



Ambient Diffusion Policy: Imitation Learning from Suboptimal Data in Robotics
suboptimal / OOD robot demonstrations를 Diffusion Policy 학습에 그냥 섞지 않고, diffusion timestep에 따라 “쓸 수 있는 구간”을 제한해 유용한 global plan 또는 local motion primitive만 뽑아 쓰는 imitation learning 방법
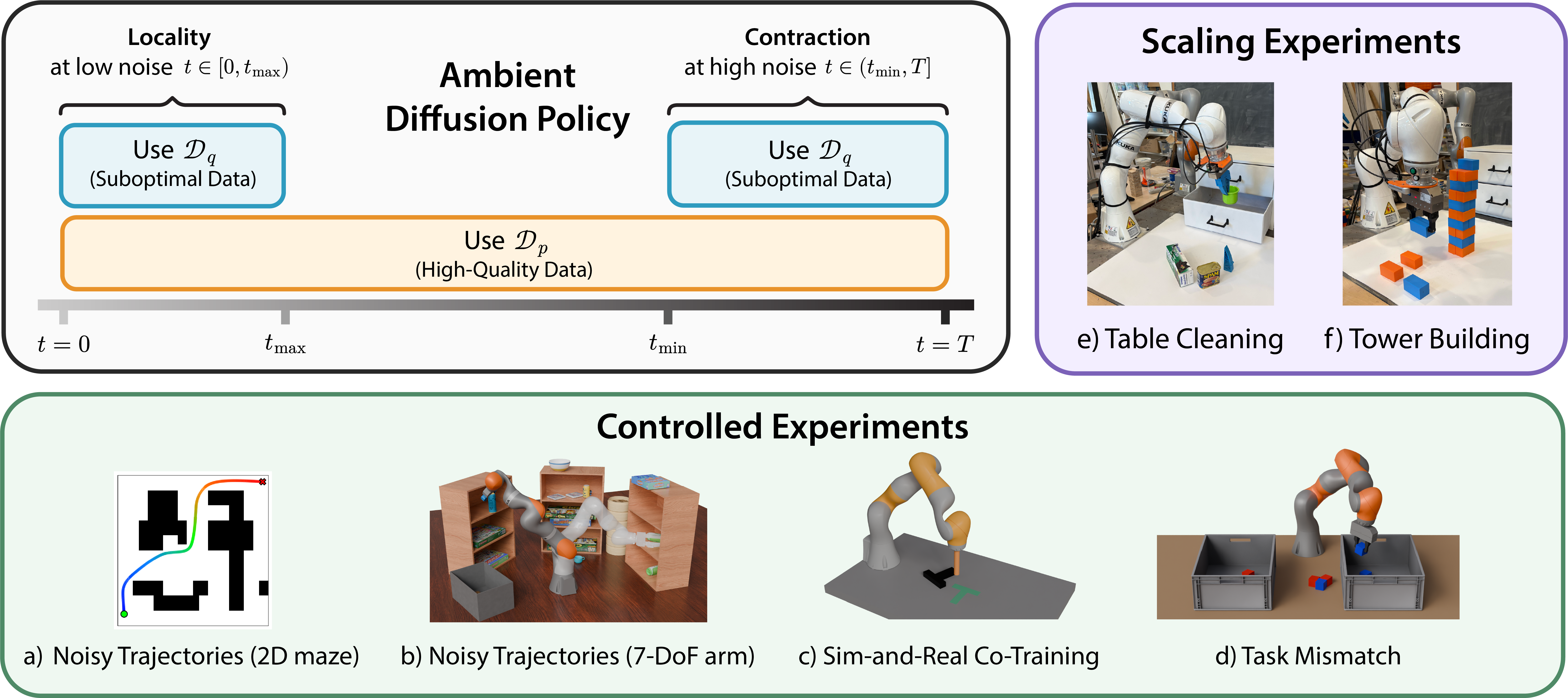
Overview Figure
Summary
- 기존 robot imitation learning에서는 high-quality target data가 부족하므로 suboptimal data, simulation data, task-mismatched data, large-scale heterogeneous robot dataset을 함께 co-training하는데, 단순 mixture training은 좋은 signal과 나쁜 bias를 분리하지 못한다.
- 이 논문은 작은 high-quality dataset $\mathcal{D}_{p}$와 큰 suboptimal dataset $\mathcal{D}_{q}$가 있을 때, $\mathcal{D}_{q}$를 버리지 않으면서도 target distribution $p(A∣O)$의 Diffusion Policy denoiser를 더 잘 추정하는 문제를 다룬다.
- 핵심 아이디어는 여러 robot action datasets에서 관찰되는 spectral power law 때문에 diffusion process 안에서 high noise는 low-frequency / global planning을, low noise는 high-frequency / local refinement를 담당한다는 점이다.
- 그래서 suboptimal data는 모든 diffusion time에 쓰지 않고, $t \in [0, t_{\text{max}}) \cup (t_{\text{min}}, T]$에서만 쓰며, $\mathcal{D}_{p}$는 모든 timestep에서 사용한다.
- noisy trajectory, sim-to-real gap, task mismatch, OXE-scale data mixture에서 주로 co-training / filtering baseline보다 좋은 성능을 보였고, finetuning 비교에서도 Ambient base policy가 더 유리한 경향을 보였다.