



Improving Robotic Generalist Policies via Flow Reversal Steering
coarse semantic action을 frozen flow-matching VLA의 역방향 ODE로 latent noise에 매핑한 뒤 다시 denoise해, generalist policy prior 안의 더 정교한 action mode를 호출하는 training-free steering 방법
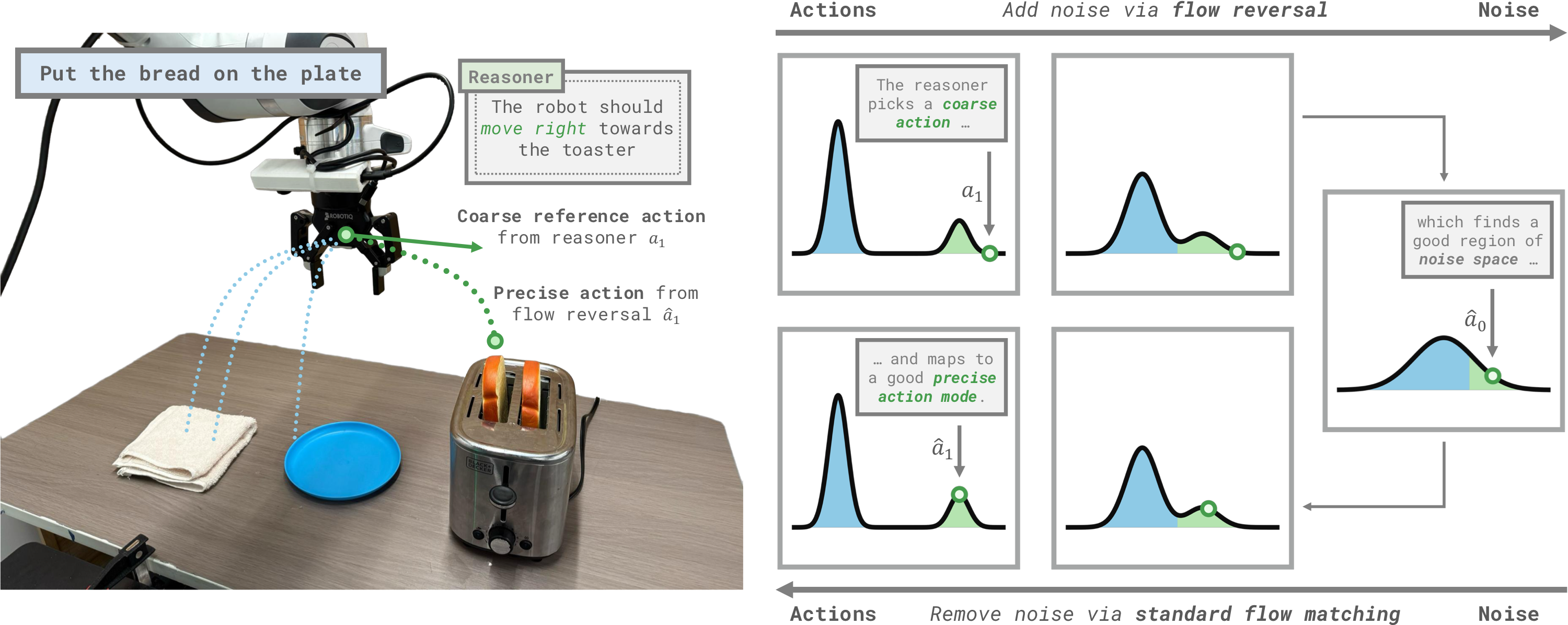
Overview Figure

Summary
- 기존 generalist robot policy / VLA는 다양한 skill을 학습하지만, novel task에서 base instruction following만으로는 적절한 행동 mode를 잘 꺼내지 못하고, RL로 latent noise를 찾는 방식은 trial-and-error 비용이 크다.
- 이 논문은 이미 pretrained flow-matching generalist policy 안에 들어 있는 “reasonable behavior prior”를 새 task에 맞게 빠르게 호출하는 문제를 다룬다.
- 핵심 아이디어는 VLM이나 human이 제공한 coarse but reasonable reference action을 flow ODE의 역방향으로 통과시켜 noise $\hat{a}_0$를 찾고, 이를 다시 표준 denoising으로 action $\hat{a}_1$으로 복원하면 reference와 semantic하게 유사하면서도 VLA distribution 안쪽의 더 정교한 action이 나온다는 것이다.
- 이 메커니즘은 training-free zero-shot steering, FRS noise를 supervised BC로 distill하는 DSBC(Diffusion Steering via Behavioral Cloning), FRS trajectory로 noise-space RL을 bootstrap하는 DSRL + FRS로 확장된다.
- LIBERO simulation과 DROID real-world manipulation에서 FRS는 base VLA, direct VLM action execution, partial noising, sample-and-rank보다 어려운 task에서 더 많은 성공 신호를 만들고, DSBC는 10개 내외의 FRS rollout으로 real-world task 평균 성공률을 크게 높이며, DSRL + FRS는 standard DSRL / residual RL보다 sample-efficient하게 개선된다.
Method Variants
-
FRS (Flow Reversal Steering; training-free zero-shot steering)
base flow-matching VLA는 완전히 고정한 채, human 또는 VLM reasoner가 낸 coarse reference action $a_1^{\text{ref}}$를 flow ODE의 역방향으로 적분해 latent noise $\hat{a}_0$로 바꾼다. 이후 같은 frozen VLA로 다시 denoise해 $\hat{a}_{1} = \mu_\theta(\hat{a}_{0}, o)$를 실행한다. 즉 FRS 자체는 parameter training 없이 동작하는 inference-time policy steering이며, VLM/human의 coarse semantic guidance를 VLA prior 안의 더 정교한 action mode로 projection하는 역할을 한다. -
DSBC (Diffusion Steering via Behavioral Cloning)
zero-shot FRS rollout에서 얻은 성공 trajectory의 $(o, \hat{a}_{0})$ pair를 expert noise-action data로 보고, 작은 auxiliary noise policy $\pi_\phi^{noise}(\hat{a}_{0} \mid o)$를 supervised BC로 학습한다. inference에서는 이 noise policy가 observation만 보고 $\hat{a}_0$를 예측하고, frozen VLA가 이를 robot action으로 decode한다. 따라서 DSBC는 full VLA fine-tuning이 아니라, FRS로 찾은 good noise를 distill하는 auxiliary-model training에 가깝다. -
DSRL + FRS
DSRL은 원래 latent noise $a_0$를 RL action으로 보고, frozen VLA를 action decoder처럼 사용해 noise-space RL을 수행한다. 하지만 standard DSRL은 좋은 noise를 random exploration으로 찾아야 해서 sparse-reward task에서 sample inefficiency가 크다. DSRL + FRS는 FRS trajectory를 replay buffer에 prefill하고, successful FRS noise에 대한 BC auxiliary loss를 추가해 RL을 bootstrap한다. 즉 FRS는 여기서 first-success generator / semantic prior data engine 역할을 한다.