



SMoDP: Semantically Structured Mixture-of-Experts for Compositional Robotic Manipulation
Diffusion policy의 MoE router를 skill-aware하게 만들어 multi-task manipulation에서 expert를 의미 있는 skill 단위로 재사용하게 만든다
Diffusion policy는 정밀한 manipulation에는 강하지만, multi-task 환경으로 확장했을 때 1) precise control, 2) broad generalization, 3) real-time inference efficiency를 동시에 만족하기가 어렵다. 기존 MoE(Mixture of Experts) diffusion policy들은 noise level이나 latent/statistical signal 기반 routing에 의존하기 때문에 grasp, approach, place와 같은 재사용 가능한 skill이 여러 expert로 쪼개지는 routing confusion 문제가 생길 수 있다.
이 논문은 위 문제를 해결하기 위해 offline VLM skill abstraction으로 demonstration을 <approach bowl>, <pick up bowl>, <move towards drawer>와 같은 open-vocabulary verb-noun skill segment로 나누고, inference할 때는 VLM annotation으로 학습된 lightweight skill predictor가 현재 observation과 instruction으로 upcoming skill embedding을 예측하도록 한다. 그렇게 예측된 skill embedding은 diffusion transformer의 MoE router에 들어가 action chunk 내부의 action token들이 동일한 skill-conditioned router token을 공유하도록 해서 chunk-level expert switching을 줄인다.
Introduction
Diffusion Policy는 multimodal action distribution을 표현하기 좋고, temporally coherent한 action chunk를 생성할 수 있기 때문에 single-task manipulation에서 좋은 성능을 보여준다. 하지만 multi-task로 확장했을 때, 하나의 policy가 여러 object, goal, long-horizon task를 모두 처리해야 하므로 단순히 모델을 키우면 계산량과 inference latency가 커지고 모델을 작게 유지하면 generalization이 약해진다. 이것이 위에서 설명한 trilemma이다.
MoE는 전체 parameter capacity는 키우되, 매 inference에서는 parameter의 sparse subset만 사용할 수 있기 때문에 capacity-compute trade-off를 개선할 수 있다. 하지만 여기서의 문제는 무엇을 기준으로 expert를 고를 것인가 하는 것이다. 기존 MoE diffusion policy 계열, 특히 MoDE류 방법론은 diffusion noise level 같은 low-level signal을 기준으로 expert routing을 수행한다. 그런데 manipulation task의 경우 approach → pick up → move → place와 같이 semantic/temporal phase가 명확한 구조를 가진다. noise-level routing은 이런 구조를 직접 보지 않기 때문에, 같은 grasping skill이 어떤 때는 Expert 1, 어떤 때는 Expert 3으로 가는 식의 fragmentation이 생길 수 있다. 논문의 저자들은 이를 skill boundary에서의 routing confusion이라 해석하고, transferability와 interpretability를 제한한다고 지적한다.
Preliminary: MoE
일반적인 MoE는 다음과 같이 동작한다:
- token hidden state $h_t$가 들어온다.
- router가 expert logits를 계산한다.
- softmax 후 top-$k$ expert만 선택한다.
- 선택된 expert output들을 weighted sum한다.
$E$는 expert 수, $G^{l}_{t, e}$는 token $t$가 layer $l$에서 expert $e$를 얼마나 쓰는지 나타내는 gate이다. MoE의 핵심은 전체 expert를 다 쓰지 않고 top-$k$만 쓴다는 점이다. 따라서 parameter capacity는 커지지만 activated compute는 제한된다. Robotics 관점에서는 여러 task/skill을 하나의 모델 안에 담으면서도 inference cost를 줄일 수 있다.
Robot manipulation task는 보통 다음과 같이 decomposable하다:
\[ \text{approach object} \rightarrow \text{pick up object} \rightarrow \text{move towards target} \rightarrow \text{place object} \]위와 같은 구조는 인간에게는 매우 자연스럽지만 기존 MoE router는 현재 action이 어느 phase인지보다 hidden representation, noise level, latent variance 같은 통계적인 signal에 의해서 expert를 고르는 경우가 많다. 그러면 같은 pick up cup류 skill이 서로 다른 expert에 분산될 수 있다. 따라서 이 논문은 비슷한 skill은 비슷한 expert subset을 써야 한다는 inductive bias를 사용한다. 즉 expert는 “task별”, “noise level별”이 아니라 skill semantics별 reusable module이 되도록 한다.
Method
SMoDP(Semantically Structured Mixture-of-Experts Diffusion Policy)는 크게 4가지로 설명할 수 있다:
- Offline Semantic Skill Abstraction
- Lightweight Skill Predictor
- Skill-Conditioned Diffusion MoE Policy
- Dual Semantic Contrastive Alignment
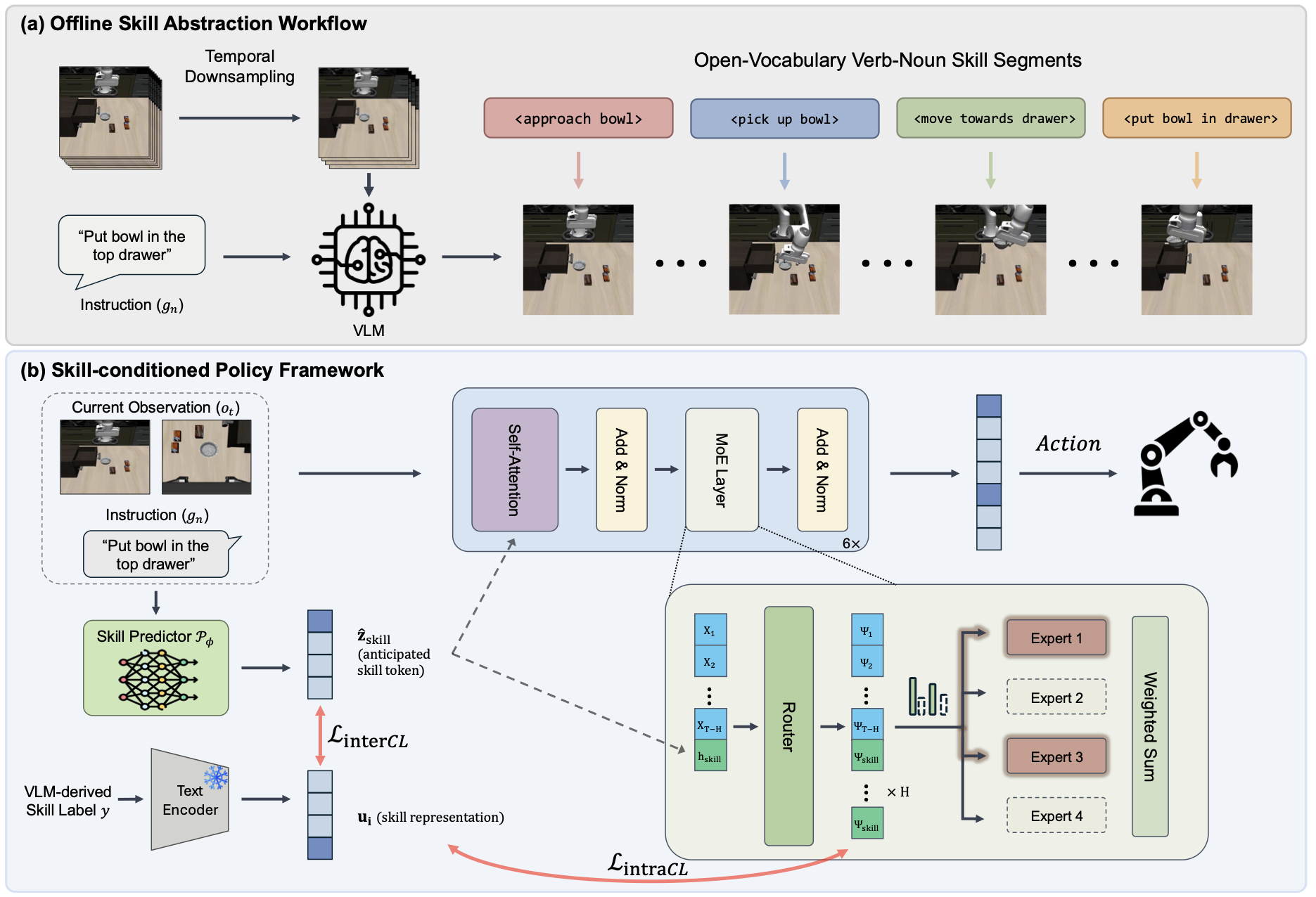 Overall Figure
Overall Figure
Offline Semantic Skill Abstraction
기존의 robot dataset에는 보통 frame-level skill label이 없다. 예를 들어서 demonstration video가 있어도, 어느 구간이 approach bowl이고 어느 구간이 pick up bowl인지 사람이 직접 라벨링해두지 않는다. SMoDP는 이 문제를 VLM으로 해결한다. 하지만 VLM은 offline annotation으로만 사용하고 policy inference에서는 이를 lightweight skill predictor로 대체한다.
먼저 video downsampling을 수행한다. Raw robot demonstration은 high-frequency frame sequence이기 때문에 모든 frame을 VLM에 넣으면 token budget이 커지고 불필요한 jitter가 많아진다. 따라서 논문은 temporal downsampling을 적용해 video $V_n$을 만든다. 실험에서는 Qwen3-VL을 사용했고 downsampling factor $\lambda = 5$를 사용했다.
다음으로 semantic skill extraction을 수행한다. Downsampled video와 task instruction을 VLM에 넣어서 trajectory를 atomic skill sequence로 나눈다. 예를 들면 "Put bowl in the top drawer"와 같은 task를 <approach bowl>, <pick up bowl>, <move towards drawer>, <put bowl in drawer>와 같은 skill segment로 나누는 작업이다. 논문의 저자들은 output space를 verb-noun pair로 제한했는데, 이것이 interpretability와 compositionality를 높이는 semantic bottleneck 역할을 한다고 주장한다.
마지막으로 temporal partitioning을 수행한다. 각 skill에 대해서 VLM이 시작과 끝 timestep $[t^{(j)}_{\text{start}}, t^{(j)}_{\text{end}}]$ 을 추정하고 그에 따른 skill label $y_{n, t}$를 붙여 demonstration dataset $D$를 semantically labeled dataset $D_{\text{sem}}$으로 바꾼다. 여러 demonstration에 대해서는 다음과 같이 적용한다:
| 단계 | 설명 |
|---|---|
| 첫 demonstration | Qwen3-VL이 primitive skill discovery와 temporal segmentation을 수행 |
| 나머지 demonstration | 첫 demo에서 얻은 skill description을 template으로 고정하고, 각 raw episode의 temporal boundary만 다시 맞춤 |
이 설계의 장점은 manual skill set이 필요 없고 open-vocabulary skill annotation을 얻을 수 있다는 점인데, 단점으로는 VLM annotation 품질에 어느정도 의존한다는 것이다.
Lightweight Skill Predictor
Offline에서는 VLM이 skill label을 만들어주지만, 실제 robot inference 때마다 VLM을 부르면 latency가 너무 크기 때문에 작은 skill predictor $P_{\phi}$를 학습한다. visual observation token과 language instruction token을 같이 input(multimodal context $C$)으로 주면 skill predictor는 learnable query $q_{\text{skill}}$를 사용해 context에서 skill-relevant information을 cross-attention으로 뽑는다:
\[ \hat{z}_{\text{skill}} = \text{FFN}(\text{CrossAttn}(q_{\text{skill}}, C, C)) \]$\hat{z}_{\text{skill}}$은 discrete skill ID가 아니라 frozen text encoder embedding space에 있는 continuous skill embedding이다. 그래서 pick up cup과 pick up mug처럼 의미적으로 가까운 skill들이 embedding space에서도 가까워질 수 있다.
Skill-Conditioned Diffusion MoE Policy
SMoDP의 denoiser $f_{\theta}$는 diffusion transformer인데 transformer의 FFN 부분을 MoE block으로 바꾼 버전이다. 우선 predicted skill embedding을 projection해서 conditioning vector $c = W_{c}\hat{z}_{\text{skill}}$을 얻고, 이를 token sequence에 broadcast해서 transformer layer에 넣는다:
\[ \begin{aligned} X^l &= H^{l - 1} + \text{Attn}^{l}(H^{l-1} + \mathbf{1} c^\top) \\ H^l &= X^l + \text{MoE}^{l}(\text{LN}(X^{l}); \hat{z}_{\text{skill}}) \end{aligned} \]SMoDP는 action chunk의 모든 action token이 같은 skill-conditioned router token을 공유하게 만들기 위해 다음과 같은 routing 과정을 사용한다:
위와 같은 chunk-consistent, skill-based routing이 within-chunk expert switching을 줄이고, skill-aligned expert specialization을 장려한다.
Dual Semantic Contrastive Alignment
SMoDP는 predicted skill embedding과 router behavior가 semantic structure를 반영하도록 두가지 contrastive loss를 사용한다. 이들을 계산하기 위해 우선 VLM-generated skill label $y_{i}$를 frozen text encoder에 넣고 normalize한 text embedding $u_{i}$을 구한다. 이후 skill label 간 cosine similarity $w_{ij}$를 계산해서 각 anchor에 대해 top-$m$ most similar sample만 positive로 유지한다. 모든 positive sample이 같은 weight를 가지지 않고 cosine similarity $w_{ij}$를 weight로 설정한다.
1. Inter-Modal Contrastive Learning, InterCL
Skill predictor output을 normalize한 $q_i$를 구하고, batch 내 text embedding $u_j$들과의 similarity logit을 계산한다. InterCL은 predicted skill embedding이 frozen text encoder의 semantic space를 따라가도록 만든다. 즉, model이 skill label을 arbitrary class ID처럼 외우는 것이 아니라, language embedding의 compositional structure를 inherit하게 만든다. 논문의 저자들은 InterCL이 skill predictor와 language-based semantic space 사이의 gap을 줄이고, semantic proximity에 기반한 generalization을 장려한다고 주장한다. 직관적으로는 pick up cup과 pick up mug는 완전히 다른 one-hot class가 아니라, language space에서 비슷한 방향에 있는 skill이라는 정보를 skill predictor가 배우게 장려한다는 것이다.
2. Intra-Modal Contrastive Learning, IntraCL
InterCL은 skill predictor output을 language space에 맞추지만 이것만으로는 router가 정말 비슷한 skill에 대해 비슷한 expert를 선택한다고 보장할 수 없다. 그래서 IntraCL은 router logits 자체를 regularize한다. 각 MoE layer $l$에서 sample $i$의 routing logits를 flatten하고 normalize한 값인 $r_i^l= \mathrm{norm}\left(\mathrm{vec}(\Psi_i^l)\right)$을 구하고 이것들에 대한 similarity $\ell^l_{ij} = \langle r_i^l, r_j^l\rangle / \tau_c$를 계산한다. IntraCL은 language-derived weight $w_{ij}$를 사용해서 semantically similar skill들이 비슷한 routing pattern을 갖도록 만든다. 논문은 이를 topology-preserving constraint로 설명하며, language space에서 가까운 skill들이 비슷한 expert subset을 활성화하도록 강제한다고 주장한다. 직관적으로는 approach cabinet과 approach drawer는 object는 다르지만 motor primitive가 유사하므로, expert usage pattern도 비슷해야 한다는 것을 장려하는 것이다.
전체 loss
\[ \mathcal{L} = \mathcal{L}_{diff} + \lambda_{lb}\mathcal{L}_{lb} + \lambda_{inter}\mathcal{L}_{interCL} + \lambda_{intra}\mathcal{L}_{intraCL} \]| Loss | 역할 |
|---|---|
| $\mathcal{L}_{diff}$ | action denoising을 잘하게 함 |
| $\mathcal{L}_{lb}$ | MoE expert load balancing |
| $\mathcal{L}_{interCL}$ | predicted skill embedding을 text skill semantics에 align |
| $\mathcal{L}_{intraCL}$ | semantically similar skill들이 비슷한 routing pattern을 갖도록 align |
전체 inference flow
현재 observation o_t + task instruction g
↓
visual/language encoder
↓
lightweight skill predictor P_phi
↓
predicted skill embedding z_skill
↓
Diffusion Transformer denoiser
↓
MoE router가 skill-conditioned expert selection
↓
denoising 반복
↓
H-step action chunk 생성
↓
robot execution
Experiments
논문은 SMoDP가 skill-aware routing을 통해 multi-task learning, data efficiency, compositional transfer, real-world execution을 개선하는지 확인하기 위해 LIBERO simulation benchmark와 real-world ALOHA 환경에서 실험한다.
Experimental Setup
Simulation에서는 LIBERO-90, LIBERO-10, LIBERO-OBJECT/GOAL, LIBERO-GOAL-OOD를 사용한다. LIBERO-90은 90개의 manipulation task, LIBERO-10은 LIBERO-90의 primitive를 조합한 10개의 long-horizon task로 구성된다. LIBERO-OBJECT/GOAL은 object-centric 및 goal-conditioned generalization을 평가하고, LIBERO-GOAL-OOD는 seen action/object/goal element를 새로운 verb-noun 조합으로 recombine한 OOD setting이다.
Real-world에서는 dual-arm ALOHA 환경에서 Hang Up Tape, Transfer Tape, Put Cup Sleeve on Cup, Handoff Cup 네 가지 bimanual manipulation task를 수행한다. Baseline으로는 DP-T, DP-CNN, QUEST, SDP, MoDE, MoDE(Pretrain)을 사용하고, transfer setting에서는 MoDE+LoRA와 MoDE-scratch를 추가로 비교한다.
Main Results
LIBERO-10/90 multi-task setting에서 SMoDP는 각각 0.95/0.97 success rate를 기록해 MoDE의 0.92/0.91과 MoDE(Pretrain)의 0.94/0.95를 모두 넘어섰다. 이는 단순히 MoE capacity를 늘린 효과라기보다, expert activation을 reusable skill semantics 중심으로 조직한 효과로 해석할 수 있다.
Data efficiency 실험에서도 SMoDP는 LIBERO-90의 task당 demonstration 수를 5/10/25/50개로 줄인 모든 regime에서 MoDE와 MoDE(Pretrain)보다 높은 성능을 보였다. 특히 적은 demonstration만으로도 shared skill structure를 활용할 수 있기 때문에 low-data regime에서 semantic skill supervision의 효과가 크게 나타난다.
Compositional Transfer
Few-shot transfer에서는 LIBERO-90에서 학습한 expert를 freeze하고, target task에서는 skill predictor와 router만 fine-tuning한다. LIBERO-90 → LIBERO-10 transfer에서 SMoDP는 1/5/10-shot setting에서 각각 0.520/0.765/0.840 success rate를 달성했다. LIBERO-OBJECT/GOAL → LIBERO-GOAL-OOD setting에서도 5-shot과 10-shot에서 MoDE+LoRA, MoDE-scratch보다 높은 성능을 보였다. 이는 SMoDP의 expert들이 task-specific module이 아니라 reusable skill module처럼 활용될 수 있음을 보여준다.
Real-world and Ablation
Real-world ALOHA 실험에서는 SMoDP가 네 task 모두에서 MoDE보다 높은 success rate를 보였고, 평균 success rate가 MoDE 47.50%에서 SMoDP 91.25%로 상승했다. 특히 Handoff Cup에서는 MoDE가 0/20인 반면 SMoDP는 20/20을 성공했다.
Ablation에서는 InterCL이나 IntraCL을 제거하면 LIBERO-90 success rate가 각각 0.958, 0.957로 낮아졌고, 둘 다 제거하면 0.946으로 더 떨어졌다. 또한 experts/layer는 4개가 가장 좋았으며, 6개나 8개로 늘린다고 성능이 좋아지지는 않았다. 이는 semantic representation alignment와 routing alignment가 둘 다 중요하고, expert 수를 무작정 늘리면 오히려 training signal이 fragment될 수 있음을 보여준다.
Limitations
1. Verb–noun skill은 coarse하다
<pick up, cup>은 high-level skill label로는 좋지만, force, speed, trajectory, grasp pose, contact dynamics 같은 fine-grained control detail을 담지 못한다.
2. Long-tail skill distribution
논문의 저자들은 frequent primitive가 router를 지배해서 rare skill expert specialization이 약해질 수 있다고 설명한다.
3. VLM annotation 품질에 dependent
motion blur, occlusion, subtle transition이 있으면 boundary가 틀리거나 skill label이 잘못될 수 있다. 논문도 coarse segmentation, excessive granularity, hallucination risk를 limitation으로 언급한다.
4. Additional Observation: Expert 수 증가가 항상 성능 향상으로 이어지지는 않음
Ablation에서 experts/layer를 4에서 6, 8로 늘리면 성능이 오히려 떨어진다.