



LAGO Policy: Latency-Aware Asynchronous Diffusion Policies with Goal-Directed Collision-Free Planning for Smooth Manipulation
asynchronous inference로 실행되는 Diffusion Policy의 chunk boundary jerk와 obstacle collision 문제를 latency-aware classifier-free guidance, demonstration-derived goal prediction, collision-free trajectory optimization, spatial-temporal smoothing으로 줄이는 real-robot manipulation policy
Overview Figure
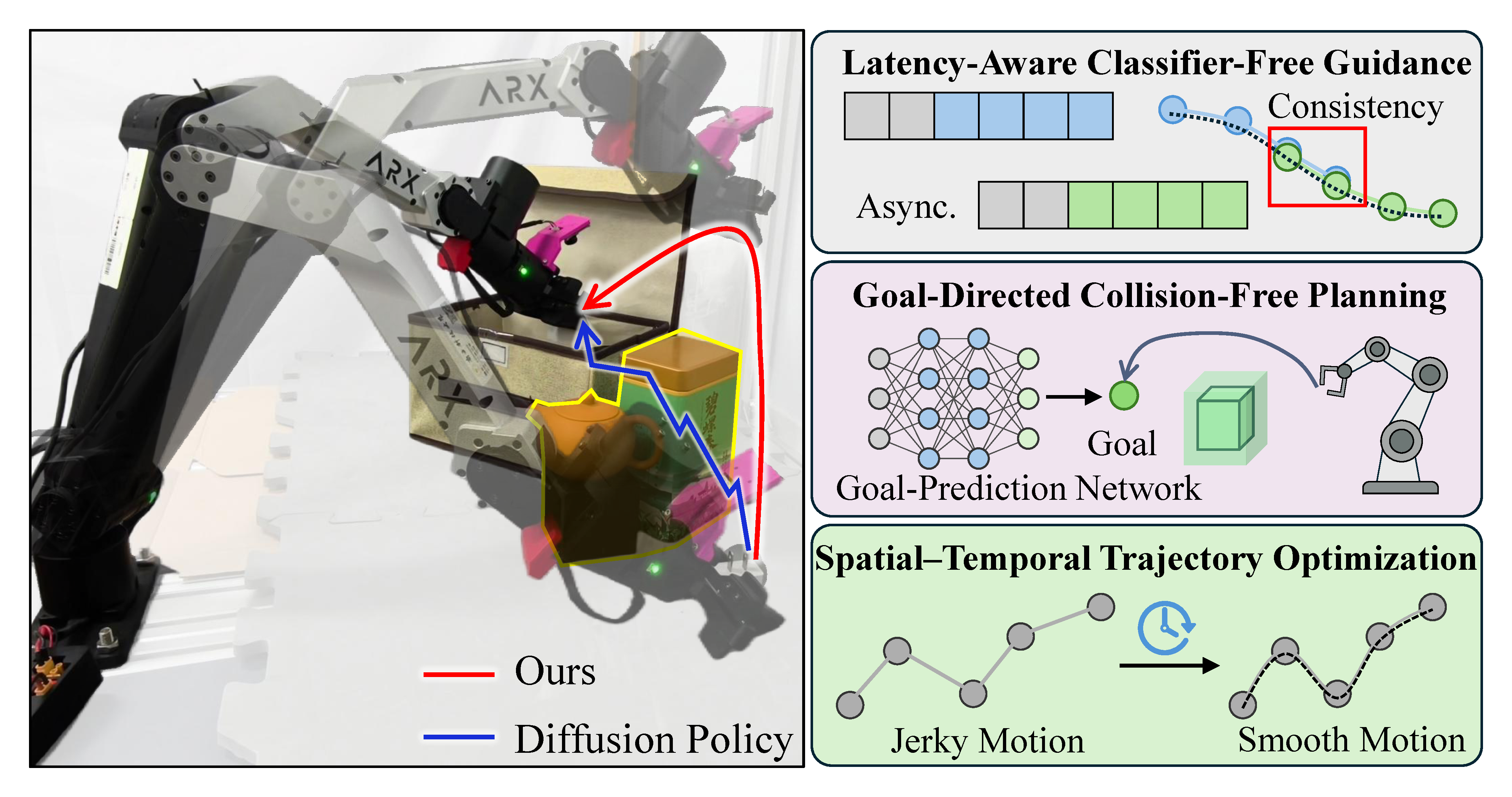
Summary
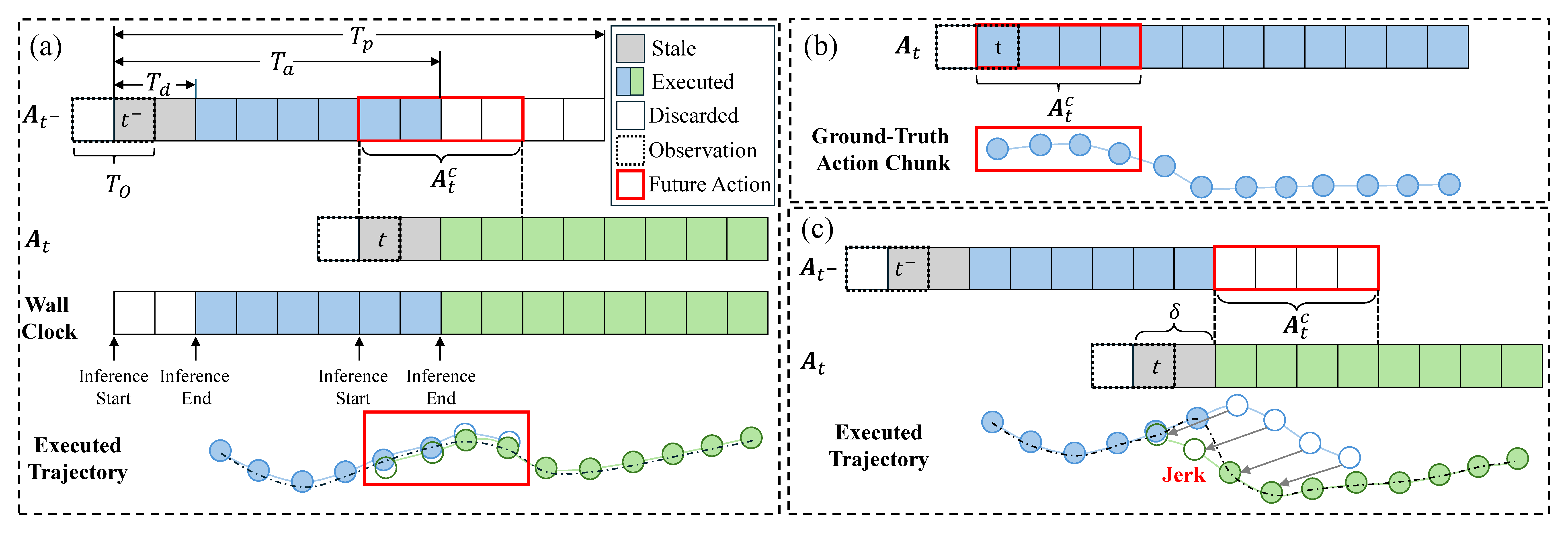
- 기존 diffusion-based visuomotor policy는 multi-step denoising 때문에 inference latency가 있고, 이를 피하려고 asynchronous inference를 쓰면 이전 observation으로 생성한 action chunk가 실제 실행 시점의 상태와 어긋나 inter-chunk discontinuity와 jerk를 만든다.
- 또한 대부분의 generative control policy는 demonstration imitation에 집중할 뿐 collision-free feasible set을 명시적으로 모델링하지 않아, unseen obstacle이 있을 때 geometrically infeasible trajectory를 만들 수 있다.
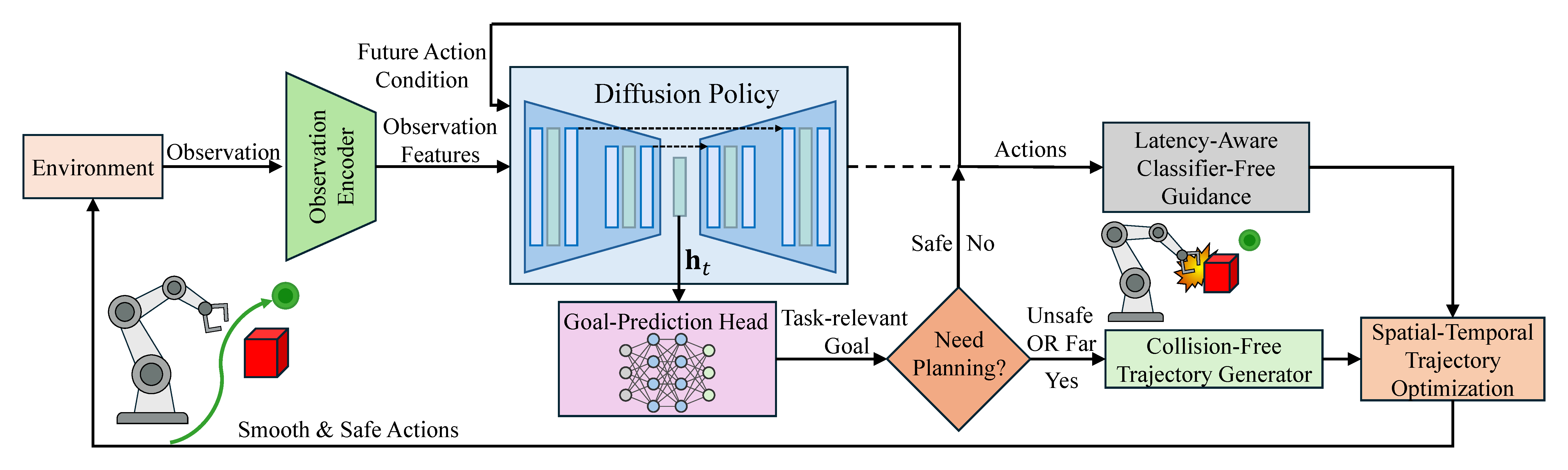
- 이 논문은 이를 해결하기 위해 future-action condition을 observation feature와 분리한 latency-aware CFG, expert demonstration에서 학습한 task-relevant goal prediction, goal-directed collision-free trajectory generation, spatial-temporal trajectory optimization을 하나의 asynchronous execution framework로 결합한다.
- 학습 단계에서는 future-action condition에 random delay offset을 주어 inference latency로 인한 temporal shift에 robust하게 만들고, goal-prediction head를 Diffusion Policy U-Net bottleneck에 붙여 task-relevant interaction goal을 regression하도록 학습한다.
- Real-world 8개 manipulation task에서 baseline Diffusion Policy(DP) 대비 평균적으로 success rate, inter-chunk consistency, jerk가 개선되며, unseen-obstacle setting의 4개 task에서는 goal-directed planning이 local safety filter보다 높은 success rate를 달성한다.
Key Components
-
Latency-Aware Classifier-Free Guidance (LA-CFG) 이전 action chunk에서 아직 실행되지 않은 future-action segment를 condition으로 사용해, 다음 action chunk의 시작 부분이 이전 chunk와 부드럽게 이어지도록 만든다. 기존 SAIL류처럼 future action을 observation feature에 직접 concatenate하지 않고, observation condition과 future-action condition을 분리한 뒤 CFG 방식으로 주입한다.
-
Delay-Randomized Future-Action Conditioning 학습 중 future-action condition을 항상 정렬된 위치에서만 쓰지 않고, random delay offset $\delta$만큼 shift해서 사용한다. 이를 통해 asynchronous inference에서 실제 실행 시점이 밀려 future-action condition이 temporal misalignment되어도 policy가 chunk boundary에서 급격히 깨지지 않도록 만든다.
-
Goal-Prediction Head Diffusion Policy U-Net의 bottleneck representation $\mathbf{h}_{t}$ 위에 MLP goal head를 붙여, expert demonstration에서 얻은 task-relevant interaction goal을 regression하도록 학습한다. 이 goal은 단순히 다음 action을 맞추기 위한 보조 출력이 아니라, obstacle이 있을 때 collision-free planner가 향해야 할 task-level target으로 사용된다.
-
Goal-Directed Collision-Free Trajectory Generation 현재 end-effector 위치에서 predicted goal까지의 직선 경로가 obstacle과 충돌하거나 goal이 멀리 있으면, policy action을 그대로 실행하지 않고 goal-conditioned trajectory generator를 활성화한다. 이 모듈은 A* guiding path와 B-spline trajectory optimization을 이용해 unseen obstacle을 피하면서 predicted goal로 향하는 smooth path를 만든다.
-
Spatial-Temporal Trajectory Optimization Diffusion Policy가 생성한 action chunk나 planner가 만든 trajectory를 그대로 실행하지 않고, continuous-time trajectory로 다시 최적화한다. action / velocity / acceleration limit을 고려하면서 jerk를 줄이기 때문에, real robot execution에서 stop-and-go motion이나 chunk boundary discontinuity를 완화한다.
-
Asynchronous Execution Framework 로봇이 현재 action chunk를 실행하는 동안 다음 chunk를 병렬로 생성한다. LAGO는 이 asynchronous setup에서 생기는 perception-execution misalignment를 LA-CFG와 delay randomization으로 줄이고, obstacle이 있을 때는 goal-directed planning으로 policy output을 보정한다.