



OSCAR: Omni-Embodiment Skeleton-Conditioned World Action Model for Robotics
pretrained Cosmos-Predict2.5-2B video DiT를 2D kinematic skeleton condition으로 fine-tuning하여, 여러 robot embodiment와 human hand에 걸쳐 action-conditioned future video를 생성하고 이를 RoboArena policy evaluation proxy로 쓴다
Overview Figure
Summary
- 기존 action-conditioned video world model은 robot policy evaluation에 쓰기 위해서는 정확한 action following, 다양한 scene/task/action coverage, cross-embodiment generalization이 필요하지만, latent-action 방식은 action이 압축되어 spatial-temporal motion을 정밀하게 따르기 어렵고, dense geometry 방식은 특정 robot appearance나 embodiment에 overfit되기 쉽다.
- OSCAR는 이 문제를 2D kinematic skeleton rendering과 대규모 표준화 데이터 파이프라인(curates, filters, and deduplicates broad robotics and egocentric human datasets)으로 해결하려고 한다.
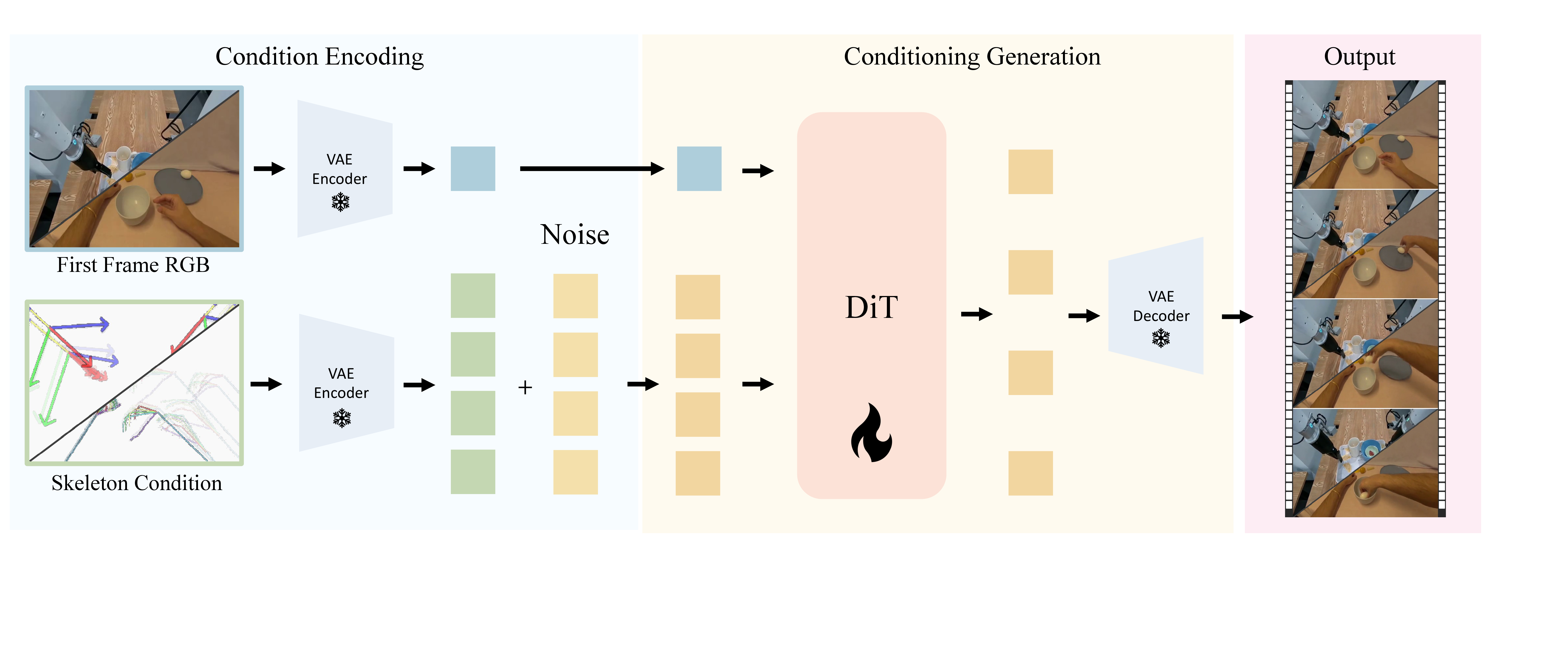
- 핵심 아이디어는 robot joint trajectory를 image plane에 skeleton video로 렌더링해서, DiT video generator가 “어디서/언제 robot이 움직여야 하는지”를 pixel-aligned condition으로 직접 보게 만드는 것이다.
- 모델은 pretrained Cosmos-Predict2.5-2B를 기반으로, first RGB frame과 skeleton condition을 VAE latent로 인코딩한 뒤 DiT에서 denoising하여 future video를 생성한다.
- 실험에서는 평균적으로 PSNR/SSIM/LPIPS/FVD/FID/latent-L2에서 강한 성능을 보이고, RoboArena의 real-world policy ranking과 virtual evaluation ranking 사이에 유의미한 상관을 보였다고 주장한다.