



SC3-Eval: Evaluating Robot Foundation Models via Self-Consistent Video Generation
pretrained Cosmos3-Nano video foundation model을 forward dynamics, inverse dynamics, cross-view inpainting의 세 mode로 공동 fine-tuning하고, inference에서는 commanded action과 generated video에서 inverse dynamics로 복원한 action의 불일치를 rollout reliability signal로 사용해 frozen VLA policy를 multi-view video world model 안에서 closed-loop 평가하는 method
Overview Figure

Summary
- 실제 로봇에서 generalist manipulation policy를 반복 평가하는 것은 robot time, reset, supervision 비용이 크며, 기존 action-conditioned video evaluator는 autoregressive drift, camera-view inconsistency, policy-induced distribution shift에 취약하다.
- 이 논문은 video world model 내부에서 수행한 closed-loop policy rollout이 실제 로봇에서의 success rate와 failure mode를 충실하게 재현하도록 만드는 것을 목표로 한다.
- 핵심 아이디어는 하나의 shared video-action transformer를 forward dynamics, inverse dynamics, cross-view inpainting의 세 mode로 학습하여 generated video가 action-recoverable하고 multi-view coherent하도록 만드는 것이다.
- Inference에서는 policy가 예측한 25-step action chunk 중 첫 24 actions로 future multi-view video를 생성하고, 그중 첫 16 frames에서 action을 inverse dynamics mode로 복원한다. Commanded action과 recovered action의 평균 L2 error가 threshold를 넘으면 rollout을 종료하고, 그렇지 않으면 첫 16 frames를 다음 policy observation으로 사용해 replanning한다.
- 381시간의 단일 real-world table-bussing 데이터와 7개 $\pi_{0.5}$ checkpoint를 사용한 실험에서 전체 closed-loop Pearson correlation 0.929, MMRV 0.119를 달성했지만, 평가 범위가 동일 policy architecture·동일 scene·동일 embodiment에 한정되고 full reproduction 비용이 매우 높다.
Key Components
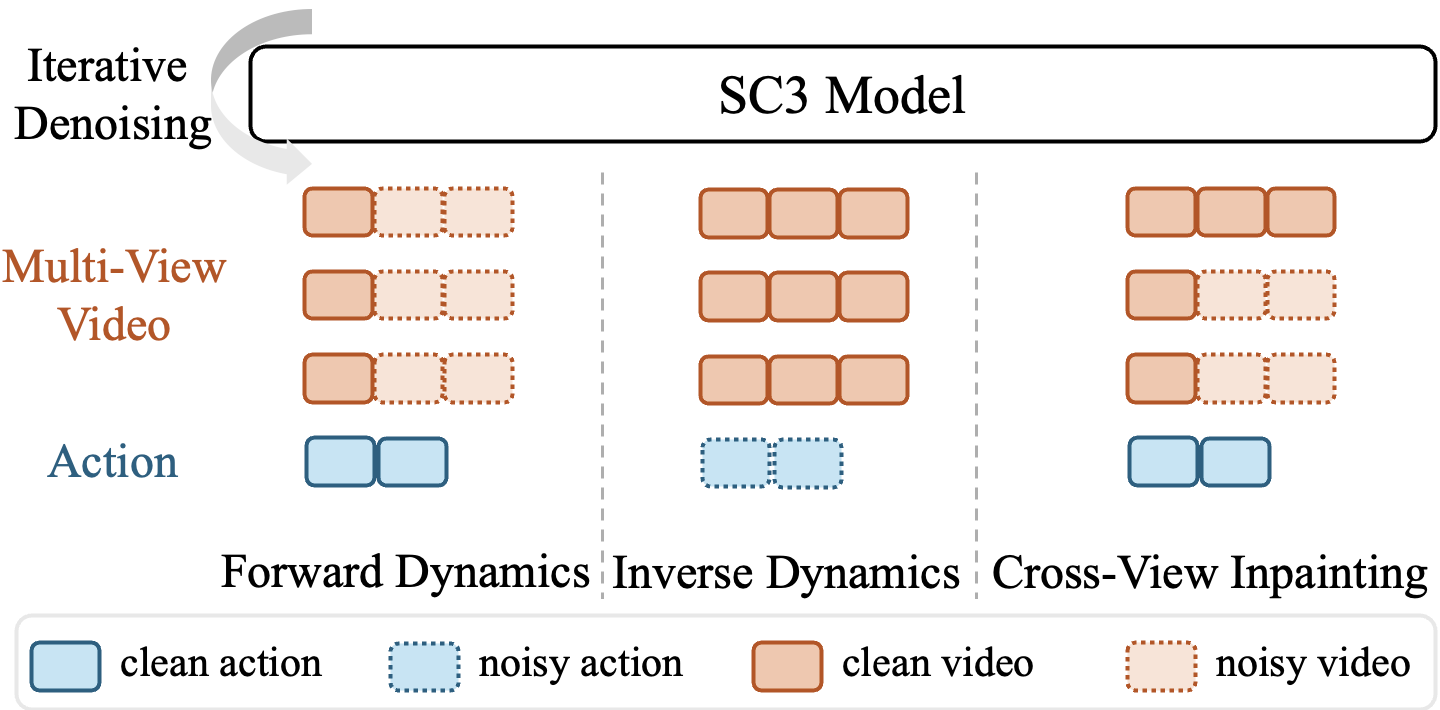
Three-mode self-consistency training (하나의 model을 세 가지 방향으로 학습)
- SC3-Eval은 forward dynamics model, inverse dynamics model, cross-view model을 각각 따로 두는 구조가 아니다. 하나의 Cosmos3-Nano 기반 shared video-action transformer를 사용하고, 각 training sample에서 어떤 token을 clean condition으로 제공하고 어떤 token을 noise로 만들어 복원하게 할지만 변경한다.
-
세 mode 모두 동일한 transformer parameter와 flow-matching objective를 공유한다. 따라서 하나의 network가 action으로 future video를 생성하는 능력, video로 action을 추론하는 능력, 한 camera view로 다른 view를 복원하는 능력을 함께 학습한다.
- Forward Dynamics: action → future video
- 현재 또는 초기 multi-view frame과 앞으로 수행할 action chunk를 clean condition으로 제공한다.
- Future video token은 noise 상태에서 시작하며, model은 action에 대응하는 미래의 three-camera video를 denoise한다.
- 이것이 실제 closed-loop evaluation에서 virtual environment의 dynamics 역할을 담당한다.
- Inverse Dynamics: video → action
- 전체 video trajectory를 clean condition으로 제공하고, action token을 noise로 만든 뒤 원래 action chunk를 복원하도록 학습한다.
- 즉, generated video 속 robot과 object의 움직임을 보고 “이 움직임을 만들기 위해 어떤 action이 실행되었는가?”를 맞히는 mode다.
- Forward와 inverse mode가 parameter를 공유하므로, forward mode도 단순히 visually plausible한 frame이 아니라 inverse mode가 원래 commanded action을 다시 읽어낼 수 있는 frame을 생성하도록 간접적으로 regularization된다.
- 예를 들어 commanded action은 cup을 오른쪽으로 옮기도록 지시하는데 generated video에서는 cup이 거의 움직이지 않았다면, inverse mode가 원래 action을 정확히 복원하기 어려워진다. 이런 불일치가 forward-only video model에서 발생하기 쉬운 autoregressive drift를 줄이는 추가 신호가 된다.
- 다만 이는 generated video를 다시 inverse mode에 넣어 직접 cycle loss를 계산하는 explicit cycle-consistency training은 아니다. Forward와 inverse task가 parameter를 공유하면서 생기는 implicit regularization에 가깝다.
- Cross-View Inpainting: 한 camera view → 나머지 camera views
- 학습 중 external camera 또는 wrist camera 중 한 view만 clean하게 제공하고, 나머지 view들은 noise 상태에서 복원하도록 한다. Action도 condition으로 함께 사용된다.
- 따라서 model은 각 view를 독립적인 video처럼 생성하는 대신, 모든 camera가 동일한 object 배치와 동일한 robot state를 바라보도록 학습된다.
- 특히 wrist camera가 manipulation 도중 workspace 밖을 보거나 robot arm에 가려졌다가 다시 workspace를 바라보는 경우가 중요하다. Cross-view inpainting이 없으면 wrist view가 이전에 hallucinate한 잘못된 scene을 계속 유지할 수 있지만, 이 objective를 사용하면 두 external views를 참고해 올바른 workspace state로 복귀할 가능성이 높아진다.
- 다만 camera calibration이나 depth를 이용하는 explicit 3D geometric consistency는 아니다. Training data에서 학습한 statistical multi-view consistency이다.
action-recoverable의 정확한 의미- Generated video가
action-recoverable하다는 것은 video 속 motion cue만 보고 inverse mode가 commanded action을 다시 예측할 수 있다는 뜻이다. - 이것은 generated video가 실제 physics를 완벽히 만족한다는 보장은 아니다. 동일한 model의 forward와 inverse mode가 함께 틀리는 self-consistent-but-wrong 상황은 여전히 가능하다.
- Generated video가
Closed-loop inference (25 actions → 24-frame prediction → 16-frame execution)
- Policy proposal: 평가 대상인 frozen $\pi_{0.5}$ policy는 현재 generated observation을 입력받아 10 Hz 기준 25개의 action을 예측한다.
- 24-frame world-model prediction: SC3-Eval은 그중 첫 24 actions를 forward dynamics mode에 넣어, three-camera view 각각에 대해 24개의 future frames를 생성한다. 10 Hz 기준으로 약 2.4초의 미래를 예측하는 셈이다.
- 16-frame virtual execution: 생성된 24 frames를 모두 다음 observation으로 사용하는 것은 아니다. 첫 16 frames만 실제로 실행된 것처럼 observation history에 추가하고, 나머지 8 frames는 버린다.
- Closed-loop replanning: 유지된 첫 16 frames를 다시 policy에 입력하여 다음 action chunk를 예측한다. 따라서 여기서 closed-loop란 physical robot이 움직인다는 뜻이 아니라, policy가 world model이 생성한 observation을 보고 반복적으로 action을 다시 결정한다는 의미이다.
-
10 Hz에서 16 steps는 약 1.6초이므로, policy는 generated world 안에서 약 1.6초마다 replanning한다. 각 16-step chunk 내부에서는 open-loop에 가깝고, chunk 사이에서 feedback이 들어오는 receding-horizon 구조다.
- Inverse-mode action recovery
- 각 chunk에서 생성된 첫 16 frames를 inverse dynamics mode에 입력해 16개의 action $\hat{a}_i$를 복원한다.
- 이를 policy가 실제로 명령했던 action $a_i$와 비교해 다음 consistency error를 계산한다.
- $U_{\text{chunk}}$가 작으면 generated video 속 motion이 commanded action과 비교적 잘 일치한다는 뜻이다.
- 반대로 값이 크면 forward mode가 요청받은 action과 다른 motion을 생성했거나, rollout이 training distribution 밖으로 drift하여 forward와 inverse mode가 서로 일관되지 않게 되었다고 해석한다.
- Uncertainty-driven early termination
- 논문은 held-out 30 trajectories에서 선택한 threshold $\tau=0.02$를 사용한다.
- 다음 조건을 만족하면 rollout을 즉시 종료한다.
- 이미 action과 video가 서로 어긋난 상태에서 rollout을 계속 생성하면, 잘못된 frame이 다음 policy input이 되고 그로부터 더 비정상적인 action이 나오는 autoregressive error가 누적될 수 있다. Early termination은 이 drift가 이후 score 전체를 오염시키기 전에 rollout을 중단하는 역할을 한다.
- 이 값은 ensemble uncertainty나 calibrated failure probability가 아니다. 논문에서도 이를 empirical reliability indicator, 즉 현재 chunk를 계속 신뢰할 수 있는지 판단하는 경험적 신호로 해석한다.
- 왜 16 frames만 사용할 것인데 24 frames를 생성하는가?
- Cosmos3 backbone은 훨씬 긴 video clip으로 pretraining되었기 때문에, 처음부터 16-frame horizon만 사용해 fine-tuning하면 pretrained temporal prior와 지나치게 다른 짧은-horizon distribution으로 이동하여 generation quality가 낮아진다.
- 또한 짧은 16-frame clip에는 object가 거의 움직이지 않는 구간이 많아 dynamics를 학습할 motion supervision이 부족할 수 있다.
- 따라서 model은 24-frame prediction horizon으로 학습해 더 긴 motion context를 보존하되, 실제 closed-loop rollout에서는 policy의 native execution schedule에 맞춰 첫 16 frames만 사용한다. 논문은 이를 prediction–execution horizon decoupling이라고 부른다.