



Do as I Do: Dexterous Manipulation Data from Everyday Human Videos
monocular RGB human manipulation video를 4D hand–object trajectory로 복원하고, pretrained SAM 3D를 training-free guided flow sampling으로 object tracker처럼 재활용한 뒤, MuJoCo Warp의 dynamics-aware sampling optimization으로 22-DoF Sharpa Wave hand가 실행할 수 있는 robot trajectory로 변환하는 offline robot-data engine
Overview Figure
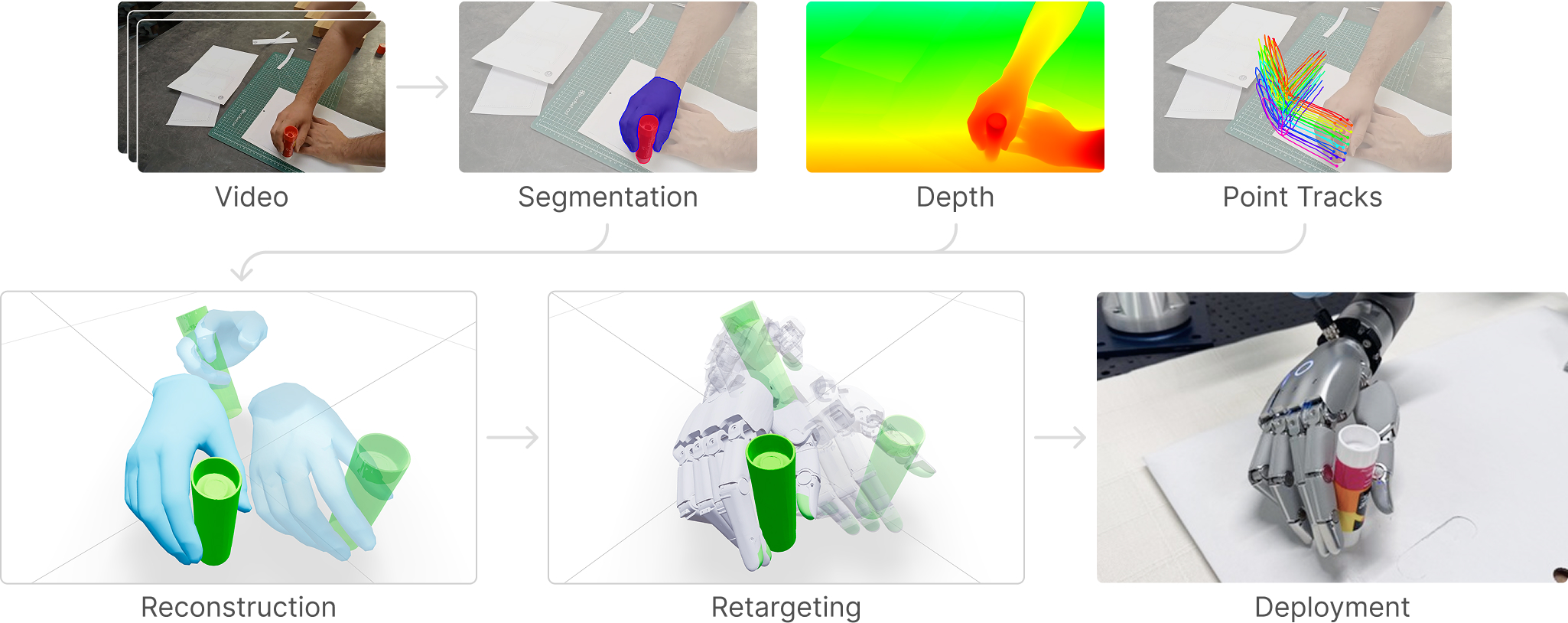
Summary
- 기존 human-video 기반 robot data 생성은 monocular depth/contact ambiguity, object tracking drift, 그리고 human–robot morphology 차이 때문에 실제 multi-finger robot trajectory까지 안정적으로 변환하기 어려웠다.
- 이 논문은 인터넷·egocentric·exocentric·generated monocular RGB video를 실제 dexterous hand에서 실행할 수 있는 trajectory로 바꾸는 것을 목표로 한다.
- 핵심 아이디어는 SAM 3D의 joint shape–pose flow에서 object shape block은 anchor frame의 canonical shape로 강하게 guide하고, pose block은 이전 frame의 pose로 guide하되 현재 frame의 visual evidence를 반영하여 temporally coherent object tracking을 수행하는 것이다.
- 복원된 noisy hand–object trajectory는 먼저 fingertip matching 기반 kinematic retargeting으로 rough robot reference로 변환되고, 이후 MuJoCo Warp에서 warmup, random-force perturbation, transition reward를 포함한 MPPI-style sampling optimization을 통해 dynamically feasible trajectory로 보정된다.
- Reconstruction benchmark를 개선하고 noisy reconstructed reference에서 simulated retargeting success를 25%에서 71%로 높였으며, 10개 task trajectory의 real-robot replay도 보였지만, downstream policy 학습, quantitative real-world success rate, visual closed-loop robustness까지 입증한 논문은 아니다.
Key Components
- Training-free SAM 3D Object Tracking
- Modular 4D reconstruction: 먼저 SAM 3로 hand/object mask를 추출하고, MoGe로 monocular depth와 camera intrinsics를 추정하며, HaWoR로 시간에 따른 human hand motion을 복원한다. SAM 3D는 anchor frame 한 장에서 manipulated object의 3D mesh와 shape–pose representation을 생성한다.
- Anchor-frame shape guidance: SAM 3D를 각 frame에 독립적으로 적용하면 frame마다 object mesh가 달라질 수 있다. 이를 막기 위해 첫 anchor frame에서 얻은 canonical object shape를 이후 모든 frame의 shape block에 강하게 guide하여, 동일한 rigid object가 시간에 따라 움직인다는 consistency를 부여한다.
- Previous-pose-guided flow sampling: frame $k$의 object pose를 생성할 때 frame $k-1$의 pose를 reference로 사용한다. 다만 이전 pose를 그대로 복사하는 것이 아니라, 현재 RGB image와 object mask에 대한 SAM 3D의 denoising update를 유지하면서 flow trajectory를 previous pose의 interpolant 방향으로 부드럽게 끌어당긴다.
- Adaptive pose guidance: object motion이 작을 때는 이전 pose를 강하게 신뢰하지만, 빠르게 회전하는 구간에서 같은 guidance strength를 사용하면 pose가 과도하게 고정될 수 있다. 이를 피하기 위해 object mask 내부의 20개 point를 BootsTAPIR로 tracking하고, 인접 frame 사이의 estimated rotation magnitude에 따라 pose guidance strength $\alpha_p$를 낮추거나 높인다.
- Best-of-$N$ pose consensus: guided sampling은 stochastic하기 때문에 각 frame에서 $N=25$개의 pose candidate를 생성한다. 후보들을 translation과 quaternion rotation을 함께 고려하는 weighted $SE(3)$ distance로 clustering하고, 작은 cluster를 outlier로 제거한 뒤, rendered silhouette과 input object mask의 IoU가 높은 cluster를 최종 pose로 선택한다.
- Hand–object alignment: HaWoR의 hand reconstruction과 SAM 3D의 object reconstruction은 서로 다른 scale과 depth를 가질 수 있다. MoGe pointmap에서 측정한 hand–object relative offset을 이용해 object를 camera viewing ray 방향으로 이동시켜, 두 reconstruction을 하나의 near-metric 4D hand–object trajectory로 정렬한다.
- Dynamics-aware Human-to-Robot Retargeting
- Kinematic initialization: 복원된 human hand trajectory를 바로 physics optimization에 넣기 전에, Mink를 사용해 human fingertip 위치와 Sharpa Wave fingertip 위치가 최대한 일치하도록 kinematic retargeting한다. 이 단계는 contact force나 object dynamics를 고려하지 않으며, 이후 optimizer가 탐색을 시작할 rough reference를 제공한다.
- MPPI-style sampling optimization: MuJoCo Warp에서 robot control sequence 주변에 다수의 perturbation을 sampling하고, 각 candidate를 physics simulation으로 rollout한 뒤 object pose, hand-base pose, finger joints, penetration 등을 평가한다. 논문의 기본 설정은 3초 planning horizon, 0.5초마다 planning, planning step당 1,024개 sample과 32번의 optimization iteration이다.
- Warmup steps: monocular reconstruction의 첫 frame이 부정확하면 robot hand가 object를 잡지 못한 상태에서 trajectory가 시작될 수 있다. 이를 보완하기 위해 reference 앞에 warmup 구간을 추가하고, 이 동안 object를 simulation에 고정한 채 robot hand만 움직여 안정적인 initial grasp 또는 contact configuration을 찾게 한다. 이 component 하나만으로 reconstructed-reference success가 25%에서 66%로 크게 증가한다.
- Random-force perturbation: nominal simulation에서 잠깐 trajectory를 따라가는 것만으로는 object를 fingertip 위에 불안정하게 올려놓는 brittle solution이 선택될 수 있다. 일부 rollout에 작은 random force와 torque를 가하고도 object interaction을 유지하는 control을 선호하게 만들어, minor disturbance에 더 robust한 grasp와 manipulation trajectory를 찾는다.
- Transition reward: pick-up이나 place처럼 object가
rest상태와in-hand상태 사이를 전환하는 순간에는 일반적인 pose-tracking reward만으로 contact 발생 여부를 정확히 표현하기 어렵다. 따라서 reference가 rest 상태일 때 object–floor contact가 없거나, in-hand 상태일 때 hand–object contact가 없으면 별도 penalty를 부여하여 pickup/place transition 자체가 성공하도록 유도한다. - Robot deployment: 최적화 결과는 Sharpa Wave hand-base와 finger trajectory 형태이므로, 이를 UR3e arm의 inverse kinematics로 변환한다. 이후 dual-arm digital twin에서 self-collision과 table contact를 확인하고, 초기 $x,y,z,\mathrm{yaw}$를 robot workspace에 맞춘 뒤 실제 robot에서 approximately half speed, 50 Hz로 replay한다.