Cosmos 3: Omnimodal World Models for Physical AI
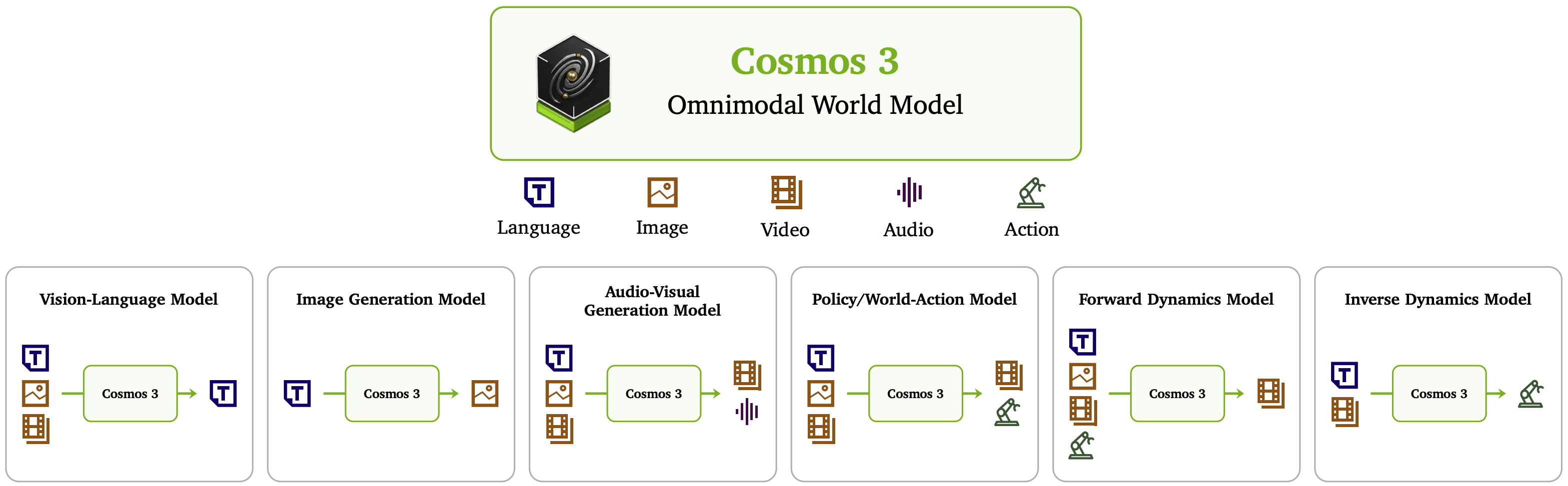
language, image, video, audio, action을 하나의 Mixture-of-Transformers (MoT) 기반 omnimodal world model로 통합해, VLM·video generator·forward/inverse dynamics·robot policy를 하나의 Physical AI backbone으로 다루는 NVIDIA의 대규모 foundation model
Overview Figure
Summary
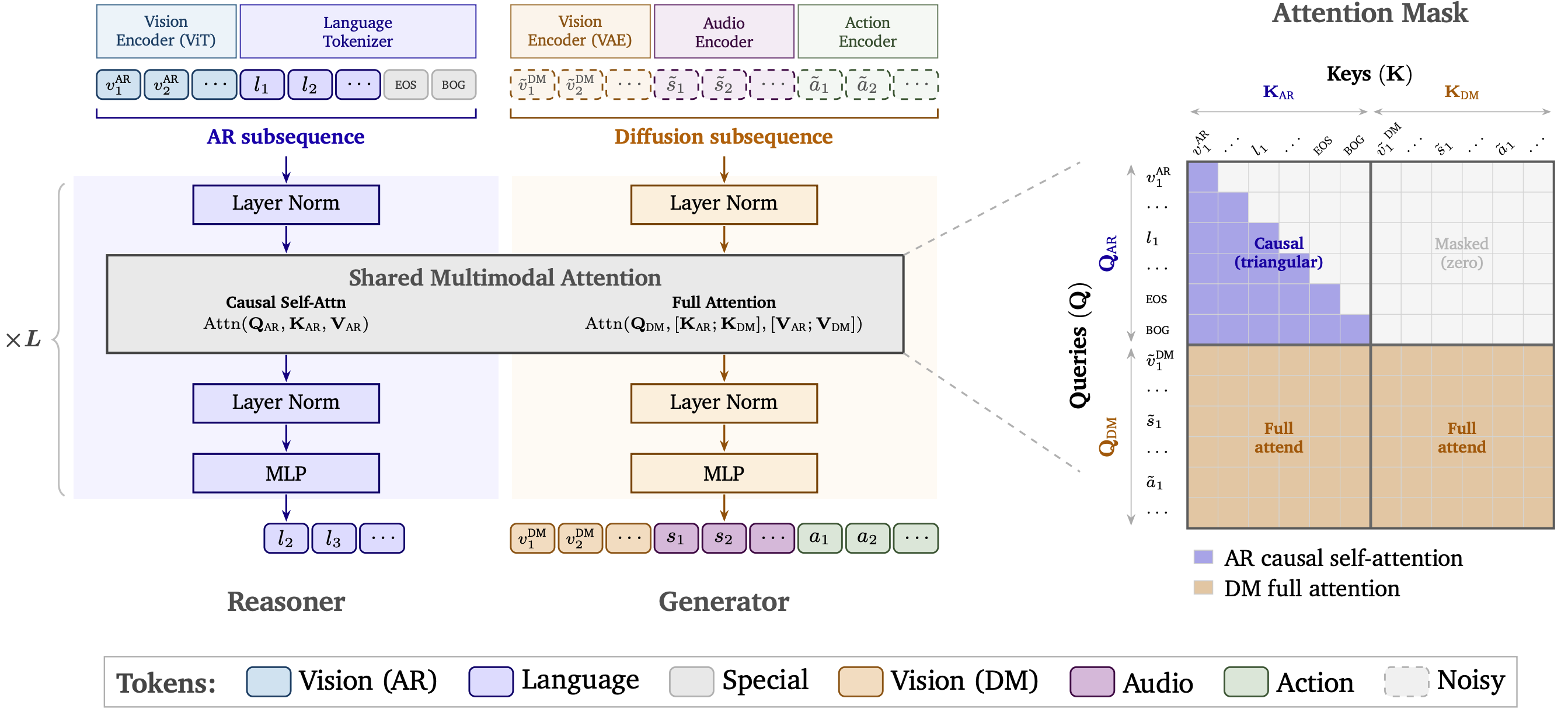
- 기존 Physical AI pipeline은 VLM, video world model, VLA/WAM, forward dynamics model을 따로 붙이는 구조라서 비효율적인데, Cosmos 3는 이를 AR Reasoner + Diffusion Generator 구조로 통합한다.
- 핵심은 AR token subsequence와 diffusion token subsequence를 한 sequence로 묶고, Reasoner는 causal attention, Generator는 AR+DM 전체에 full attention을 하도록 설계한 dual-tower MoT다.
- 로봇 관점에서 가장 중요한 부분은 action을 별도 head가 아니라 core modality로 넣어 forward dynamics, inverse dynamics, policy를 같은 sequence modeling 문제로 만든 점이며, DROID policy는 4 diffusion steps로 32개 joint-position action을 15Hz에서 생성하도록 post-training된다.
| 기존 별도 모델 | Cosmos 3에서의 역할 |
|---|---|
| VLM | AR Reasoner mode |
| Text-to-Image / Video generator | Diffusion Generator mode |
| Forward dynamics model | action-conditioned video denoising |
| Inverse dynamics model | video-conditioned action denoising |
| VLA / WAM policy | joint action-video denoising |
| Synthetic data generator | post-trained generator |
| Robot policy | DROID post-trained policy |