



PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation
pretrained 14B flow-matching video DiT에 Geometry-Aware Cross-View Attention, camera-aware Geo-RoPE, Depth Anything 3 기반 Latent 3D-REPA를 결합해 여러 로봇 카메라의 미래 영상을 3D-consistent하게 생성하고, action-conditioned rollout을 WAM의 world-prediction backbone으로 활용할 수 있는 multi-view world foundation model
Overview Figure
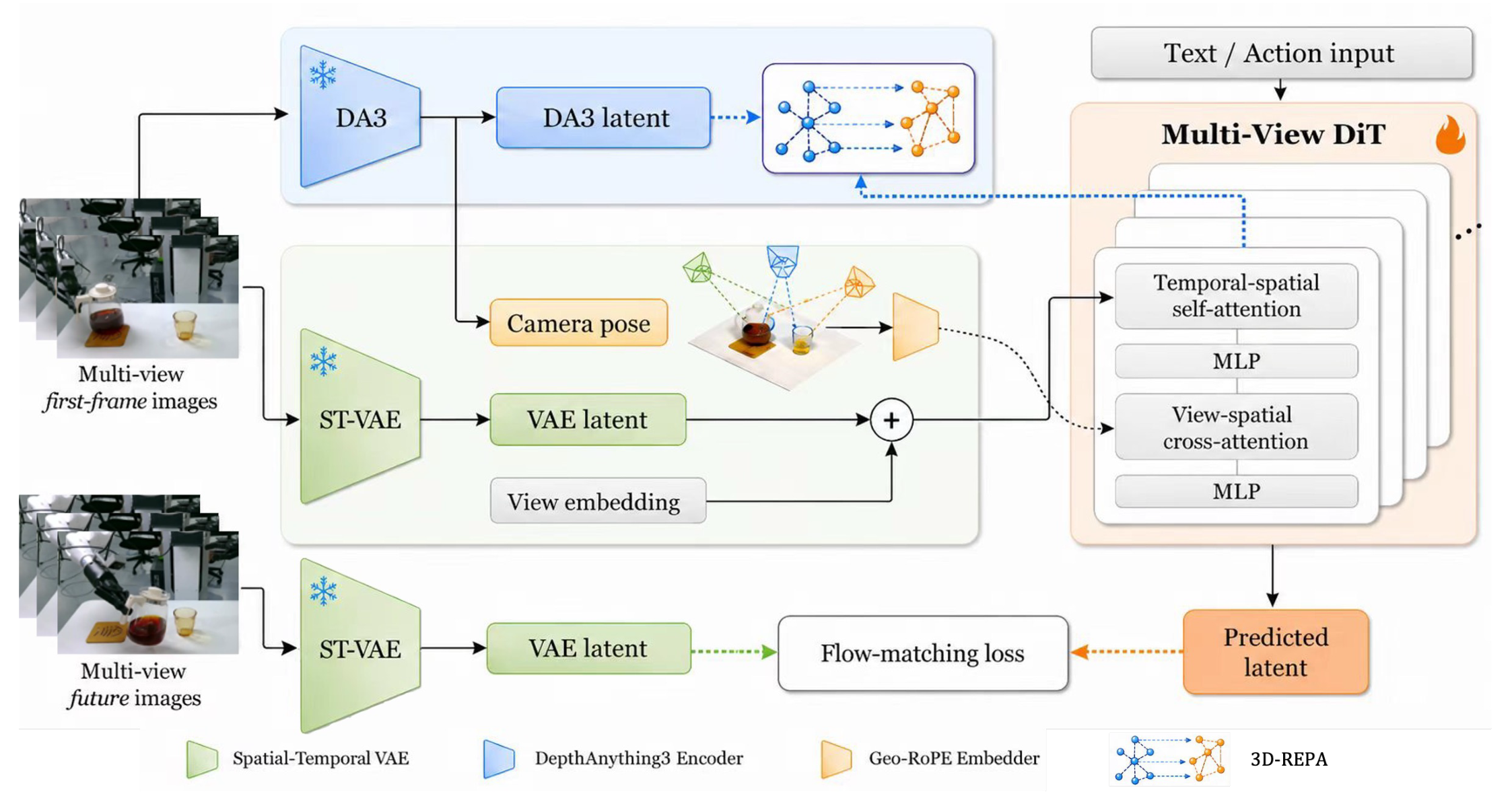
Summary
- 기존 multi-view world model은 여러 카메라의 token을 평평하게 연결하는 flat concatenation에 의존하기 때문에 object drift, depth contradiction, texture misalignment를 일으킨다.
- 이 논문은 wide-baseline robot cameras에서 미래 영상을 생성할 때 모든 view가 하나의 공통 3D scene으로 설명될 수 있도록 만드는 문제를 다룬다.
- 핵심 아이디어는 view 간 정보를 전달하는 architectural pathway와 그 정보가 실제 geometry를 반영하도록 만드는 geometric training signal이 동시에 필요하다는 것이다.
- Cosmos-Predict2.5 기반 flow-matching DiT에 cross-view attention과 camera ray/pose 기반 Geo-RoPE(Geometric Rotary Position Embedding)를 삽입하고, frozen Depth Anything 3의 token relation을 Latent 3D-REPA로 distill한다.
- PAIWorld 자체는 action을 출력하는 WAM은 아니지만, 주어진 action sequence에 따른 3D-consistent multi-view future rollout을 생성하므로, action-generation policy/head와 결합하면 WAM의 world-prediction branch 또는 visual dynamics backbone으로 활용할 수 있다. 다만 논문은 실제 WAM 결합이나 WAM 기반 policy 향상을 실험으로 검증하지는 않았다.
- WorldArena에서는 EWMScore 70.67로 1위, AgiBot-Challenge2026에서는 0.8245로 2위, AgiBot-World text-conditioned generation에서는 MEt3R 14.20 등 7개 metric 중 6개에서 최고 성능을 보였지만, 실제 robot planning이나 policy success-rate 개선은 실험하지 않았다.