



DAM-VLA: Decoupled Asynchronous Multimodal Vision Language Action model
VLA의 synchronous clock 가정이 contact-rich manipulation의 multi-rate sensor structure와 맞지 않는다고 보고, modality별 asynchronous latent buffer + gated cross-attention으로 X-VLA를 100 Hz controller 기반 closed-loop execution에 맞춘다
Overview Figure
Top-Down Summary
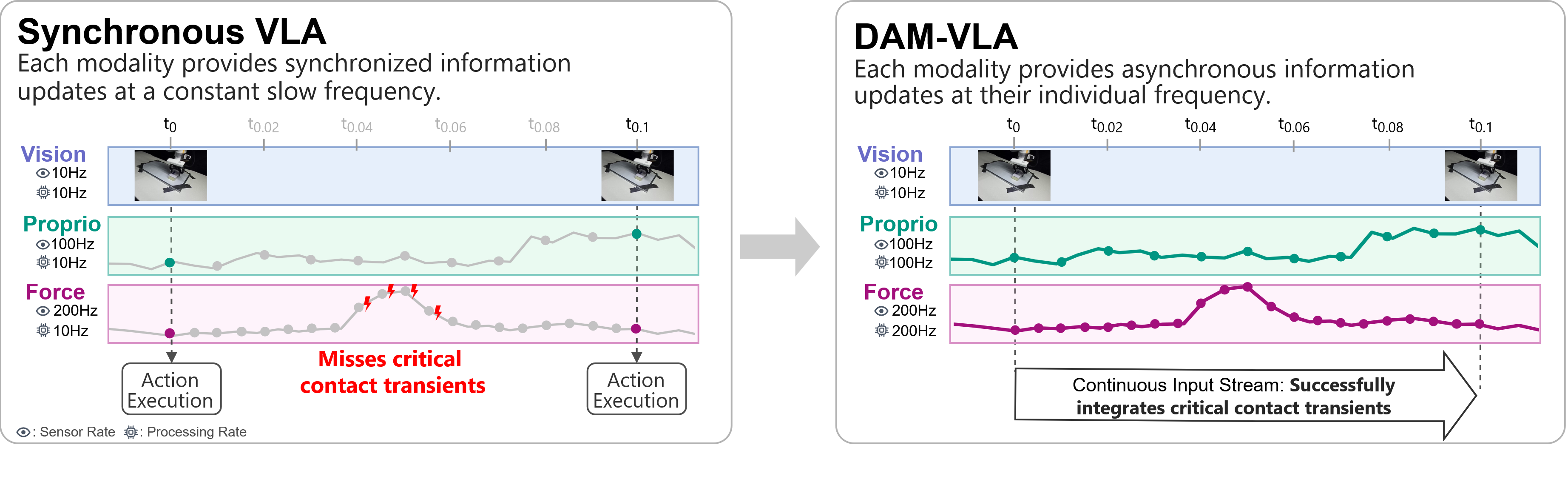
- 기존 VLA는 vision-language pretraining에서 온 single synchronous clock 가정을 그대로 사용해, 느린 vision은 과도하게 재처리하고 빠른 force/torque contact transient는 놓치는 문제가 있다.
- 이 논문은 physical interaction에서 modality마다 의미 있는 update rate와 temporal horizon이 다르다는 점, 예를 들어 force/torque는 100–500 Hz 수준의 contact transient를 담고 RGB는 훨씬 느리게 변한다는 점에 주목한다.
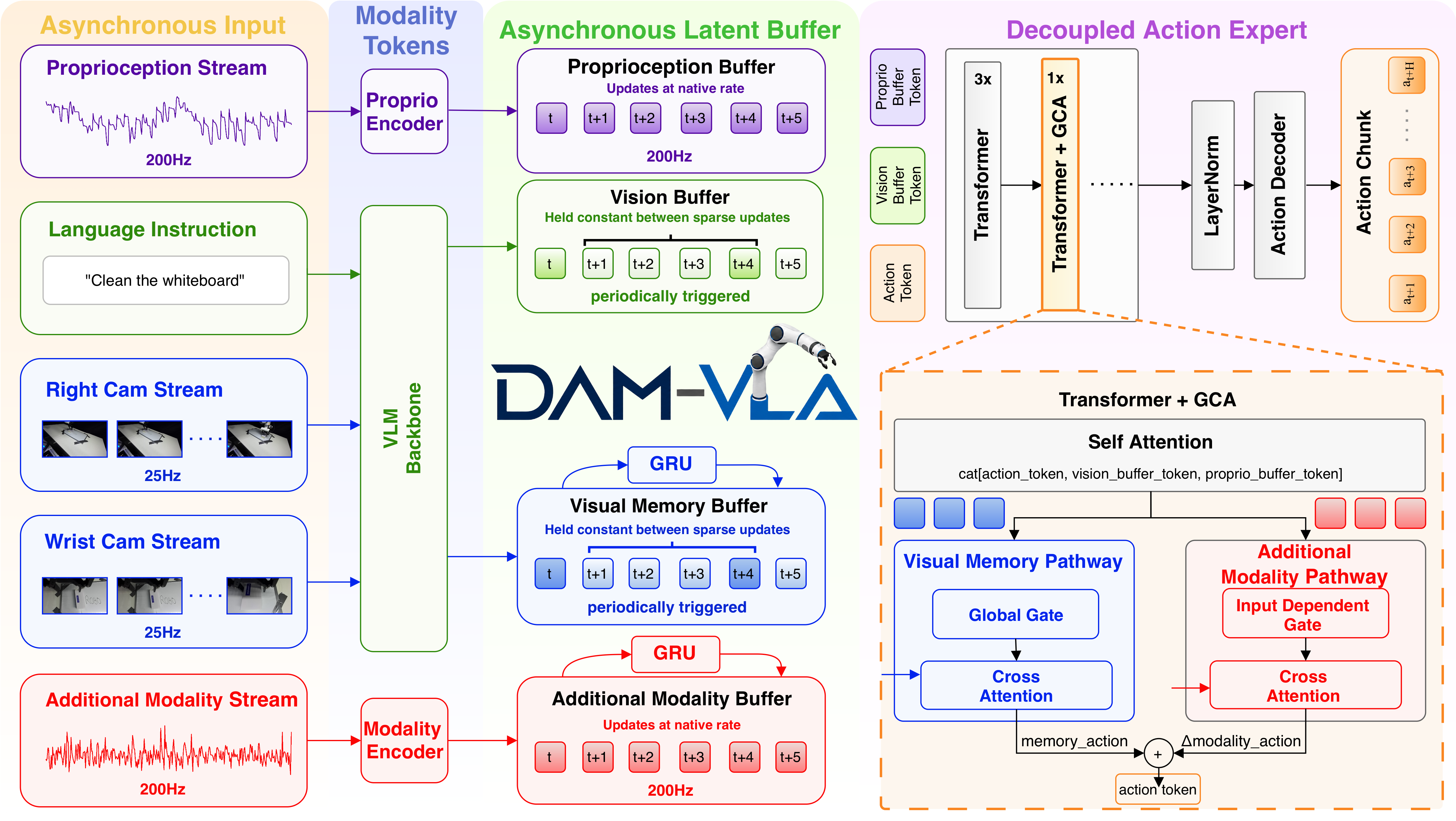
- 핵심 아이디어는 각 modality를 하나의 token sequence로 강제 concat하지 않고, per-modality latent buffer를 sensor rate별로 갱신한 뒤 action expert가 매 inference step에서 이를 읽게 하는 것이다.
- 모델 구조는 X-VLA backbone 위에 visual memory pathway와 force/torque pathway를 추가한다. 새로운 modality token을 pretrained self-attention에 직접 concat하지 않고, gated cross-attention, GCA residual pathway로 action tokens만 조절한다.
- Franka Panda 기반 7개 real-world contact-rich task에서 DAM-VLA는 평균 성공률 95.2%를 달성해 strongest synchronous baseline인 X-VLA25의 40.95%를 크게 넘었고, 100 Hz controller에서 smooth하고 reactive한 실행을 보였다.
- 다만 force/torque는 action chunk 내부를 직접 수정하는 feedback controller로 쓰이는 것이 아니라 representation을 보강하는 용도라, very contact-heavy task에서는 mid-chunk correction 한계가 남는다.
input
| Modality | 논문 설정 | Rate / Horizon |
|---|---|---|
| Language instruction | episode 동안 고정된 task instruction | episode 시작 시 1회 encoding |
| Third-person RGB camera | fixed scene camera (256×256) | 25 Hz |
| Wrist RGB camera | end-effector 근처 wrist camera (256×256) | 25 Hz |
| Proprioception | 7 joint positions + gripper state, 총 8-D | 100 Hz |
| Force/torque | Franka internal estimate 기반 7-D external joint torque 사용 | 100 Hz |
| Action | 7-D joint position + 1-D gripper state, 총 8-D action | 100 Hz controller에서 실행 |
output
Output은 8-D robot action이다. 7차원은 joint position command, 나머지 1차원은 gripper state이다. action chunk horizon s를 사용해 일정 길이의 action chunk를 실행하고 replanning한다. 100 Hz controller에서 DAM-VLA는 약 5.5 Hz로 replanning했고, 200 Hz controller에서는 s=22일 때 약 8 Hz, s=6일 때 약 17 Hz replanning으로 실험을 진행했다.
closed-loop pipeline
Sensor streams
├─ language: once
├─ RGB cameras: 25 Hz, cached / periodically refreshed
├─ proprioception: 100 Hz
└─ force/torque: 100 Hz
↓
Per-modality encoders
↓
Asynchronous latent buffer B = {Z^m}
↓
X-VLA action expert + Gated Cross-Attention
↓
8-D action chunk
↓
100 Hz low-level robot controller
↓
new sensor feedback updates buffers
기존 방법의 한계
Architecture 관점에서, 기존 synchronous VLA는 모든 modality를 하나의 observation bundle로 묶어 같은 timestep에 처리한다. 이 설계는 VLM pretraining에서는 자연스럽지만 robot control에는 부적합하다. 논문의 저자들은 force/torque는 contact transient를 100-500Hz에서 포착하고 RGB는 훨씬 느리게 변한다고 주장한다. 핵심 문제를 정리하면 아래와 같다:
- Redundant compute
- 거의 변하지 않은 RGB frame을 매 step VLM encoder에 넣는다.
- Cross-modal rate mismatch
- fast modality는 undersampling되고 slow modality는 oversampling된다.
- Action latency
- policy가 complete synchronized observation bundle을 기다리므로 slowest modality가 action generation을 막는다.
Objective / data 관점에서, naive high-frequency baseline인 $\text{X-VLA}_{100}$은 visual observation을 100 Hz로 upsample한다. 이 경우 동일한 visual frame이 서로 다른 action label과 pairing되며, 논문의 저자들은 이것이 contradictory training signal을 만들고 policy가 small hesitant movements를 예측하게 만든다고 주장한다. 즉, control frequency를 25 Hz에서 100 Hz로 단순하게 올리는 것은 해결책이 아니다. data alignment 자체가 action supervision을 오염시킬 수 있다.
Action representation / chunking 관점에서, 기존 VLA는 heavy VLM latency 때문에 action generation rate가 낮다. action chunking은 이를 완화하지만, chunk execution 중 high-frequency force feedback이 action correction에 직접 쓰이지 않으면 contact-rich task에서 mid-chunk error를 고치지 못한다. DAM-VLA도 이 한계를 완전히 해결하지는 않는다. 저자도 force를 “better representation”에는 쓰지만 chunk 내부 action correction에는 쓰지 않는다고 한계로 인정한다.
Real robot deployment 관점에서, real robot에서는 sensor마다 update rate가 다르고, 특히 contact-rich manipulation은 millisecond-level contact event에 민감하다. synchronous VLA는 이 이벤트를 놓치거나 늦게 반영한다.
main idea
기존 가정:
모든 modality는 같은 timestep에서 함께 처리하면 된다.
문제:
실제 robot sensor는 rate와 temporal horizon이 다르다.
vision은 느리게 변하고, force는 빠르게 변하며, language는 episode 동안 고정된다.
새 관점:
VLA는 synchronous multimodal token processor가 아니라
multi-rate sensorimotor controller여야 한다.
구현:
modality별 latent buffer를 만들고,
각 buffer를 sensor rate에 맞춰 refresh하며,
action expert가 모든 buffer를 계속 읽는다.
새 modality는 concat하지 않고 GCA residual로 주입한다.
행동 변화:
redundant frame bias가 줄고,
contact termination이 좋아지며,
repeated pressing / stalling / misalignment가 줄어든다.
핵심은 “센서를 더 넣는다”가 아니라 “센서마다 다른 시간 구조를 모델 구조에 반영한다”이다.
Preliminaries
Latent buffer / memory
Latent buffer는 raw sensor data를 매번 다시 처리하지 않고, encoder를 통과한 latent token representation을 modality별로 저장해 두는 cache다. buffer가 raw image나 raw force vector만 들고 있는 것이 아니라, model이 쓰기 좋은 형태의 latent tokens를 들고 있다.
Memory는 단순히 최신 1개 latent만 저장하는 것이 아니라, 최근 여러 timestep의 정보를 모아 temporal context로 만드는 것이다. 예를 들어 visual memory는 최근 $K$개의 visual embedding을 보관한다. 그 다음 GRU나 learned-query cross-attention 같은 compressor를 써서 고정된 수의 memory tokens로 압축한다.
Gated Cross-Attention(GCA)
Cross-attention에서 action token이 query가 되고, memory / force / modality token이 key-value가 된다. 즉, action expert가 “내가 지금 action을 만들려면 어떤 memory나 force 정보가 필요하지?”라고 물어보는 구조다. GCA는 cross-attention output을 action token에 바로 더하지 않고, gate를 곱해서 residual로 넣는다. Gate가 0에 가까우면 외부 modality를 거의 무시한다는 뜻이고, 1에 가까우면 외부 modality를 강하게 반영한다는 뜻이다. GCA는 action expert가 필요할 때만 memory나 force 정보를 residual correction으로 받게 하는 구조이다.
Architecture & Pathways
X-VLA backbone
DAM-VLA의 contribution은 X-VLA 위에 asynchronous multimodal buffer와 GCA integration을 얹는 것이다.
Language pathway
Language는 high-frequency update가 필요 없는 modality로 취급되기 때문에 language instruction은 episode 시작 시 한 번 encoding되어 해당 episode 동안 static context로 유지된다.
Vision pathway
Input은 third-person RGB camera, wrist-mounted RGB camera이다. 처리 과정은 아래와 같다:
- RGB image를 VLM / vision-language encoder에 넣어 patch tokens 생성
- 매 control step마다 re-encoding하지 않고, 주기적으로 refresh
- 새 visual embedding을 rolling buffer에 append
- GRU가 $K$개 최근 visual embedding을 encode
- learned-query cross-attention으로 $N_{\text{mem}}$ memory tokens로 compress
- $Z^{\text{mem}}$ 생성
Proprioception pathway
Input은 7D joint positions, 1D gripper state이다. X-VLA처럼 action tokens와 concatenation되는 방식으로 사용된다. full 100 Hz control rate로 읽히며 asynchronous latent buffer에서 처리된다.
Force / torque pathway
Input은 7-D external joint-torque estimates이다. 처리 과정은 아래와 같다:
- 100 Hz joint-torque readings 수신
- EMA(exponential moving average) smoothing
- rolling buffer에 누적
- GRU로 force history encoding
- force registers에 대한 cross-attention으로 $Z^{\text{ft}}$로 compress
- 매 control step visual schedule과 독립적으로 update
Shared asynchronous latent buffer
\[\mathcal{B} = \\\{ Z^{m} \\\}_{m \in \mathcal{M}}\]각 modality는 별도 token sequence를 갖는다:
- vision buffer: sparse update
- visual memory buffer: rolling memory
- force buffer: high-frequency update
- proprioception buffer: high-frequency update
- language buffer: episode-level static
action head는 buffer 전체를 읽지만, buffer를 consume하지 않는다. sensor update가 없으면 이전 latent가 그대로 유지된다.
Decoupled action expert + GCA
DAM-VLA는 naive concat 대신 GCA를 사용한다:
- visual memory pathway: global gate
- force/additional modality pathway: input-dependent gate
- insertion point: action expert의 every 4th transformer layer
- residual injection: action tokens에만 correction 주입
Training data
| 항목 | 내용 |
|---|---|
| Robot | Franka Emika Panda 7-DoF + Robotiq 2F-85 gripper |
| Cameras | third-person RGB + wrist RGB |
| RGB rate | 25 Hz |
| RGB size | 256×256 |
| Proprioception | 8-D, 7 joint positions + gripper state |
| Force/torque | Franka internal estimate; method는 7-D external joint torque 사용 |
| Action | 8-D, 7 joint positions + 1-D gripper state |
| Data size | task당 50–60 real-world episodes |
| Format | LeRobot-style synchronized observations, actions, timestamps, frame indices |
| Tasks | Scarf, Whiteboard, Button, Handwash, Lego, Socket, Sweep |
Training regime & objective
| 항목 | 판단 |
|---|---|
| Training regime | Fine-tuning + Component Scratch Training + Inference-time Asynchronous Scheduling |
| Pretrained model | X-VLA backbone 사용 |
| 학습되는 component | vision encoders, action experts, visual memory pathway, force/torque pathway, GCA modules, gates |
| 새로 붙는 component | GRU-based visual memory encoder, force history encoder, learned-query cross-attention compressor, gated cross-attention pathway |
| 고정되는 component | 논문은 pretrained self-attention structure를 보존한다고 설명하지만, 전체 backbone freeze 여부를 명확히 말하지는 않는다. Appendix 기준으로는 vision encoders와 action experts를 finetune한다. |
| 데이터 | task당 50–60 real-world demonstration episodes |
| Inference-time 핵심 | visual tokens는 caching 후 주기적으로 refresh하고, force/proprioception은 high-frequency buffer로 갱신한다. action expert는 매 inference step에서 buffer를 읽는다. |
| 정확한 loss | 논문은 policy가 8-D action을 예측하도록 학습된다고 설명하지만, action prediction loss의 정확한 수식은 명시하지 않는다. 따라서 이 글에서는 X-VLA 기반 imitation fine-tuning으로만 해석한다. |
이 논문은 scratch training 논문이 아니다. X-VLA를 기반으로 finetuning하면서, asynchronous buffer와 GCA pathway를 추가하는 구조다. 따라서 핵심은 새로운 foundation model pretraining이 아니라 pretrained VLA를 real-time, multi-rate, contact-rich control setting에 맞게 재구성하는 것이다.
Experiments
Evaluation setup
DAM-VLA는 Franka Emika Panda 7-DoF arm과 Robotiq 2F-85 gripper에서 평가된다. Sensor suite는 fixed third-person RGB camera, wrist-mounted RGB camera, proprioception, force/torque로 구성된다. RGB streams는 25 Hz로 기록되고, proprioception과 force/torque는 100 Hz로 기록된다. Force/torque는 dedicated F/T sensor가 아니라 Franka internal estimate에서 얻은 external joint torque를 사용한다.
평가 task는 총 7개다.
| Task | 요구되는 능력 |
|---|---|
| Scarf folding | deformable object handling, sequential folding |
| Whiteboard cleaning | sustained contact, repeated wiping motion |
| Button pressing | contact detection, press termination |
| Handwash top press | contact depth control, repeated press 방지 |
| Lego piece arranging | precise alignment, object placement |
| Socket insertion | high-precision contact-rich insertion |
| Sweep beads into dustpan | long continuous motion, smooth trajectory |
Metric은 주로 task success rate다. 각 configuration은 task당 15 trials로 평가된다. Appendix에서는 추가로 episode length, SPARC command smoothness, tracking lag, 200 Hz controller에서의 replanning frequency ablation을 분석한다.
Baselines and ablations
논문은 모든 configuration이 같은 X-VLA backbone, 같은 training data, 같은 task split을 사용하도록 맞춘다. 따라서 비교의 핵심은 synchronous vs. asynchronous, force/memory 사용 여부, concat vs. GCA integration이다.
표기에서 주의할 점은 /F, /M suffix가 해당 component를 제거한 ablation처럼 읽힌다는 점이다. 즉, DAM-VLA/F는 force가 빠진 memory-only model이고, DAM-VLA/M은 memory가 빠진 force-only model이다.
| Model | 의미 | Async | Force | Memory | Integration |
|---|---|---|---|---|---|
X-VLA25 | standard synchronous VLA regime at 25 Hz | ✗ | ✗ | ✗ | 기존 X-VLA |
X-VLA100 | naive high-frequency synchronous VLA at 100 Hz | ✗ | ✗ | ✗ | 기존 X-VLA |
X-VLA_AFM | async + force + memory 정보를 flat token sequence로 concat | ✓ | ✓ | ✓ | Concatenation |
DAM-VLA/F/M | async decoupling only | ✓ | ✗ | ✗ | 없음 |
DAM-VLA/F | memory-only contribution | ✓ | ✗ | ✓ | GCA |
DAM-VLA/M | force-only contribution | ✓ | ✓ | ✗ | GCA |
DAM-VLA | full model | ✓ | ✓ | ✓ | GCA |
100 Hz controller 기준으로 X-VLA25와 X-VLA100은 각각 약 1 Hz, 3.5 Hz 수준으로 replanning한다. Full DAM-VLA는 action chunk horizon s=22를 사용해 약 5.5 Hz로 replanning하면서 100 Hz controller 위에서 실행된다.
Main quantitative results
| Model | Scarf | Whiteboard | Button | Handwash | Lego | Socket | Sweep | Avg. |
|---|---|---|---|---|---|---|---|---|
X-VLA25 | 80.0 | 86.7 | 13.3 | 0.0 | 0.0 | 6.7 | 100.0 | 40.95 |
X-VLA100 | 80.0 | 13.3 | 6.7 | 0.0 | 0.0 | 0.0 | 53.3 | 21.9 |
X-VLA_AFM | 100.0 | 73.3 | 13.3 | 86.7 | 0.0 | 6.7 | 100.0 | 54.3 |
DAM-VLA/F/M | 80.0 | 66.7 | 40.0 | 20.0 | 0.0 | 6.7 | 66.7 | 40.0 |
DAM-VLA/F | 100.0 | 73.3 | 86.7 | 40.0 | 0.0 | 6.7 | 100.0 | 58.1 |
DAM-VLA/M | 100.0 | 86.7 | 86.7 | 80.0 | 13.3 | 13.3 | 86.7 | 66.7 |
DAM-VLA | 100.0 | 100.0 | 93.3 | 100.0 | 93.3 | 80.0 | 100.0 | 95.2 |
가장 중요한 결과는 full DAM-VLA가 평균 성공률 95.2%를 기록했다는 점이다. 가장 강한 synchronous baseline인 X-VLA25는 40.95%, naive 100 Hz synchronous baseline인 X-VLA100은 21.9%에 그친다. 즉, 이 논문에서 성능 향상은 단순히 controller frequency를 올려서 얻은 것이 아니라, multi-rate sensor streams를 asynchronous latent buffer와 GCA로 통합한 architecture 변경에서 온다.
RQ1. Synchronous processing은 frequency scaling으로 해결되지 않는다
X-VLA25는 평균 40.95%를 달성한다. Whiteboard cleaning과 Sweep처럼 visual guidance와 smooth motion이 중요한 task에서는 각각 86.7%, 100.0%로 꽤 잘한다. 하지만 contact precision이 중요한 Handwash, Lego, Socket에서는 거의 실패한다.
흥미로운 점은 X-VLA100이 더 높은 control frequency를 쓰는데도 평균 성공률이 21.9%로 더 낮아진다는 것이다. 특히 Whiteboard는 86.7%에서 13.3%로, Sweep은 100.0%에서 53.3%로 크게 떨어진다.
논문의 해석은 명확하다. X-VLA100은 visual frame을 100 Hz action timeline에 맞추기 위해 upsampling한다. 그러면 동일한 image frame이 서로 다른 action label과 pairing된다. 이 redundant-frame bias는 contradictory supervision을 만들고, policy가 큰 동작을 확실히 실행하기보다 작은 hesitant movement를 반복하게 만든다.
핵심 교훈은 다음이다.
Real-time robot control에서 frequency만 올리는 것은 답이 아니다. Observation update rate, action label rate, representation memory horizon을 분리해야 한다.
RQ2. Asynchronous decoupling alone은 naive 100 Hz collapse를 회복한다
DAM-VLA/F/M은 force도 memory도 없이 asynchronous decoupling만 적용한 모델이다. 평균 성공률은 40.0%로 X-VLA25의 40.95%와 거의 비슷하고, X-VLA100의 21.9%보다는 훨씬 높다.
이 결과는 visual encoding을 매 control step마다 반복하지 않고, sparse update + cache 방식으로 분리하는 것만으로도 naive high-frequency training의 collapse를 상당히 줄일 수 있음을 보여준다.
다만 DAM-VLA/F/M은 Sweep에서 66.7%로 X-VLA25의 100.0%보다 낮다. 이유는 visual memory pathway가 없기 때문에 sparse visual update 사이에서 task progress를 안정적으로 유지하지 못하기 때문이다. 즉, asynchrony만으로는 충분하지 않고, sparse update를 보완할 temporal memory가 필요하다.
RQ3. Force와 visual memory는 서로 보완적이다
DAM-VLA/F는 force를 제거하고 visual memory만 남긴 model이다. 이 모델은 Scarf와 Sweep에서 100.0%, Button에서 86.7%를 달성한다. Memory는 sequential context를 유지하고 repeated behavior를 줄이는 데 도움이 된다. 하지만 contact depth나 precise insertion이 필요한 Lego와 Socket에서는 각각 0.0%, 6.7%에 머문다. 즉, memory만으로는 contact state를 충분히 알 수 없다.
DAM-VLA/M은 memory를 제거하고 force만 남긴 model이다. Button 86.7%, Handwash 80.0%로 contact-related task에서 개선된다. 하지만 memory가 없기 때문에 이미 contact가 발생했는지, task가 어느 stage까지 진행되었는지 유지하기 어렵다. 논문은 이 모델이 Handwash에서 repeated pressing을 하는 failure를 보인다고 설명한다.
Full DAM-VLA는 두 failure mode를 동시에 줄인다.
- Visual memory는 task progress를 유지해 repeated pressing, stalling, sequence confusion을 줄인다.
- Force/torque는 contact onset, contact depth, contact termination에 필요한 high-frequency signal을 제공한다.
- GCA는 이 두 정보를 pretrained action expert에 직접 concat하지 않고 residual pathway로 주입한다.
그 결과 full DAM-VLA는 Lego 93.3%, Socket 80.0%, Handwash 100.0%를 달성한다. Synchronous baselines가 거의 실패한 contact-heavy task에서 성능 차이가 가장 크게 나타난다.
RQ4. 같은 정보를 넣어도 integration mechanism이 중요하다
X-VLA_AFM은 full DAM-VLA와 동일하게 asynchronous information, force, memory를 사용한다. 하지만 이 정보를 GCA로 넣지 않고 flat token sequence로 concatenate한다. 결과는 평균 54.3%다. Full DAM-VLA의 95.2%와 큰 차이가 난다.
이 비교가 이 논문의 가장 중요한 ablation 중 하나다. 단순히 force와 memory를 추가하는 것만으로는 충분하지 않다. 새로운 modality token을 pretrained self-attention stream에 직접 밀어 넣으면, 기존 vision-language-action representation이 오염될 수 있다. DAM-VLA는 GCA를 zero-initialized residual pathway로 넣기 때문에, training 초기에 pretrained action expert를 크게 망가뜨리지 않고 점진적으로 새 modality를 활용하게 만든다.
즉, 이 논문의 핵심은 “force를 추가했다”가 아니다.
핵심은 pretrained VLA backbone을 깨지 않으면서 high-frequency modality를 action token에 주입하는 방법이다.
Motion smoothness analysis
Appendix에서는 Sweep task에 대해 command smoothness와 tracking responsiveness를 추가 분석한다. Sweep은 긴 시간 동안 지속적인 arm motion이 필요하기 때문에, jerky command나 control lag가 잘 드러나는 task다.
논문은 두 가지 metric을 사용한다.
| Metric | 의미 | 낮을수록 |
|---|---|---|
| SPARC | 7-D joint command trajectory의 spectral arc length | command가 더 smooth |
| Tracking lag | commanded joint motion과 measured joint motion 사이의 temporal delay | robot이 command를 더 빠르게 따라감 |
SPARC 비교에서는 X-VLA25를 제외한다. 25 Hz command를 100 Hz로 zero-order hold upsampling하면 staircase artifact가 생겨 SPARC가 부당하게 커질 수 있기 때문이다.
| Model | SPARC ↓ | Tracking lag ↓ |
|---|---|---|
X-VLA25 | N/A | 0.189 s |
X-VLA100 | 25.04 | 0.135 s |
X-VLA_AFM | 10.47 | 0.124 s |
DAM-VLA/F/M | 16.83 | 0.139 s |
DAM-VLA/F | 10.98 | 0.128 s |
DAM-VLA/M | 10.60 | 0.127 s |
DAM-VLA | 8.10 | 0.118 s |
100 Hz methods 중 full DAM-VLA가 가장 낮은 SPARC를 기록한다. 이는 DAM-VLA가 가장 smooth한 command를 만든다는 뜻이다. Tracking lag도 DAM-VLA가 가장 낮다. 따라서 DAM-VLA의 장점은 success rate만이 아니라, command smoothness와 execution responsiveness에서도 나타난다.
Episode length analysis
Episode length는 policy가 얼마나 주저하거나 반복하거나 stall하는지를 보여주는 보조 지표다. 성공률만 보면 policy가 우연히 성공했는지, 안정적으로 빠르게 성공했는지 구분하기 어렵다.
Appendix의 episode length 분석에서 DAM-VLA는 여러 task에서 짧거나 안정적인 실행 시간을 보인다. 예를 들어 Whiteboard에서는 DAM-VLA가 약 24.4 s에 수행하는 반면, X-VLA100은 약 83 s까지 길어진다. Button에서도 DAM-VLA는 약 10.8 s에 clean execution을 보이고, X-VLA25와 X-VLA100은 더 오래 걸린다.
다만 이 결과를 “DAM-VLA가 항상 더 빠르다”로 해석하면 안 된다. 논문도 X-VLA25의 평균 episode length가 Socket과 Lego 같은 failed / partial cases 때문에 크게 skewed된다고 설명한다. 핵심은 raw speed가 아니라 reliable and consistent execution이다. DAM-VLA는 baseline이 실패하거나 stall하는 contact-heavy task에서도 끝까지 성공하는 비율이 높다.
Replanning frequency ablation
논문은 main result를 100 Hz controller에서 보고하지만, Appendix에서는 Handwash와 Whiteboard task에 대해 200 Hz controller ablation도 수행한다. 여기서 action chunk horizon s를 바꿔 replanning frequency와 motion quality의 trade-off를 본다.
| Controller | Horizon | Replanning frequency | Motion quality | Success |
|---|---|---|---|---|
| 200 Hz | s = 22 | 8 Hz | Smooth, fluid | 100% |
| 200 Hz | s = 6 | 17 Hz | Reactive, less fluid, slower execution | 100% |
s=22는 더 긴 chunk를 실행하므로 motion이 smooth하고 fluid하다. s=6은 더 자주 replan하므로 reactive하지만, chunk transition이 잦아져 motion이 덜 fluid하고 실행이 느려진다.
중요한 점은 17 Hz보다 더 높은 replanning frequency에서는 성능이 악화된다는 것이다. Visual tokens를 sparse하게 cache하더라도, 매우 높은 replanning frequency에서는 남아 있는 VLM encoding latency가 다시 bottleneck이 된다. 따라서 DAM-VLA는 VLA latency 문제를 완전히 제거한 것이 아니라, sensor update와 action generation을 decouple해서 실용적인 replanning frequency 범위를 넓힌 것으로 보는 것이 정확하다.
Experiment takeaway
실험 결과를 한 문장으로 정리하면 다음과 같다.
DAM-VLA의 성능 향상은 force/torque라는 sensor를 단순히 추가해서 나온 것이 아니라, modality별 update rate와 temporal horizon을 보존하고, 이를 pretrained action expert에 GCA residual pathway로 주입했기 때문에 나온다.
더 구체적으로는 세 가지 결론이 중요하다.
-
Naive high-frequency VLA는 오히려 성능을 망칠 수 있다.
X-VLA100은 visual frame upsampling 때문에 contradictory action supervision을 받고, hesitant / jerky motion을 만든다. -
Asynchronous latent buffer는 real-time VLA의 기본 설계 원칙이 될 수 있다. visual token은 sparse하게 refresh하고, force/proprioception은 high-frequency로 update하며, action expert는 항상 최신 buffer를 읽는다.
-
New modality integration은 concat보다 GCA가 훨씬 안정적이다. 같은 force + memory 정보를 넣어도 flat concatenation은 54.3%에 그치고, GCA 기반 DAM-VLA는 95.2%까지 올라간다.
Limitations
1. Force를 chunk 내부 action correction에 쓰지 않는다
DAM-VLA는 force를 representation 향상에는 사용하지만, action chunk 내부에서 force feedback으로 action을 직접 수정하지 않는다. 저자는 이 때문에 socket 같은 very contact-heavy task에서 alignment error를 mid-chunk에 고치지 못하고 80% 성능에 머문다고 설명한다.
2. Vision side가 완전히 event-driven은 아니다
camera update가 scene change detector로 trigger되는 것이 아니라 fixed timer에 의해 업데이트된다. 저자는 scene change 기반 VLM trigger를 future work로 제시한다.
3. Dedicated F/T sensor가 아니다
force signal은 external F/T sensor가 아니라 Franka built-in joint-torque estimate에서 온다. 저자는 external F/T sensor, torque-level control, 더 많은 modality를 추가하면 성능이 더 좋아질 수 있다고 주장한다.
4. Additional points
저자가 명시한 limitation 외에도 몇 가지는 조심해서 봐야 한다.
- Single robot / single workspace evaluation
- 실험은 Franka Panda와 fixed tabletop workspace 중심이다. X-VLA backbone은 cross-embodiment를 지향하지만, DAM-VLA 자체가 unseen embodiment에서 잘 일반화되는지는 이 논문만으로 확인하기 어렵다.
- Action representation이 contact control에 최적인 것은 아니다
- DAM-VLA는 7-D joint position + 1-D gripper state를 예측한다. Force/torque를 observation으로 쓰지만, action 자체는 torque, impedance, force target이 아니다. 따라서 tight insertion이나 high-force interaction에서는 low-level compliance가 부족할 수 있다.
- Evaluation trial 수가 크지는 않다
- task당 15 trials는 real robot paper에서는 의미 있는 수치지만, confidence interval이나 significance test가 제시되지는 않는다. 특히 Socket처럼 80% 성공률인 task는 더 많은 trial에서 variance를 확인할 필요가 있다.
- Exact training objective와 code 공개 여부가 제한적이다
- 논문은 policy가 8-D action을 예측한다고 설명하지만, action loss의 정확한 수식은 명시하지 않는다. 또한 작성일 기준으로 code, dataset, checkpoint 공개 여부가 명확하지 않다.
- World model이나 planner는 아니다
- DAM-VLA는 미래 상태를 예측하거나 candidate action을 rollout해서 평가하지 않는다. Force/proprioception history를 통해 implicit contact state를 표현하지만, explicit dynamics model이나 world model은 아니다.