



ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
대규모 egocentric human video를 robot-compatible pseudo-action으로 변환하고, camera-space action / morphology conditioning / time-aligned chunking / reliability-aware auxiliary loss를 결합해 human + robot + simulation 데이터를 함께 VLA pretraining에 쓰는 unified VLA pretraining framework
Overview Figure
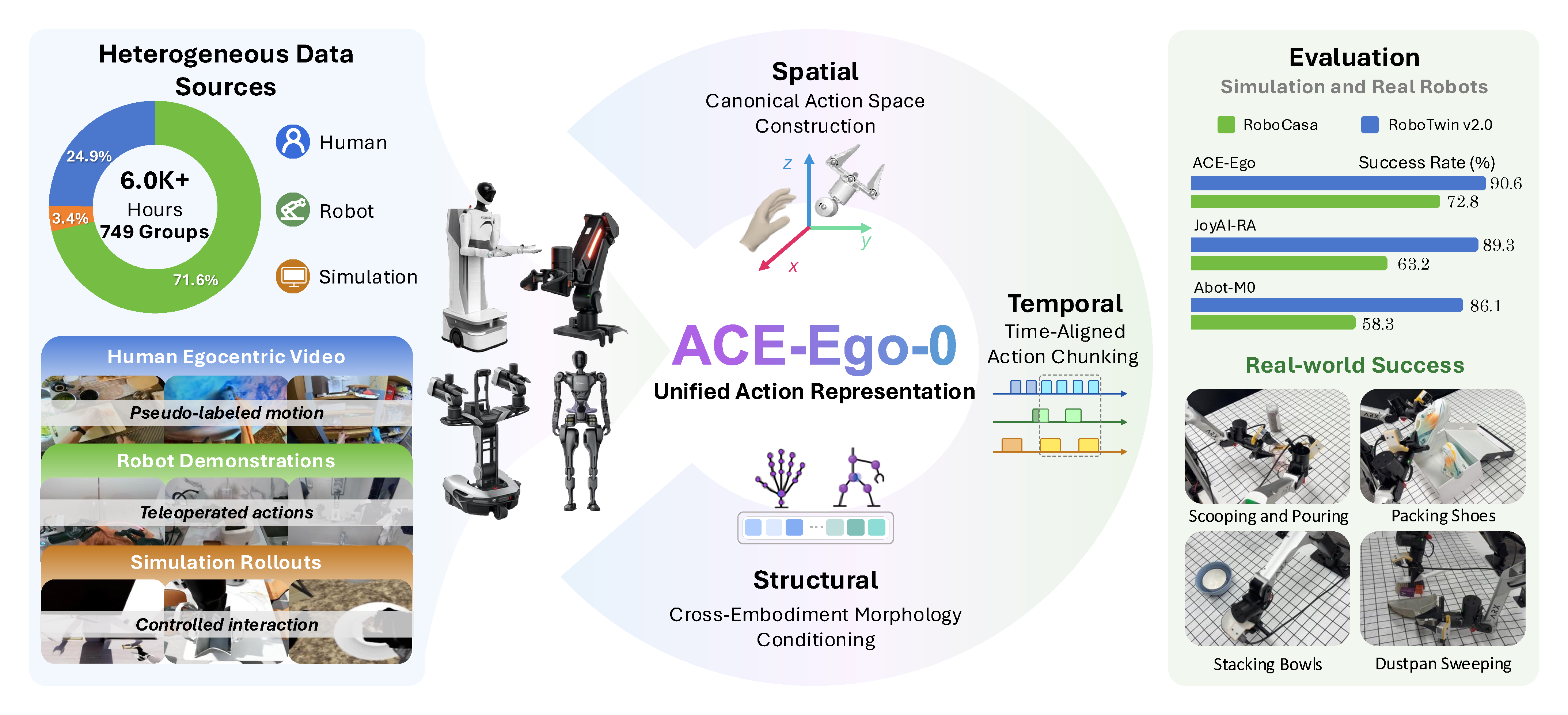
Summary
- 기존 VLA 모델은 대규모 robot demonstration에 의존하지만, robot trajectory 수집은 비싸고 느리며, human egocentric video는 풍부하지만 robot action과 coordinate frame, embodiment, temporal frequency, label quality가 맞지 않는 문제가 있다.
- 이 논문은 human egocentric video와 multi-embodiment robot/simulation data를 하나의 VLA policy pretraining corpus로 통합하는 문제를 해결하려 한다.
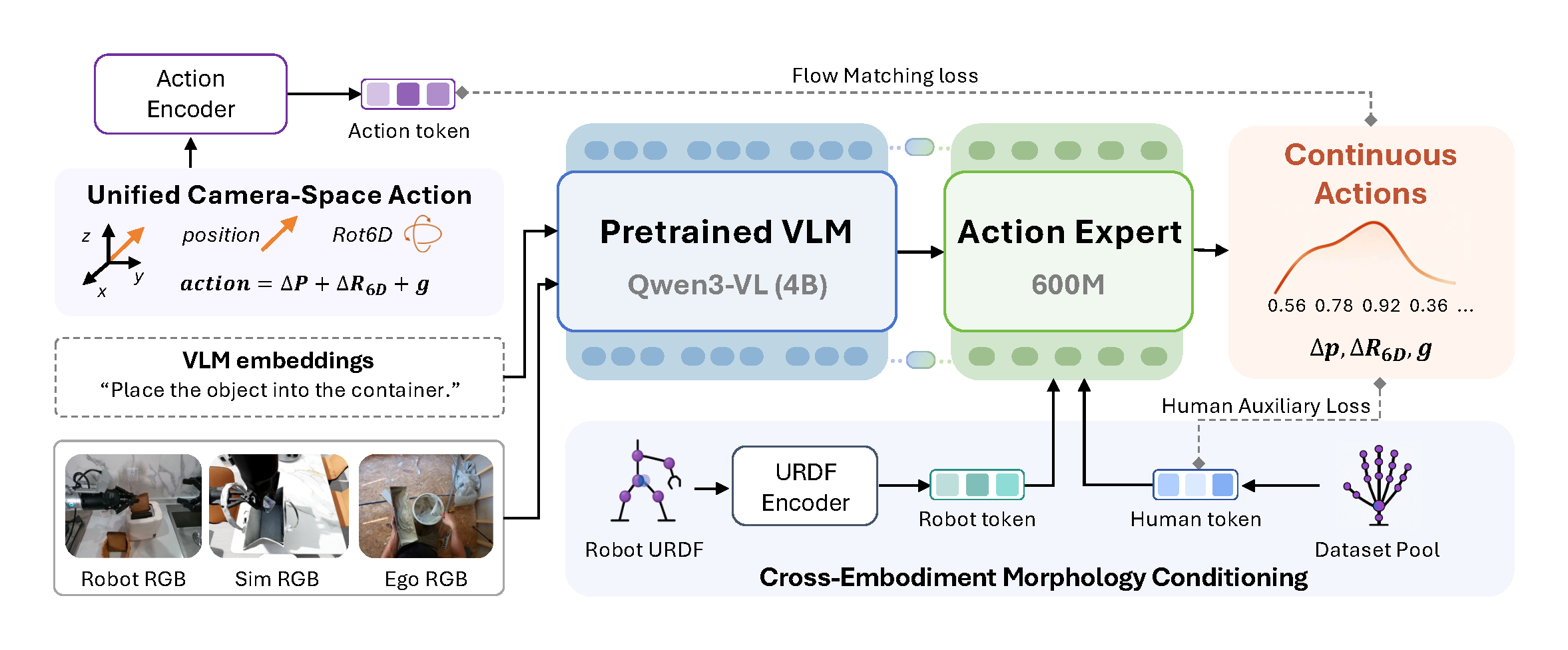
- 핵심 아이디어는 human hand motion과 robot end-effector action을 모두 head-camera coordinate frame의 camera-space action으로 맞추고, robot URDF 또는 human surrogate embedding으로 morphology를 conditioning하며, dataset별 control frequency 차이를 physical time 기준 action chunk로 align하는 것이다.
- 모델은 Qwen3-VL-4B-Instruct를 vision-language backbone으로 사용하고, 약 600M parameter의 flow-matching DiT action expert가 morphology token과 VLM embedding을 받아 continuous action chunk를 생성한다.
- 실험에서는 4.53K hours robot/simulation data와 1.48K hours pseudo-action-labeled human data를 사용해 RoboCasa 72.8%, RoboTwin 2.0 Easy/Hard 91.12%/90.62%, real ARX bimanual tasks 평균 78.3%를 달성하며, human video 추가가 pretraining과 data-scarce fine-tuning 모두에서 성능을 끌어올린다고 주장한다.
Key Components
-
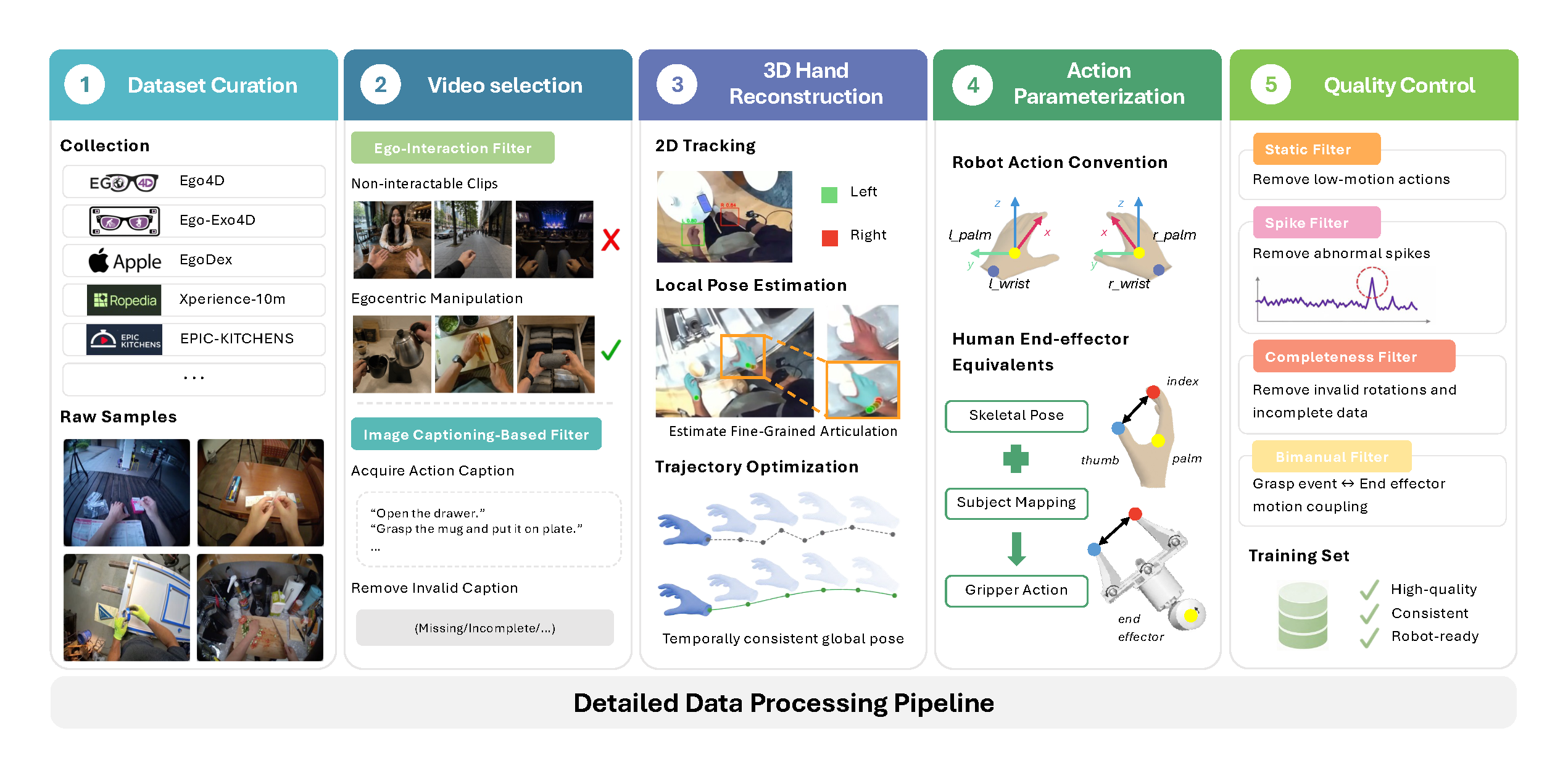
Unified VLA policy pretraining corpus 이 논문의 핵심은 human video, robot demonstrations, simulation rollouts를 단순히 하나의 dataloader에 섞은 것이 아니라, 하나의 VLA policy가 학습할 수 있는 공통 observation-action interface로 정렬했다는 점이다. Pretraining pool은 약 4.53K hours robot/simulation data + 1.48K hours pseudo-action-labeled egocentric human data로 구성되며, robot/simulation data는 sensor-logged action을 제공하고, human video는 vision pipeline으로 복원한 pseudo-action을 제공한다.
-
Head-camera coordinate frame의 camera-space action 서로 다른 robot dataset은 base frame, world frame, robot-specific frame 등 action coordinate convention이 다를 수 있다. ACE-EGO-0는 robot end-effector trajectory와 human hand pseudo-trajectory를 모두 head-camera coordinate frame으로 변환해, observation과 action이 같은 camera-centric coordinate system 안에 놓이도록 만든다. 즉 policy는 “이미지에서 보이는 장면 기준으로 어떻게 움직일지”를 배우고, deployment 시에는 예측된 camera-frame end-effector action을 camera extrinsic의 inverse transform으로 robot execution frame에 되돌려 실행한다.
-
Robot action과 human pseudo-action의 공통 action layout Robot data에서는 left/right end-effector pose, gripper, activity flag를 camera-space action으로 변환한다. Human video에서는 실제 robot end-effector가 없기 때문에, wrist joint를 proxy end-effector origin으로 쓰고, palm-plane orientation과 thumb-to-palm distance를 이용해 robot-compatible pseudo-action을 만든다. 최종 training action은 bimanual 기준 22D action vector로 정리되며, 각 arm은
3D position + 6D rotation + gripper + activity flag로 구성된다. - Spatial / structural / temporal alignment “하나의 corpus”가 되기 위해서는 action 좌표계만 맞추는 것으로 충분하지 않다. ACE-EGO-0는 세 축을 함께 맞춘다.
- Spatial alignment: 모든 action을 head-camera frame의 camera-space action으로 변환
- Structural alignment: robot은 URDF graph embedding, human source는 learned surrogate embedding으로 morphology token을 만들어 action expert에 condition
- Temporal alignment: dataset마다 control frequency가 다르므로 fixed step 수가 아니라 physical time 기준으로 action chunk horizon을 설정 즉, 같은 policy가 human / robot / sim trajectory를 볼 때 “어느 좌표계인가, 어떤 embodiment인가, 몇 초 뒤까지 예측하는가”가 최대한 일관되도록 만든다.
-
Morphology conditioning Camera-space action으로 좌표계를 맞춰도 robot마다 arm length, joint limit, kinematic chain이 다르다. 그래서 ACE-EGO-0는 robot source에는 URDF graph encoder로 만든 morphology token을 붙이고, human video source에는 learned human surrogate token을 붙인다. 중요한 점은 이 morphology token이 VLM backbone 전체를 바꾸는 것이 아니라, action expert의 decoding 단계에만 주입된다는 것이다. 덕분에 VLM은 embodiment-agnostic semantic representation을 유지하고, action expert가 embodiment-specific action generation을 담당한다.
-
Time-aligned action chunking 서로 다른 dataset이 10 Hz, 20 Hz, 30 Hz처럼 다른 control frequency로 수집되면, 같은 20-step action chunk라도 실제 물리 시간은 달라진다. ACE-EGO-0는 dataset별 frequency $f_d$와 target physical duration $T^{\star}$를 이용해 $H_{d} = \text{round}(f_{d} T^{\star})$로 action horizon을 정한다. 따라서 모든 dataset이 대략 같은 future physical window를 supervise하게 되고, mixed-source pretraining에서 temporal mismatch를 줄인다.
-
Reliability-aware human auxiliary loss Human pseudo-action은 robot sensor-logged action만큼 정확하지 않다. 특히 hand reconstruction 기반 rotation과 gripper proxy는 occlusion, tracking jitter, depth ambiguity에 취약하다. 그래서 robot/simulation sample은 primary flow-matching action loss로 학습하고, human sample은 reliability-aware auxiliary loss로만 넣는다. 이때 human supervision은 주로 wrist position channel에 집중되고, noisy한 rotation / gripper channel은 매우 약하게 반영된다. 핵심은 human video를 clean robot demonstration처럼 믿는 것이 아니라, broad but noisy auxiliary supervision으로 활용한다는 점이다.
- Flow-matching VLA action expert 모델은 Qwen3-VL-4B-Instruct를 vision-language backbone으로 사용하고, 약 600M parameter의 flow-matching DiT action expert가 VLM embedding과 morphology token을 받아 continuous camera-space action chunk를 생성한다. 따라서 이 논문은 explicit world model이나 planner를 붙인 WAM 계열이라기보다는, large-scale mixed embodied data로 학습한 flow-based VLA policy pretraining framework에 가깝다.