이 diffusion-based video prediction을 사용한다는 점에서 출발한다. Diffusion이나 flow-matching 기반 video generation은 보통 여러 번의 iterative denoising step을 거쳐야 한다. 즉, 매 robot control cycle마다 미래 video를 끝까지 denoise하고, 그 다음 action을 생성하면 latency가 매우 커진다. 이 논문의 저자들은 WAM test-time bottleneck이 바로 이 video denoising process라고 지적한다.
이 논문의 핵심적인 발견은 “로봇 action generation에 가장 좋은 video condition은 반드시 fully denoised video가 아니다”는 것이다. 일반적인 image/video generation에서는 denoising을 더 많이 하면 더 깨끗한 이미지나 비디오가 나온다고 생각하기 쉽지만 로봇 control에서는 objective가 다르다. 중요한 것은 영상이 보기 좋고 sharp한지가 아니라, “action branch가 contact, alignment, motion trend를 정확하게 읽을 수 있는가”이다. 아래 figure는 coarse phase(approach, free-space motion, and coarse transport)와 fine phase(contact, alignment, grasping, insertion, and placement) 각각에 대해 video denoising depth를 늘릴 때 masked action MSE가 어떻게 변하는지 보여준다:
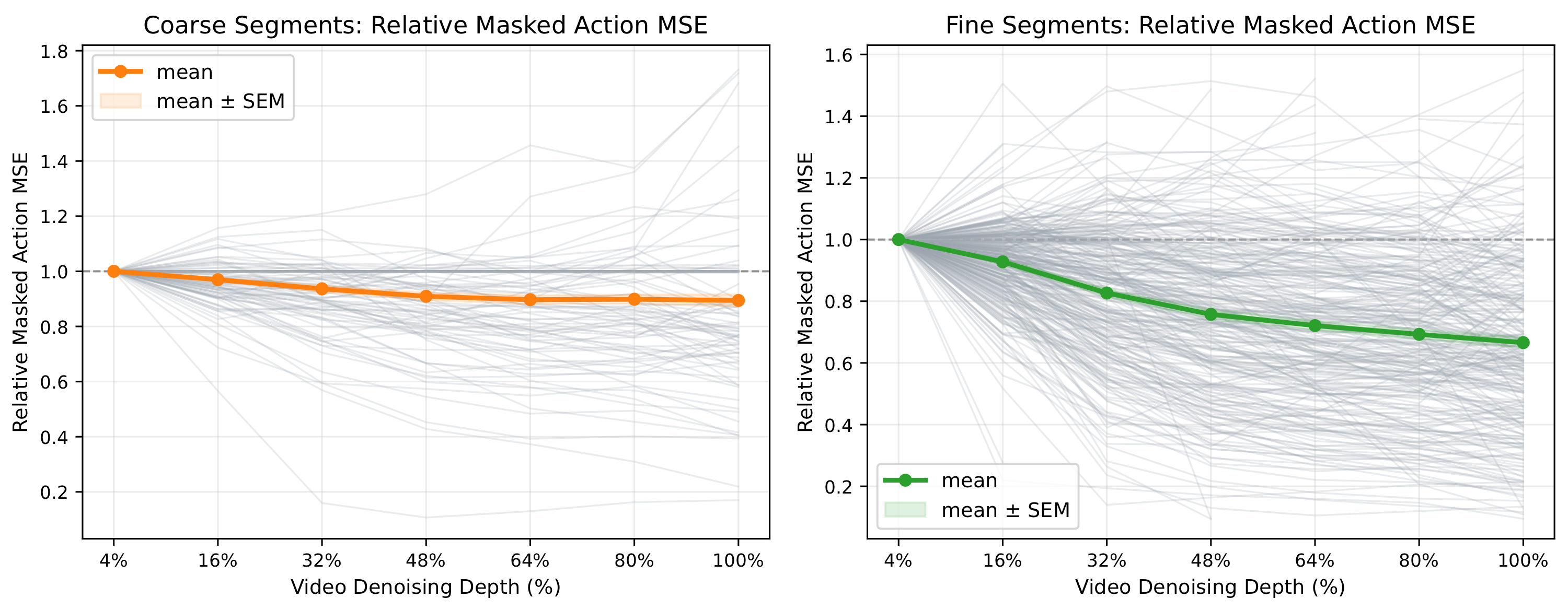 Effect of Video Denoising Depth on Action-Generation Error
Effect of Video Denoising Depth on Action-Generation Error
평균적으로는 denoising이 action error를 줄이지만, gray sample-level curve를 보면 모든 sample이 단조롭게 좋아지는 것은 아니고, 일부는 plateau 또는 degradation을 보인다. 또한 coarse phase에서는 평균 action error가 1.00에서 0.89 정도로만 감소하고, fine phase에서는 1.00에서 0.67까지 더 크게 감소한다는 것을 확인할 수 있다. 따라서 논문의 문제의식은 다음과 같이 정리된다:
기존 fixed WAM inference:
모든 state에서 항상 같은 denoising schedule 사용
→ 항상 마지막 fully denoised future video를 action condition으로 사용
논문의 주장:
state마다 action에 필요한 video refinement 양이 다르다
→ state-dependent intermediate video representation을 골라야 한다
따라서 이 논문이 새롭게 정의한 inference 문제는 “pixel-space WAM에서 action generation에 사용할 intermediate video representation을 state에 따라 선택하자”이다. 기존 fixed schedule은 1) 언제 멈출지(terminal denoising depth), 2) 다음 noise level로 얼마나 이동할지(denoising trajectory의 integration grid)를 사전에 고정한다. 하지만 논문의 저자들은 이 두 가지 모두 현재 state에 따라 dynamic하게 결정해야 한다고 주장한다. 예를 들어 action intent가 명확한 easy state에서는 큰 jump를 해서 low-value denoising region을 건너뛰고, contact-rich/alignment-sensitive state에서는 더 세밀한 update를 유지해야 한다. 이에 SANTS는 frozen video-action diffusion policy에 붙는 plug-in scheduler로, 각 video denoising decision point에서 현재 video-state representation과 noise level을 읽고 1) 지금 멈춰야 할지와 2) 계속한다면 noise axis를 얼마나 진행할지를 동시에 결정한다:
| Decision | Question | Role |
|---|---|---|
| Adaptive stop | 지금 intermediate video representation으로 action을 만들어도 되는가? | terminal representation 선택 |
| Adaptive jump / relative progression | 계속 denoise한다면 noise axis를 얼마나 크게 이동할 것인가? | low-value region skip 또는 fine update 유지 |
Preliminaries
| 개념 | 의미 | 로봇 action에 항상 좋은가? |
|---|---|---|
| Video fidelity | 영상이 얼마나 깨끗하고 자연스럽게 보이는가 | 아님 |
| Action utility | action branch가 올바른 action을 만들 수 있는 정보를 얼마나 담고 있는가 | 중요 |
Method
Frozen video-action policy interface
SANTS는 새로운 robot policy backbone이 아니라 기존 pretrained video-to-action diffusion policy의 frozen video-action Transformer $f_{\phi}$ 위에 붙는 scheduler이다. Noise level $\sigma_{k}$에서 policy는 video latent $x_k$를 유지하고, video-denoising forward pass는 이 latent를 update하는 flow field를 예측한다. 동시에 같은 forward pass에서 video token들의 pooled hidden representation을 추출해 $z_{k}$라고 두며, 이것이 scheduler state가 된다. 정리하자면 SANTS가 받는 input은 $(z_{k}, \sigma_{k})$로, 각각 현재 intermediate video representation의 hidden feature와 현재 noise level이다. SANTS training 과정에서 학습을 하지 않는 부분과 하는 부분은 다음과 같다:
Frozen:
- WAM backbone
- video head
- action head
- action denoising process
Trainable:
- lightweight scheduler only
이 논문은 model architecture scaling보다는 inference-time compute allocation에 가깝다. 위와 같은 구조 덕분에 SANTS는 intermediate video feature와 nonuniform noise-level update를 제공하는 compatible WAM에 plug-in처럼 붙을 수 있다.
Overview
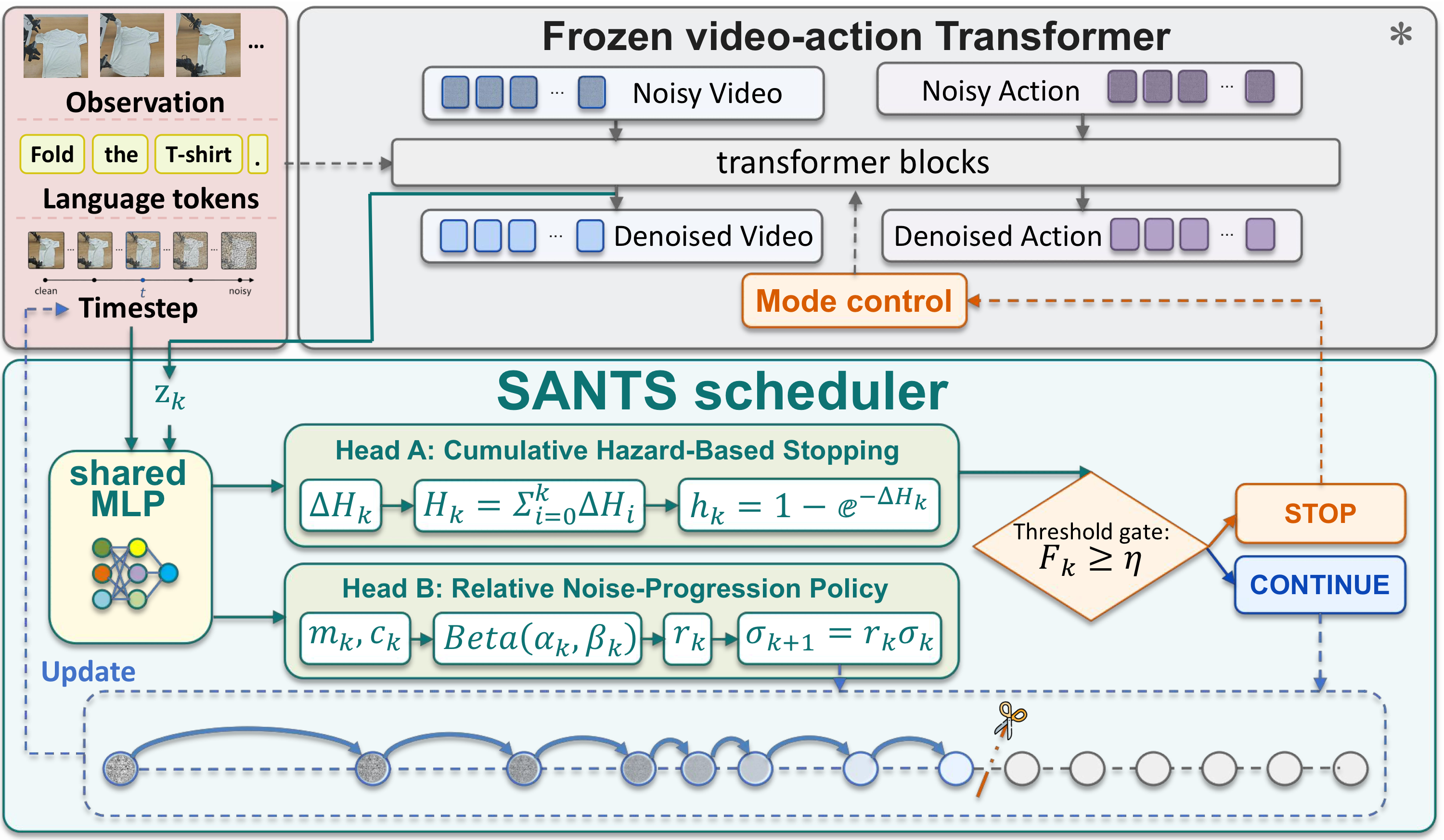 SANTS overview
SANTS overview
Observation + language + history
↓
Frozen video-action Transformer
↓
현재 video token representation z_k 추출
↓
SANTS scheduler
├─ Head A: cumulative hazard-based stopping
└─ Head B: relative noise-progression policy
↓
STOP이면:
현재 video representation을 action branch에 전달
CONTINUE이면:
noise level을 σ_{k+1}로 이동하고 video latent update
Head A: Cumulative hazard-based stopping
SANTS는 매 decision point마다 지금 멈출지를 결정한다. 단순히 매 step마다 independent stop probability를 예측하면, deployment에서 전체 trajectory 관점의 stopping evidence를 안정적으로 누적하기 어렵다. 그래서 논문은 cumulative hazard 방식으로 stop decision을 모델링한다.
현재 decision index를 $k$, 처음으로 video integration이 종료되는 시점을 $T$라고 하자. SANTS의 stopping head는 현재 state $(z_{k}, \sigma_{k})$를 scalar score로 mapping한 뒤 softplus를 통해 nonnegative hazard increment를 만들고 이 hazard increment를 trajectory를 따라 누적한다:
\[ \begin{align} \Delta H_k &= \text{softplus}(g(z_{k}, \sigma_{k})) \geq 0 \\ H_k &= \sum^{k}_{i = 1} \Delta H_i \end{align} \]Cumulative stopping probability를 다음과 같이 정의한다:
\[ F_k = P(T \leq k) = 1 - e^{-H_k} \]즉 $F_k$는 지금까지 누적된 termination evidence 기준으로, $k$ 이전 또는 $k$에서 멈췄을 확률이다. Conditional stopping probability는 다음과 같다:
\[ h_k = P(T = k | T \geq k) = 1 - e^{- \Delta H_k} \]Training에서는 $h_k$를 stochastic stop/continue policy로 사용해 trajectory log-probability를 계산한다. Deployment에서는 $F_k$가 threshold $\eta$를 넘으면 deterministic하게 stop한다 ($\eta = 0.85$).
각 step에서:
"이제 멈춰도 될 것 같다"는 evidence ΔH_k를 더함
누적 evidence H_k가 커짐
→ cumulative stop probability F_k 증가
→ threshold η를 넘으면 stop
Head B: Relative noise-progression policy
만약 continue하기로 했다면, 다음 noise level로 얼마나 이동할지를 여기서 선택한다. 기존 fixed denoising schedule은 모든 state가 같은 discrete noise grid를 따라간다. 하지만 action intent가 이미 명확한 상태에서는 작은 step을 여러 번 밟을 필요가 없다. 반대로 contact나 insertion처럼 세밀한 미래 evolution이 중요한 상태에서는 conservative하게 천천히 진행해야 한다. 그래서 SANTS는 continuation을 relative noise ratio로 모델링한다.
SANTS는 $r_k \sim \text{Beta}(\alpha_k, \beta_k)$ ratio를 sampling해서 다음 noise level을 $\sigma_{k + 1} = r_k \sigma_k$로 정한다 ($r_k \in (0, 1)$). 즉 $1 - r_k$가 relative progression distance이다.
| $r_k$ 값 | 의미 |
|---|---|
| $r_k \approx 1$ | noise를 조금만 줄임. Conservative progression. 세밀한 update. |
| $r_k$ 작음 | noise를 크게 줄임. Aggressive progression. 큰 jump. |
논문은 Beta distribution의 $\alpha_k$, $\beta_k$를 직접 예측하지 않고 mode $m_{k} \in (0, 1)$와 concentration $c_{k} > 2$를 예측한다.
\[ \begin{align} \alpha_k &= m_{k} (c_{k} - 2) + 1 \\ \beta_k &= (1 - m_{k})(c_{k} - 2) + 1 \end{align} \]따라서 $\alpha_k > 1$, $\beta_k > 1$이 보장되어 unimodal Beta distribution이 되고, mode가 $m_k$가 된다. Training에서는 exploration을 위해 $r_k$를 sample하고, deployment에서는 deterministic하게 $m_k$를 progression ratio로 사용한다.
Easy state:
action intent clear
→ small r_k
→ 큰 jump
→ latency 감소
Contact-rich state:
future/contact uncertainty high
→ r_k close to 1
→ 작은 step으로 refine
→ action quality 보존
Path-level reward: video fidelity가 아니라 action quality로 학습
SANTS가 골라야 하는 것은 “각 state에서 action에 가장 좋은 intermediate video depth”이다. 하지만 이 depth에 대한 ground-truth label은 없다. 사람이 “이 state는 32% denoising이 최적이다” 같은 label을 달아줄 수 없다. 또한 video reconstruction loss로 학습하면 문제가 생긴다. 더 clean한 video가 action에 더 유용하다는 보장이 없기 때문이다.
그래서 논문은 SANTS를 trajectory policy로 보고, path-level reward로 post-training한다. Reward는 sampled noise trajectory가 끝난 뒤 frozen action branch가 최종 action chunk를 생성하고 나서 계산된다. 따라서 scheduler는 intermediate video fidelity가 아니라 downstream action quality를 기준으로 학습된다:
\[ R(\tau) = \sum_{m \in \{\text{seq}, \Delta\}} w_m \Phi_m(L_m^\tau, L_m^{lo}, L_m^{hi}) - \lambda_c \Psi(n_\tau) \]위에서 $m$은 두 종류의 action error를 뜻한다 ($m \in \{ \text{seq}, \Delta \}$). 각각 action sequence 자체가 demonstration과 얼마나 다른지, adjacent action 간 변화량(즉 motion trend)이 demonstration과 얼마나 다른지를 의미한다. 즉, 단순히 각 timestep의 pose가 맞는지만 보는 것이 아니라, action trajectory의 변화 방향도 본다. 이는 contact transition이나 gripper event가 critical한 manipulation에서 중요하다.
| Symbol | 의미 |
|---|---|
| $\tau$ | SANTS가 선택한 sampled denoising path |
| $L^\tau_{seq}$ | sequence-level action error |
| $L^\tau_{\Delta}$ | temporal-difference action error |
| $L_m^\tau$ | SANTS가 선택한 path $\tau$에서 나온 action error |
| $L^{lo}_m$ | shallow-denoising reference path의 action error |
| $L^{hi}_m$ | full-denoising reference path의 action error |
| $n_\tau$ | path $\tau$에서 실제 수행한 video-state update 횟수 |
| $\lambda_c$ | compute/update cost weight |
reward는 단순 action error가 아니라, 같은 input에 대해 shallow path와 full-denoising path를 anchor(reference path)로 두고 action-quality gain을 normalize하며, 불필요한 video update를 penalize한다. Reward에 대한 자세한 내용은 논문의 section 3.3과 Appendix D에 있다. 직관적으로는 reward가 묻는 것은 다음과 같다:
이 sample에서 full denoising이 shallow denoising보다 실제로 action을 개선하는가?
개선한다면 SANTS path가 그 action-quality gain을 얼마나 회복했는가?
그 gain을 얻기 위해 video update를 얼마나 많이 썼는가?
Full-denoising anchor 자체가 shallow anchor보다 별로 좋지 않은 sample에서는, scheduler가 굳이 더 denoise하도록 reward를 주지 않는다. 그래서 plateau 또는 non-monotonic case에서 early termination을 배울 수 있다.
PPO post-training
SANTS는 path-level PPO로 post-training된다. PPO에서는 sampled path의 stop/continue decision과 jump density의 log-probability를 사용하고, path return에서 EMA baseline을 뺀 advantage를 쓴다.
정리하면 training loop는 아래와 같다:
For each demonstration segment:
1. 현재 SANTS policy로 denoising path τ sample
2. terminal video representation으로 frozen action branch가 action chunk 생성
3. shallow anchor τ_lo 실행
4. full-denoising anchor τ_hi 실행
5. action error 기반 normalized quality gain 계산
6. video update cost 차감
7. PPO로 scheduler만 update
Deployment에서는 stochastic sampling 대신 deterministic mode를 사용한다:
At each video decision point:
1. z_k, σ_k 입력
2. cumulative stop probability F_k 계산
3. F_k ≥ η이면 stop
4. 아니면 progression mode m_k로 σ_{k+1}=m_k σ_k 이동
Experiments
논문의 실험은 크게 세 가지 질문에 답한다.
- video denoising trajectory를 따라 action utility가 정말 state-dependent하게 변하는가?
- SANTS가 simulation과 real robot에서 success-latency tradeoff를 개선하는가?
- adaptive stop과 adaptive jump가 각각 필요한가?
Offline Diagnostic
먼저 논문은 fully denoised future video가 항상 action generation에 가장 유용한 condition인지 확인하기 위해 offline depth diagnostic을 수행한다. RoboTwin 2.0 target-domain data로 video-action backbone을 fine-tuning한 뒤 모든 policy parameter를 freeze하고, 500개의 manually phase-annotated diagnostic segment에 대해 다음 denoising depth를 scan한다.
4%, 16%, 32%, 48%, 64%, 80%, 100%
각 segment는 coarse phase와 fine phase로 나뉜다.
| Phase | 포함되는 행동 |
|---|---|
| Coarse phase | approach, free-space motion, coarse transport |
| Fine phase | contact, alignment, grasping, insertion, placement |
Metric은 normalized action space에서의 masked action MSE이며, 모든 error는 4% denoising depth를 baseline으로 normalize한다.
앞의 Figure에서 보았듯이 coarse phase에서는 denoising depth를 늘려도 평균 action error가 1.00에서 0.89 정도로만 감소한다. 반면 fine phase에서는 1.00에서 0.67까지 더 크게 감소한다. 즉, coarse motion에서는 얕은 future representation만으로도 action cue가 충분한 경우가 많지만, contact/alignment가 중요한 fine phase에서는 더 깊은 denoising이 도움이 된다.
하지만 sample-level curve를 보면 full denoising이 항상 best는 아니다. Appendix C의 추가 통계에서도 이를 확인할 수 있다.
| Phase | 100% denoising이 best가 아닌 비율 | Adjacent increase 비율 | Oracle mean | Fixed 100% mean |
|---|---|---|---|---|
| Coarse | 55.65% | 87.90% | 0.8433 | 0.8943 |
| Fine | 41.33% | 77.49% | 0.6084 | 0.6571 |
여기서 100% denoising이 best가 아닌 비율은 full denoising보다 intermediate depth에서 action error가 더 낮았던 segment의 비율을 의미한다. Adjacent increase는 denoising depth를 늘리는 과정에서 action MSE가 한 번이라도 증가한 segment의 비율이다. 이 결과는 action utility가 denoising depth에 대해 strictly monotonic하지 않다는 것을 보여준다.
따라서 이 diagnostic은 SANTS의 핵심 motivation을 뒷받침한다.
Video fidelity가 높아지는 것과
action utility가 높아지는 것은 다르다.
따라서 WAM은 항상 fully denoised video를 action condition으로 쓰기보다,
현재 state에 맞는 intermediate video representation을 선택해야 한다.
Experimental Setup
모든 실험에서 SANTS는 Wan2.2-5B 기반 video-action diffusion policy를 backbone으로 사용한다. Simulation에서는 RoboTwin 2.0 benchmark를 사용하고, baseline으로 LingBot-VA, Motus, Fast-WAM, π0.5를 비교한다. Real-robot evaluation에서는 π0.5와 Full-Denoising WAM을 비교한다. 여기서 Full-Denoising WAM은 SANTS와 같은 video-action backbone을 공유하지만 항상 future video representation을 final denoised state까지 denoise하는 controlled baseline이다. 평가 metric은 task success rate와 end-to-end policy inference latency이다.
Simulation Results on RoboTwin 2.0
RoboTwin 2.0은 bimanual fine manipulation, object contact, randomized multi-task scenes를 포함하는 benchmark이다. 논문은 50개 RoboTwin 2.0 task에서 각 task당 50 trial을 수행한다. SANTS는 세 random seed에서 94.1%, 94.5%, 94.6% overall success를 얻었고, 평균 94.4%, standard deviation 0.3%를 보고한다.
| Method | Easy SR | Hard SR | Overall SR | A100 Latency |
|---|---|---|---|---|
| LingBot-VA | 92.9% | 91.5% | 92.2% | 2868.4 ms |
| Motus | 88.7% | 87.0% | 87.8% | 1175 ms |
| Fast-WAM | 91.9% | 91.8% | 91.8% | 190 ms |
| π0.5 | 82.7% | 76.8% | 79.8% | 63 ms |
| SANTS | 94.6% | 94.2% | 94.4% | 523.7 ms |
SANTS는 overall success 94.4%로 가장 높은 성능을 보인다. Full-denoising WAM 계열인 LingBot-VA와 비교하면 success rate는 92.2%에서 94.4%로 증가하고, latency는 2868.4 ms에서 523.7 ms로 감소한다. 즉, SANTS는 full-denoising WAM 대비 latency를 약 81.7% 줄이면서도 success rate를 오히려 높인다.
다만 SANTS가 가장 빠른 방법은 아니다. π0.5는 63 ms로 훨씬 빠르지만 overall success가 79.8%로 낮고, Fast-WAM은 190 ms로 빠르지만 overall success가 91.8%로 SANTS보다 낮다. 따라서 SANTS의 장점은 pure speed가 아니라, WAM의 future-representation benefit을 유지하면서 full denoising의 redundant cost를 크게 줄인다는 점이다.
π0.5:
매우 빠르지만 success가 낮음
Full-denoising WAM:
success는 높지만 latency가 큼
SANTS:
WAM의 future reasoning benefit을 유지하면서
불필요한 video denoising cost를 제거
Real-Robot Results
논문은 두 개의 real-robot platform에서 총 7개 task를 평가한다.
| Platform | Tasks |
|---|---|
| AgileX dual-arm | clothes folding, backpack packing, sock placement, charger insertion |
| UR10 kitchen | plate transfer, fridge placement, fruit sorting |
각 task마다 method별 50 independent trials를 수행한다. 세 방법, 즉 π0.5, Full-Denoising WAM, SANTS는 같은 task definition, workspace bounds, camera input, action interface, deployment stack, termination rule을 사용한다. 또한 같은 100시간 real-robot data와 같은 adaptation budget을 공유한다.
| Platform | Task | π0.5 | Full-Denoising WAM | SANTS |
|---|---|---|---|---|
| AgileX dual-arm | Clothes folding | 38.0% | 54.0% | 62.0% |
| AgileX dual-arm | Backpack packing | 46.0% | 68.0% | 74.0% |
| AgileX dual-arm | Sock placement | 60.0% | 76.0% | 78.0% |
| AgileX dual-arm | Charger insertion | 30.0% | 38.0% | 58.0% |
| UR10 kitchen | Plate transfer | 68.0% | 66.0% | 80.0% |
| UR10 kitchen | Fridge placement | 48.0% | 72.0% | 74.0% |
| UR10 kitchen | Fruit sorting | 92.0% | 86.0% | 86.0% |
| Overall Mean | — | 54.6% | 65.7% | 73.1% |
| Mean Policy Latency | — | 63 ms | 2769.3 ms | 581.3 ms |
SANTS는 7개 task 평균 73.1% success를 달성한다. 이는 π0.5보다 18.6 percentage point 높고, Full-Denoising WAM보다 7.4 percentage point 높다. 또한 Full-Denoising WAM의 평균 policy latency가 2769.3 ms인 반면, SANTS는 581.3 ms로 줄어들어 약 79.0% latency reduction을 달성한다.
흥미로운 점은 SANTS가 단순히 full denoising보다 빠른 것에 그치지 않고, real robot에서도 Full-Denoising WAM보다 평균 success가 높다는 것이다. 이는 full denoising이 항상 더 좋은 action condition을 제공하는 것이 아니라는 논문의 주장과 일관된다. 특히 charger insertion처럼 precise contact가 중요한 task에서 π0.5는 30.0%, Full-Denoising WAM은 38.0%인데, SANTS는 58.0%까지 올라간다.
논문의 real-robot setting은 action chunk 기반 replanning 방식이다. UR10 real-robot inference에서는 client가 predicted action을 10 Hz로 보내고, 각 model query는 16 future action step을 반환한다. 즉, 한 번의 query가 약 1.6초 execution window를 만들고, 이후 다시 replanning한다. 따라서 SANTS의 latency는 high-frequency low-level servoing보다는 action chunk 기반 WAM replanning latency로 이해하는 것이 정확하다.
Ablation Study
논문은 SANTS의 두 핵심 component인 adaptive stop과 adaptive jump가 각각 필요한지 확인하기 위해 ablation을 수행한다.
| Method | Adaptive Stop | Adaptive Jump | RoboTwin Overall SR | Latency |
|---|---|---|---|---|
| Fixed-5-step | No | No | 87.2% | 553.9 ms |
| Fixed-full | No | No | 89.8% | 2769.3 ms |
| Jump-only | No | Yes | 91.6% | 1137.7 ms |
| Stop-only | Yes | No | 92.7% | 1329.3 ms |
| Full SANTS | Yes | Yes | 94.4% | 523.7 ms |
가장 중요한 비교는 Fixed-5-step과 Full SANTS이다. 두 방법의 latency는 거의 비슷하다. Fixed-5-step은 553.9 ms이고, SANTS는 523.7 ms이다. 하지만 success rate는 Fixed-5-step이 87.2%, SANTS가 94.4%이다.
즉, SANTS의 성능 향상은 단순히 denoising step 수를 줄였기 때문이 아니다. 같은 수준의 latency budget 안에서도, state에 따라 언제 멈출지와 얼마나 크게 noise trajectory를 이동할지를 adaptive하게 결정하는 것이 중요하다.
Stop-only와 Jump-only도 fixed schedule보다는 좋지만 Full SANTS보다는 낮다.
Stop-only:
terminal representation을 고를 수는 있지만,
continue 이후 low-value denoising region을 건너뛰기 어렵다.
Jump-only:
noise trajectory를 adaptive하게 이동할 수는 있지만,
action branch에 넘길 terminal representation을 직접 선택하지 못한다.
Full SANTS:
stop과 jump를 함께 사용해
state-dependent compute allocation을 수행한다.
따라서 adaptive stop과 adaptive jump는 서로 대체 관계가 아니라 complementary한 관계이다.
Reward Ablation
Appendix에서는 path-level reward의 각 component가 필요한지도 분석한다.
| Variant | Removed or replaced component | Overall SR | Latency |
|---|---|---|---|
| Full path reward | none | 94.4% | 523.7 ms |
| Raw action MSE reward | anchor-normalized gain 제거 | 89.7% | 436.3 ms |
| No temporal-difference error | $L_{\Delta}$ term 제거 | 93.6% | 576.4 ms |
| No difficulty gate | $D_m$ gate 제거 | 90.6% | 489.6 ms |
| No update-cost penalty | $C(n_{\tau})$ term 제거 | 94.9% | 2197.8 ms |
Raw action MSE reward는 latency는 더 낮지만 success가 크게 떨어진다. 이는 단순히 action MSE만 줄이는 reward가 scheduler를 너무 aggressive하게 early stop하도록 만들 수 있음을 보여준다. No difficulty gate도 success가 크게 떨어지는데, 이는 full-denoising anchor 자체가 별로 이득을 주지 않는 low-information sample에서 reward가 잘못 calibrate될 수 있기 때문이다.
반대로 update-cost penalty를 제거하면 success는 94.9%로 약간 올라가지만 latency가 2197.8 ms까지 증가한다. 즉, cost penalty가 없으면 scheduler는 안전하게 더 많이 denoise하는 방향으로 가게 된다. Full path reward는 success만 최대화하는 것이 아니라, action-quality gain과 compute cost 사이의 tradeoff를 맞추는 reward라고 볼 수 있다.
Takeaway
실험 결과를 종합하면 이 논문의 핵심 메시지는 다음과 같다.
1. WAM에서 fully denoised video가 항상 best action condition은 아니다.
2. Action-useful denoising depth는 task phase와 current state에 따라 달라진다.
3. SANTS는 stop과 jump를 함께 학습해 WAM의 future reasoning benefit은 유지하면서 redundant video denoising latency를 줄인다.
따라서 SANTS는 단순한 few-step acceleration 기법이라기보다, WAM inference에서 action utility 기준으로 compute budget을 state-adaptive하게 배분하는 scheduler라고 이해할 수 있다.
Limitations
이 논문의 한계는 evaluation 범위가 RoboTwin 2.0과 두 개 real-robot platform에 제한되어 있다는 점이다. 따라서 더 다양한 embodiment, camera setup, task family, video-action backbone에서 같은 scheduling 전략이 잘 작동하는지는 추가 검증이 필요하다. 또한 SANTS는 video-action backbone을 freeze한 상태에서 scheduler만 학습하므로, backbone과 scheduler를 joint optimization했을 때의 성능은 아직 탐구되지 않았다. 마지막으로 SANTS는 주로 video-denoising cost를 줄이는 방법이기 때문에, action denoising, perception, communication, low-level control frequency까지 포함한 end-to-end adaptive budget allocation은 future work로 남아 있다.
Personal Idea
이 논문에서 특히 흥미로웠던 점은, 한 trajectory 안에서도 모든 action chunk가 같은 양의 inference compute를 필요로 하지는 않는다는 관점이다. 나도 이전에 현재 policy가 만들려는 action의 어려운 정도에 따라 compute budget을 동적으로 조절하는 방식이 더 feasible할 수 있다고 생각한 적이 있다. 당시에는 주로 latency reduction 관점에서만 생각했는데, SANTS의 결과는 adaptive compute allocation이 단순히 빠른 inference뿐 아니라 success rate 개선으로도 이어질 수 있음을 보여준다.