



Where Should Action Generation Begin? A Learnable Source Prior for Generative Robot Policies
flow matching 기반 generative robot policy의 action generation source를 observation-independent Gaussian noise에서 proprioception-conditioned learnable Gaussian prior로 바꾸고, 같은 source prior가 diffusion-bridge generator에도 plug-in될 수 있음을 보인 source-prior learning method
Overview Figure
Summary
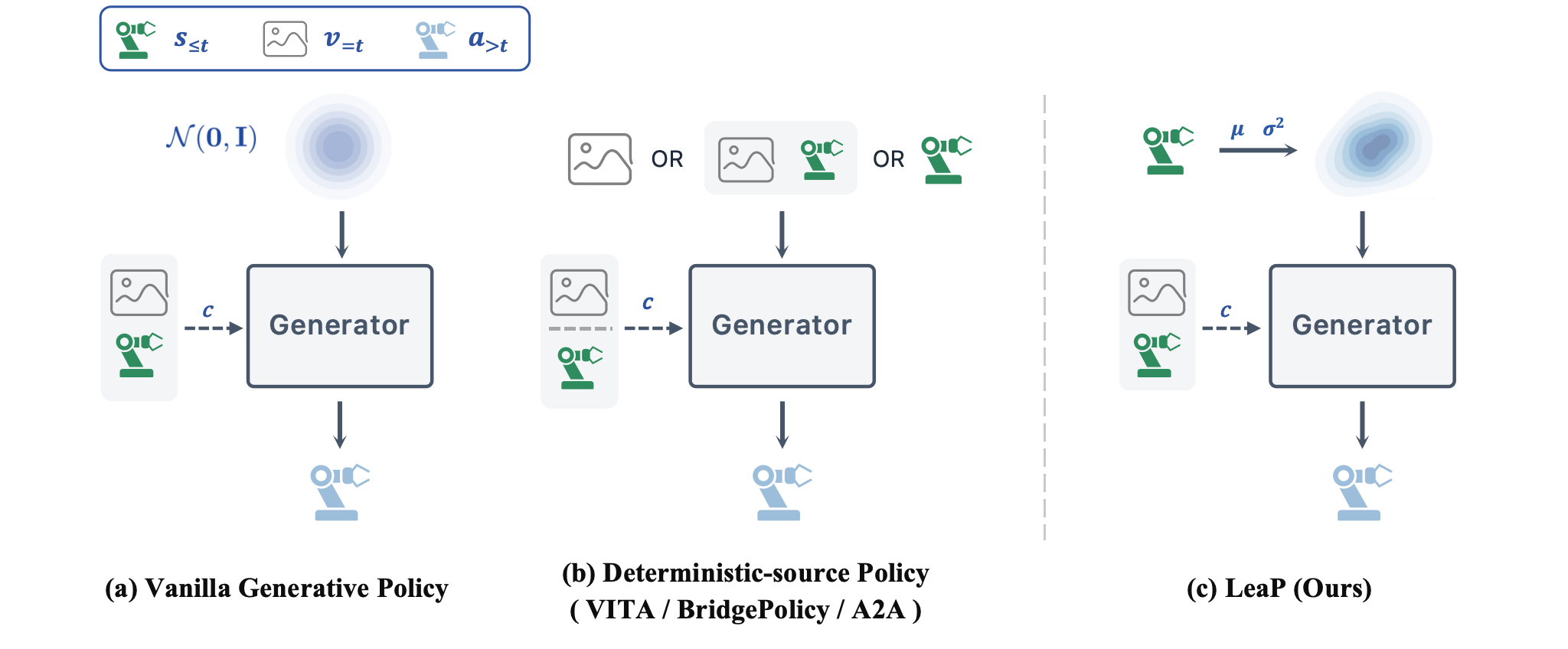
- 기존 diffusion / flow-matching robot policy는 action chunk 생성을 대개 현재 관측과 무관한 standard Gaussian $\mathcal{N}(\mathbf{0},\mathbf{I})$에서 시작하기 때문에, generator가 제한된 integration budget 일부를 “무의미한 noise source를 task-relevant action region으로 운반하는 데” 사용해야 한다.
- 이 논문은 “action generation은 어디서 시작해야 하는가?”라는 질문을 source distribution design 문제로 formulate한다.
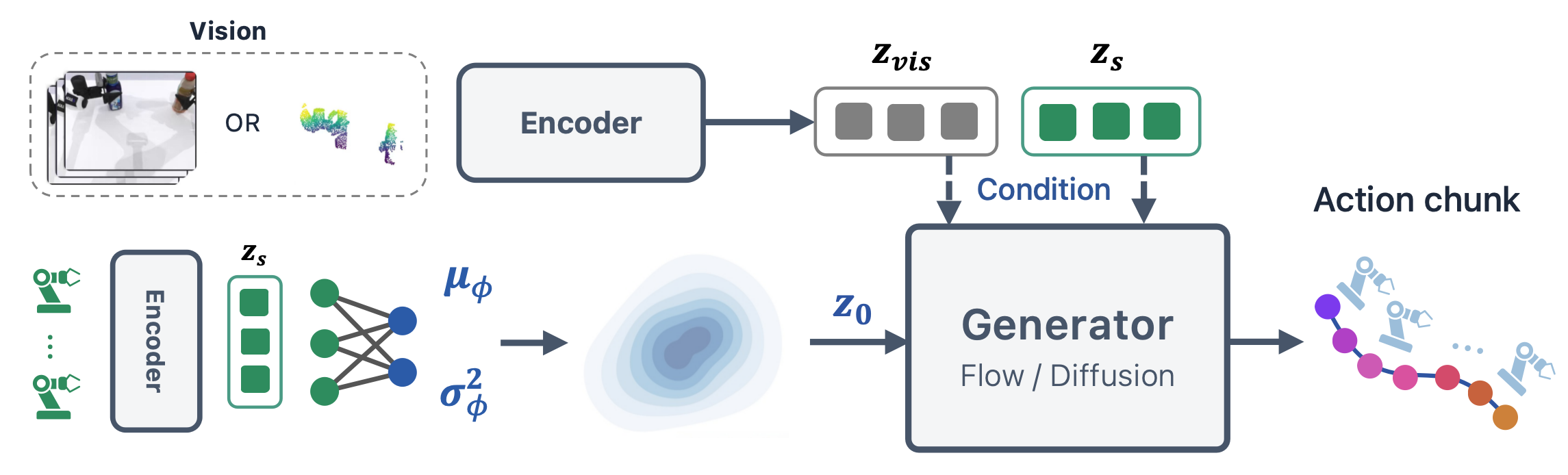
- 핵심 아이디어는 기존 $\mathcal{N}(\mathbf{0},\mathbf{I})$ source를 proprioceptive state feature $\mathbf{z}_{s}$ 로 condition된 learnable diagonal Gaussian prior $q_{\phi}(\mathbf{z}_{0}\|\mathbf{z}_{s})$로 바꾸는 것이다.
- LeaP는 lightweight MLP가 action-space source의 mean $\boldsymbol{\mu}_\phi$와 state-adaptive variance ${\boldsymbol{\sigma}_{\phi}}^2$를 예측하고, downstream generator architecture와 inference solver는 그대로 둔 채 flow matching loss, NLL loss, CLIP-style contrastive alignment loss로 end-to-end 학습된다.
- RoboTwin 15개 manipulation task에서 평균 성공률 81.6%를 달성해 A2A, VITA, NoPrior, BridgePolicy 대비 6.5–25.5 percentage point 향상했고, real Franka Research 3 실험에서도 가장 높은 평균 성공률을 보였다.