



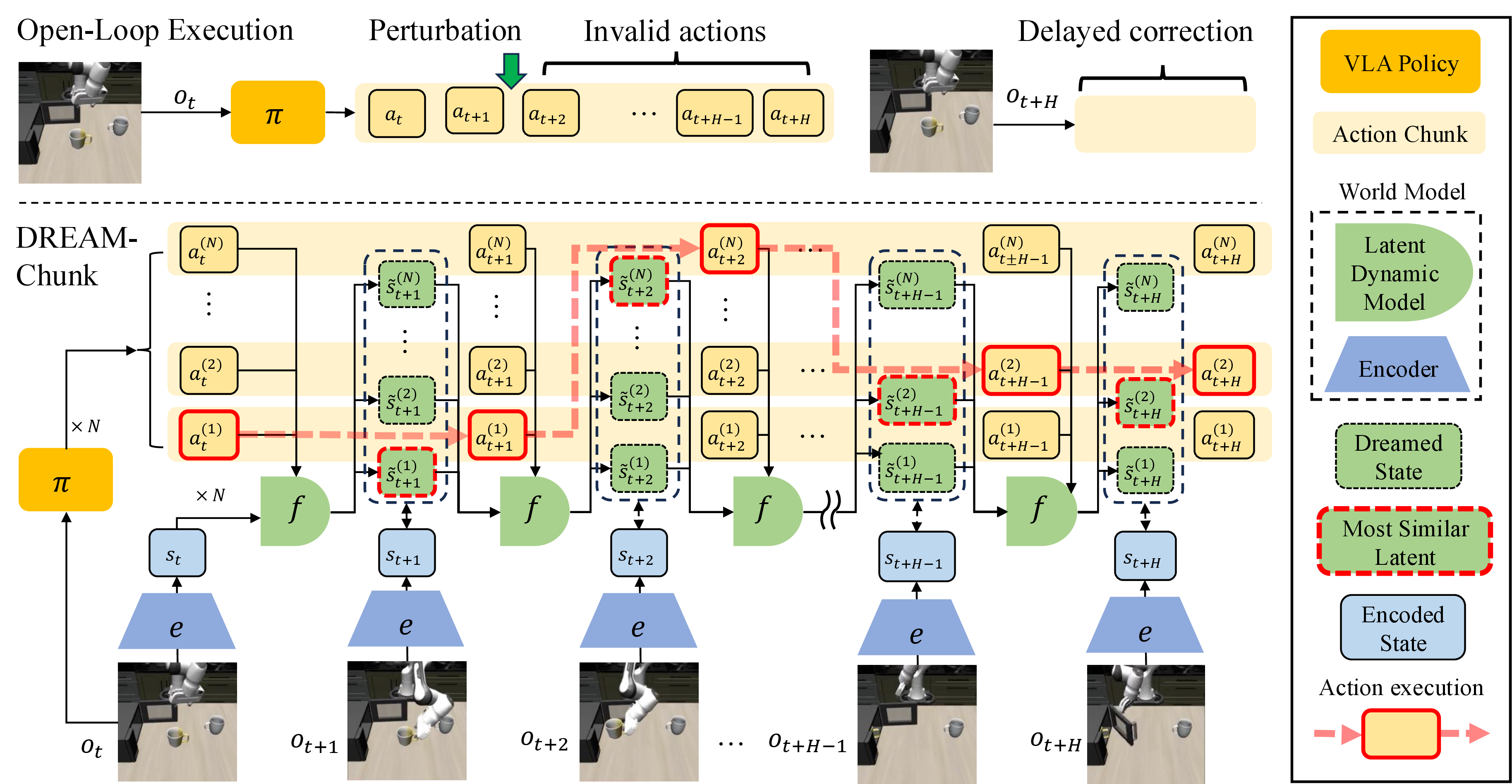
DREAM-Chunk: Reactive Action Chunking with Latent World Model
frozen action-chunking VLA가 샘플링한 N개 candidate chunk의 latent future를 lightweight world model로 예측하고, 매 control step마다 현재 observation과 가장 가까운 phase-aligned dreamed state의 action으로 전환해 VLA를 다시 호출하지 않고 within-chunk reactivity를 높이는 test-time scaling method
Overview Figure

Summary
- 기존 action chunking은 느린 VLA inference를 낮은 주기로 수행하면서 높은 control rate를 유지할 수 있지만, chunk 후반부 action은 점점 오래된 observation에 기반하므로 stochastic dynamics, hardware execution error, partial observability에 취약하다.
- 이 논문은 base VLA를 추가로 fine-tuning하거나 매 control step마다 다시 호출하지 않고도 within-chunk reactivity를 높이는 문제를 다룬다.
- 핵심 아이디어는 현재 observation에서 여러 candidate action chunk를 한 번에 샘플링하고, auxiliary latent world model로 각 candidate의 phase-aligned latent rollout을 예측한 뒤, 실행 중 실제 observation과 가장 잘 맞는 candidate를 계속 선택하는 것이다.
- Base policy는 고정되며, 별도로 학습한 observation encoder $e$와 action-conditioned latent dynamics model $f$가 candidate별 future state를 예측한다. 매 control step마다 새 observation을 encoding하고, 현재 phase에서 가장 가까운 dreamed latent를 가진 candidate의 동일 phase action을 실행한다.
- Kinetix에서는 action noise가 강하고 candidate 수 $N$이 클수록 baseline 대비 상대적 이득이 커졌으며, corrective behavior가 포함된 demonstration으로 학습한 policy에서 test-time scaling 효과가 더 컸다. SO-101의 세 task에서도 성공률이 모두 향상되었고, Franka can insertion은 local $N=5$에서 10%에서 65%로 상승했지만, 더 큰 remote candidate pool에서는 sampling 및 communication latency가 이득을 상쇄했다.