



WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
multi-view RGB + proprioception + action chunk를 입력으로 미래 latent rollout과 reward/value를 빠르게 예측해, π0.5 같은 VLA policy의 offline evaluation, synthetic-data policy improvement, test-time best-of-N planning을 가능하게 만든 action-conditioned latent world model
Overview Figure

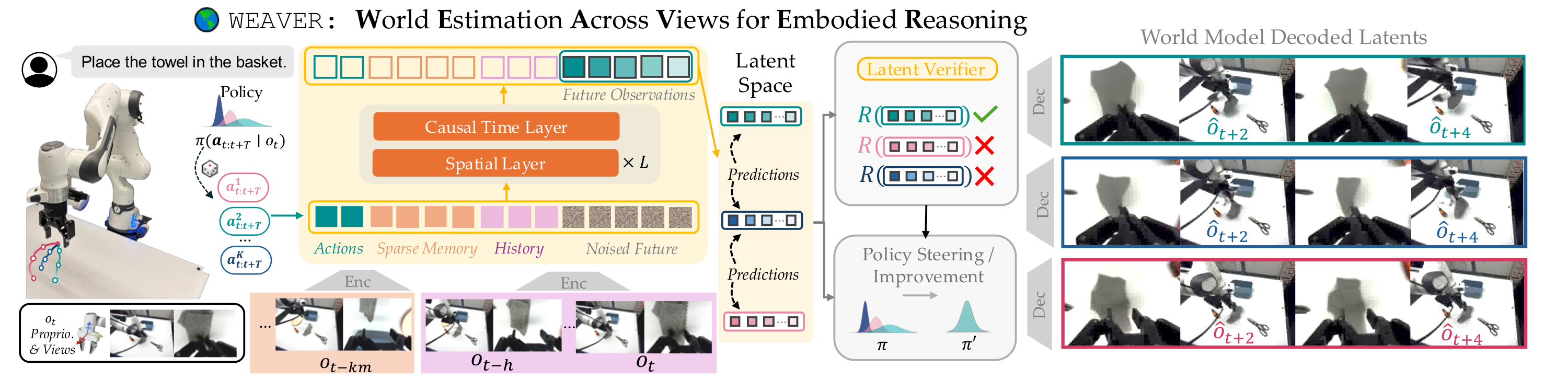
Top-Down Summary
- 기존 robot world model은 fidelity, long-horizon consistency, efficiency를 동시에 만족하지 못해, policy evaluation에는 불충분하거나 test-time planning에는 너무 느렸다.
- WEAVER는 manipulation에서 필요한 multi-view consistency, occlusion reasoning, proprioceptive state prediction, fast latent rollout을 결합해 실제 robot policy의 evaluation / improvement / planning에 사용할 수 있는 world model을 만드는 것이 목표다.
- 핵심 아이디어는 image-space video generation을 매번 수행하지 않고, Stable Diffusion 3 VAE latent space에서 action-conditioned future latent를 flow matching + diffusion forcing으로 예측하고, reward/critic도 latent에서 바로 계산하는 것이다.
- Architecture는 sparse long-term memory, short-term history, action tokens, spatial attention + causal temporal attention transformer, reward head, critic head, action adapter, optional decoder로 구성된다.
- 실험에서 WEAVER는 Ctrl-World보다 FID/FVD와 inference time에서 우세하고, WEAVER-FT는 policy evaluation에서 real-world success와 Spearman $\rho = 0.870$ / Pearson $r = 0.863$ correlation을 보이며, synthetic/mixed data fine-tuning과 test-time steering에서도 $\pi_{0.5}$ 성능을 개선한다.
Input
WEAVER가 다루는 timestep $t$의 observation은 다음과 같다:
\[o_{t} := (\mathbf{I}_{t}, q_{t})\]여기서 $\mathbf{I}_{t} := (I^{1}, \dots , I^{n})$는 multi-view RGB images이고, $q_{t} \in \mathbb{R}^{8}$은 robot proprioceptive state이다. 추가적인 input은 다음과 같다:
- natural language instruction $l$
- sparse long-term memory latents $\mathbf{z}_{\text{t}}^{\text{mem}}$
- short-term history latents $\mathbf{z}_{\text{t}}^{\text{hist}}$
- candidate action chunk $\mathbf{a}_{t} := a_{t:t + h}$
- flow denoising timestep $\tau$
- noisy future latent $x_{t}^{\tau} = \tau x_{t}^{1} + (1 - \tau) x_{t}^{0}$
Output
WEAVER의 key output은 아래와 같다:
\[\hat{\mathbf{z}}_{t+1:t+h+1}\]즉, future latent trajectory이다. 필요한 경우 pretrained decoder $\mathcal{D}_{\eta}$로 decoded future observations $\hat{\mathbf{o}}_{t} := \hat{o}_{t + 1 : t + h + 1}$를 얻고, reward head $R$과 critic $V$로 imagined rollout의 task progress와 value를 계산한다.
Problem Definition
이 논문은 다음 문제들을 동시에 다룬다:
- robot control을 위한 action-conditioned world modeling
- policy evaluation
- synthetic data generation for policy improvement
- test-time planning / policy steering
- long-horizon multi-view manipulation rollout prediction
Closed-loop control pipeline에서 보면 WEAVER는 policy와 environment 사이에 들어가는 imagined rollout evaluator이다.
real observation
→ π0.5 samples action chunks
→ WEAVER imagines future latent outcomes
→ reward/critic computes advantage
→ choose / distill / evaluate action sequence
→ execute selected chunk or update policy
기존 방법의 한계
| 관점 | 기존 한계 |
|---|---|
| Architecture | video generation WM은 fidelity는 좋을 수 있지만 latency가 크고, JEPA-style latent WM은 decoded image를 제공하기 어려워 arbitrary visuomotor policy evaluation에 제한이 있다. |
| Objective | image reconstruction/video fidelity만으로는 robot task success와 직접 연결되지 않는다. reward/value estimation이 없으면 planning/evaluation에 추가 judge가 필요하다. |
| Action representation | robot action이 velocity, position, EE pose 등으로 다르고, action-conditioned rollout 품질이 representation에 민감하다. |
| Data/generalization | DROID 같은 large robot data도 특정 embodiment/camera setup 편향을 가진다. granular/deformable dynamics는 부족하다. |
| Dynamics/world model | occlusion, wrist-camera viewpoint change, gripper-object contact, deformable object dynamics에서 long-horizon consistency가 깨진다. |
| Inference-time planning | Ctrl-World 같은 모델은 candidate action 여러 개를 평가하기에는 너무 느리다. |
| Real robot deployment | high-frequency closed-loop가 아니라 chunk-level planning이며, latency가 여전히 single-chunk lookahead로 제한한다. |
| Closed-loop robustness | model error와 reward error를 planner가 exploit할 가능성이 있고, uncertainty modeling이 없다. |
Main Idea
기존 가정:
좋은 world model = 미래 video를 잘 생성하는 model
문제:
robot manipulation에서는 visual plausibility만으로 부족하다.
정확한 gripper/object contact, proprioception, occluded state, task reward, planning latency가 필요하다.
새 관점:
robot world model은 future image generator가 아니라,
action-conditioned latent simulator + latent verifier + policy steering module이어야 한다.
모델 반영:
multi-view latent encoding
+ sparse memory / short-term history
+ flow-matching latent dynamics
+ diffusion forcing
+ proprio prediction
+ latent reward/critic
+ fast inference engineering
robot behavior 변화:
π0.5가 여러 action chunk를 낼 때,
WEAVER가 각 candidate의 미래 결과를 상상하고,
reward/value 기준으로 더 나은 chunk를 고르거나,
좋은 imagined segment를 policy fine-tuning data로 만든다.
Preliminaries
Diffusion Forcing
Diffusion forcing은 future timestep마다 noise level을 독립적으로 줄 수 있게 학습하는 방식이다. 일반 sequence diffusion이 전체 future sequence를 같은 noise level로 다루는 것과 달리, diffusion forcing은 long-horizon prediction에서 일부 timestep은 거의 clean, 일부 timestep은 noisy 상태로 학습할 수 있다. 그래서 모델은 “어떤 미래는 거의 확정되어 있고, 어떤 미래는 아직 매우 noisy한 상태”를 동시에 다루도록 학습된다.
Architecture
| 모듈 | 입력 | 출력 | 역할 |
|---|---|---|---|
| Pretrained encoder $\mathcal{E}_{\psi}$ | multi-view RGB, proprioception | latent $z_t$ | observation을 latent patch tokens + proprio token으로 변환 |
| Sparse memory | every $k$-th prior latent | $\mathbf{z}_{\text{t}}^{\text{mem}}$ | long-term scene context 유지 |
| Short-term history | recent latents, 논문상 주로 last two frames | $\mathbf{z}_{\text{t}}^{\text{hist}}$ | 최근 action consequence와 local motion 포착 |
| Action adapter | $\pi_{0.5}$ joint velocity chunk + current joint/gripper state | joint/gripper position deltas | $\pi_{0.5}$ action space와 WEAVER action conditioning space 연결 |
| Latent dynamics $f_{\phi}$ | $\mathbf{z}_{\text{t}}^{\text{mem}}$, $\mathbf{z}_{\text{t}}^{\text{hist}}$, action chunk, noisy future latent, flow timestep | future latent velocity / denoised future latents | action-conditioned future latent rollout |
| Decoder $\mathcal{D}_{\eta}$ | future latent | future multi-view observations/proprio | policy evaluation 또는 visualization을 위한 decoding |
| Reward head $R$ | imagined latent + language | reward/progress | candidate action scoring |
| Critic $V$ | latent + language | value | truncated rollout 이후 return bootstrap |
| Base policy $\pi_{0.5}$ | real or imagined observation + language | action chunk | candidate action generation |
Forward / Inference Pass
World model rollout
- 현재 real observation $o_{t} = (\mathbf{I}_{t}, q_{t})$를 받는다.
- Stable Diffusion 3 VAE encoder로 각 camera view를 patch latent로 바꾼다.
- proprioceptive state $q_{t}$를 같은 token dimension으로 project한다.
- visual latent tokens와 proprio token을 concatenate해 $z_{t}$를 만든다.
- 과거 latent에서 sparse memory $\mathbf{z}_{\text{t}}^{\text{mem}}$과 short-term memory $\mathbf{z}_{\text{t}}^{\text{hist}}$를 만든다.
- candidate action chunk $\mathbf{a}_{t} = a_{t:t + h}$를 입력한다.
- noisy future latent $x_{t}^{\tau} = \tau x_{t}^{1} + (1 - \tau) x_{t}^{0}$와 flow timestep $\tau$를 넣고 dynamics transformer $f_{\phi}$가 velocity를 예측한다.
- 여기서 $x_{t}^{1}$은 training target인 ground-truth future latent이고, inference에서는 알 수 없다. 따라서 실제 inference에서는 Gaussian noise에서 시작해 learned velocity field를 따라 integration하면서 clean future latent 방향으로 이동한다.
- denoising / flow integration을 통해 future latents $\hat{\mathbf{z}}_{t+1:t+h+1}$을 얻는다.
- 필요하면 decoder로 future observations를 얻는다.
- reward head와 critic으로 imagined sequence를 score한다.
Dynamics transformer를 학습할 때 diffusion forcing이 사용된다. 즉 future timestep마다 독립적인 noise level을 sampling해 long-horizon rollout consistency를 높인다. 이는 10s~40s rollout에서 compounding error를 줄이기 위함이다. 논문의 저자들은 이것이 long-horizon consistency에 기여한다고 주장한다.
Reward head는 off-the-shelf RoboMeter score를 latent에서 직접 예측하도록 MSE로 학습된다. Critic은 $\lambda$-return을 target으로 MSE로 학습한다.
ReFlow post-training loss에서는 WEAVER-FT teacher가 multi-step denoising으로 만든 high-quality latent trajectory $\hat{x}_t^1$를 target으로 삼아 student를 빠르게 distill한다.
$\pi_{0.5}$는 joint velocity command를 출력하지만, WEAVER는 joint-position difference conditioning을 선호한다. 그래서 action adapter는 current state와 $T=15$ action tokens를 받아 future joint/gripper deltas를 예측한다. gripper는 dynamic range가 작지만 grasp/place에 중요하므로 up-weight된다.
Test-time planning
- real observation과 instruction이 들어온다.
- $\pi_{0.5}$가 $B$개의 action chunk를 sample한다.
- action adapter가 $\pi_{0.5}$의 joint velocity command를 WEAVER가 선호하는 joint-position style action으로 변환한다.
- WEAVER가 각 chunk의 future latent를 imagine한다.
- reward/critic으로 advantage를 계산한다.
- 가장 높은 advantage의 chunk를 실제 robot에 실행한다.
- 다음 real observation에서 다시 반복한다.
논문에서의 test-time planning은 $B=4$, imagination horizon $h=12$를 사용했다.
Training Data
| 데이터 | 용도 | 구성 |
|---|---|---|
| DROID | WEAVER pretraining | large-scale robot manipulation data |
| Task fine-tuning data | WEAVER-FT | 5 tasks × 50 rollouts = 250 rollouts |
| Evaluation data | policy evaluation / OOD eval | 5 tasks × 20 rollouts = 100 rollouts |
| RoboMeter labels | reward head / critic training | per-frame progress reward, 1fps inference 후 interpolation |
| 50h proprioceptive teleoperation data | action adapter training | current state + T=15 action chunk → future joint/gripper deltas |
| WEAVER synthetic rollouts | $\pi_{0.5}$ policy improvement | advantage-filtered imagined segments |
Tasks는 Stack Bowls, PnP Bag, PnP Marker, PnP Towel, Pour Beans이다. 이들은 rigid pick-and-place, deformable object manipulation, dynamic/granular manipulation을 포함한다.
Training Regime
| 항목 | 판단 |
|---|---|
| Training regime | Pretraining + Fine-tuning + Auxiliary-model Training + Component Scratch Training + ReFlow post-training + Inference-time Method + Data-generation Framework |
| 학습되는 것 | WEAVER latent dynamics model, reward head, critic, action adapter, ReFlow student, downstream $\pi_{0.5}$ fine-tuned policy |
| 고정되는 것 | Stable Diffusion 3 VAE encoder/decoder로 보이는 pretrained visual latent component, CLIP text embedding, RoboMeter reward source, evaluation/planning 시 base $\pi_{0.5}$ |
| pretrained model 사용 | Stable Diffusion 3 VAE, CLIP embedding, RoboMeter, DROID-pretrained $\pi_{0.5}$ |
| 새로 생성/활용하는 데이터 | 250 real task rollouts for WEAVER-FT, 100 real evaluation rollouts, WEAVER-generated synthetic segments for policy fine-tuning |
| Inference-time modification | KV cache, noise schedule selection, ReFlow acceleration, latent reward/critic scoring, best-of-N action chunk selection |
| 핵심 분류 | WEAVER는 VLA 자체라기보다, VLA policy를 평가/개선/steering하기 위한 action-conditioned latent world model이다. |
Experiment Takeaway
실험적으로 WEAVER의 핵심 claim은 꽤 잘 뒷받침된다.
| Claim | 실험 근거 | 해석 |
|---|---|---|
| Better fidelity | FID/FVD/LPIPS에서 Ctrl-World보다 우세 | pretrained SD3 latent + flow objective + multi-view design이 효과적 |
| Longer consistency | 10s rollout에서 낮은 FID 유지 | sparse memory와 short-term history가 occlusion / viewpoint shift에 도움 |
| Faster generation | 같은 NFE에서 Ctrl-World보다 훨씬 낮은 inference time | KV cache, SPRINT, schedule, ReFlow가 실용적 |
| Policy evaluation 가능 | WEAVER-FT Spearman 0.870 / Pearson 0.863 | real policy success ranking에 꽤 강하게 correlate |
| Synthetic data improvement 가능 | mixed data FT 평균 0.82 success rate | imagined high-advantage segments가 policy fine-tuning에 유효 |
| Test-time planning 가능 | base 0.44 → steering 0.58 | policy update 없이 inference-time best-of-N으로 성능 개선 |
가장 중요한 점은 WEAVER가 world model을 단순한 video predictor로 두지 않고, latent reward/critic을 붙여 policy evaluation, policy improvement, test-time planning으로 연결했다는 것이다.
반대로 가장 조심해서 읽어야 할 점은, real-time closed-loop라는 표현을 너무 강하게 해석하면 안 된다는 것이다. WEAVER는 아직 high-frequency controller가 아니라, VLA policy 위에서 동작하는 slow but useful latent imagination module에 가깝다.
Limitations
| 한계 | 내용 |
|---|---|
| Partial observability | visual observation만으로 contact, grasp stability, force, occluded geometry를 알 수 없음 |
| Complex deformable/dynamic interaction | towel, bag, granular beans 같은 dynamics는 limited data에서 예측이 어려움 |
| Limited test-time planning horizon | latency 때문에 online planning이 single action chunk로 제한됨 |
| Data coverage / embodiment diversity | DROID 중심이라 robot embodiment, camera configuration, end-effector generalization이 제한될 수 있음 |
| Noisy reward supervision | RoboMeter-derived reward labels가 subtle failure를 놓칠 수 있음 |
Additional Points
-
policy improvement의 큰 성능 향상은 world model architecture만의 효과가 아니라, task-specific WEAVER-FT와 RoboMeter-based advantage filtering, 그리고 $\pi_{0.5}$ fine-tuning이 함께 만든 결과다. 따라서 “pretrained world model alone으로 robot policy를 크게 개선했다”고 읽으면 과장이다.
-
test-time planning은 high-frequency closed-loop control이 아니다. Batch size 4, horizon 12에서도 dynamics prediction만 약 1.25s가 걸리며, policy sampling까지 포함하면 약 1.45s 수준이다. 따라서 WEAVER는 fast reactive controller라기보다 chunk-level candidate selector에 가깝다.
-
reward/critic이 latent에서 빠르게 동작하는 것은 큰 장점이지만, RoboMeter reward supervision 자체가 noisy하면 model-based planning과 synthetic data filtering이 잘못된 방향으로 갈 수 있다. 특히 PnP Marker처럼 fine-grained placement accuracy가 중요한 task에서는 reward model이 subtle failure를 놓칠 수 있다.
-
action representation은 Franka/DROID setup에 강하게 묶여 있다. $\pi_{0.5}$의 joint velocity action을 joint-position difference로 변환하는 adapter는 실용적인 engineering choice지만, multi-embodiment generalization을 직접 해결하지는 않는다.