



MolmoMotion: Forecasting Point Trajectories in 3D with Language Instruction
RGB history, object 위의 2D query points와 corresponding initial 3D coordinates, language instruction을 입력받아 object-attached point들의 미래 3D world-frame trajectory를 예측하도록 Molmo2를 대규모 human/robot/in-the-wild video로 pretrain하고, 이 motion prior가 robot policy initialization과 video generation guidance로 전이됨을 보임
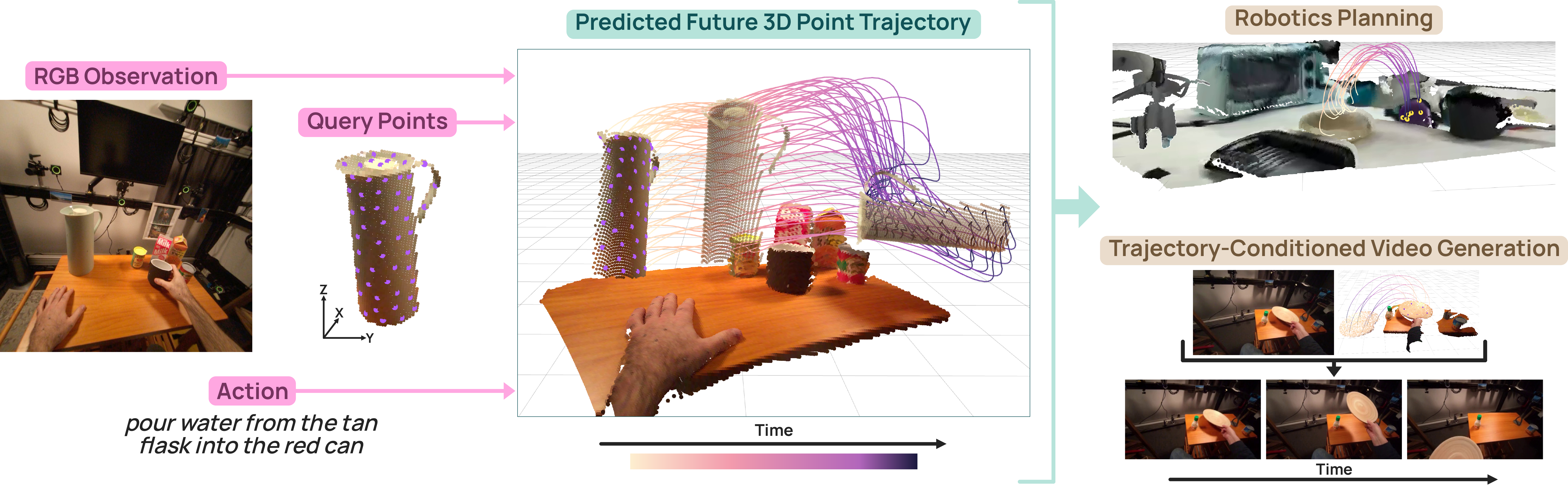
Overview Figure
Summary
- 기존 pixel/video prediction은 appearance rendering에 큰 resource를 쓰고, 2D point trajectory는 camera motion과 object motion이 얽히며, 6-DoF pose나 parametric model은 특정 object category와 rigid-body 가정에 제한된다.
- 이 논문은 category와 embodiment에 덜 종속적이고, metric-scale 3D geometry를 명시적으로 표현하며, downstream robot learning과 planning에 활용하기 쉬운 goal-conditioned 3D point motion forecasting 문제를 정의한다.
- 핵심 아이디어는 물체 표면의 sparse query point들을 physical landmark로 두고, 이들의 미래 위치를 reference time $t_0$의 camera에 anchor된 metric world coordinate frame에서 예측하며, language instruction으로 여러 plausible future 중 intended motion을 disambiguate하는 것이다.
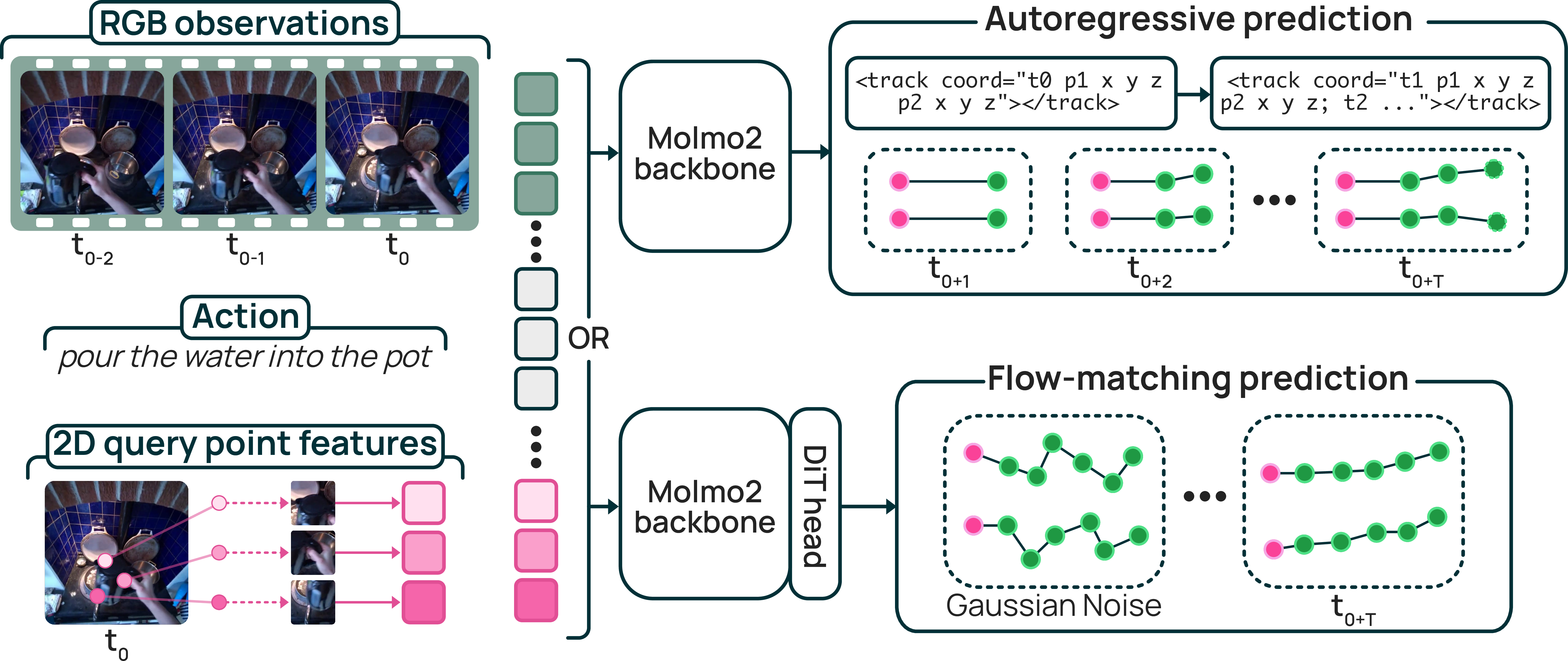
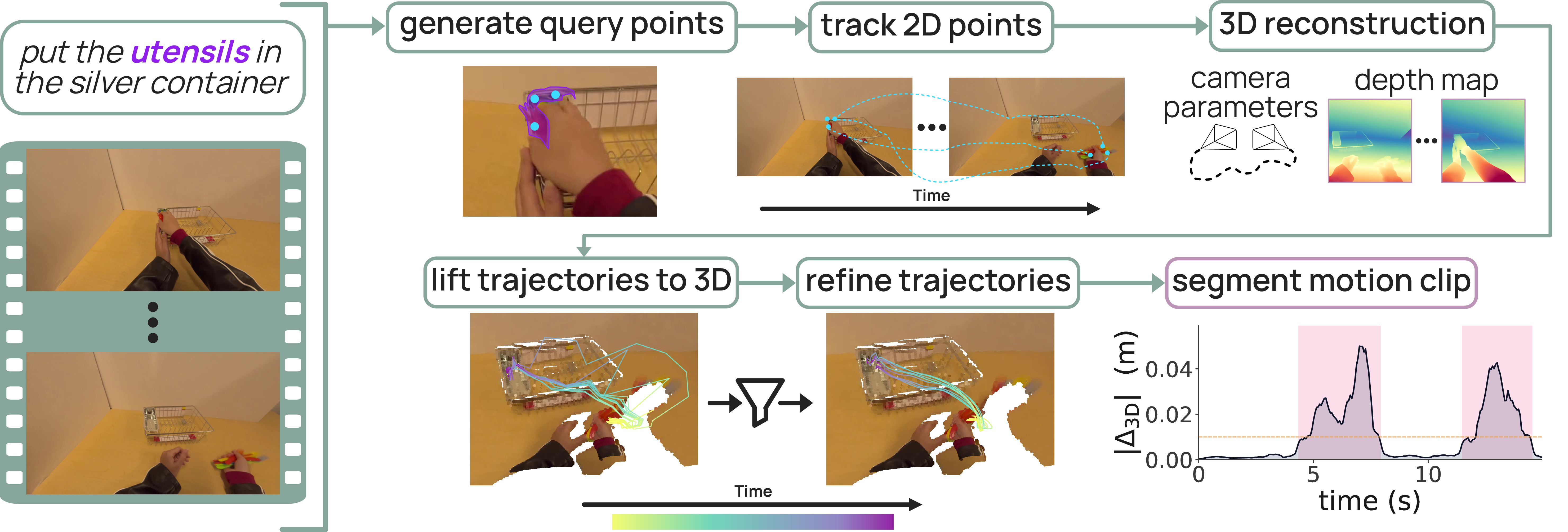
- Molmo2-4B backbone의 LM head로 millimeter-quantized coordinate sequence를 생성하는 autoregressive variant와, continuous trajectory를 생성하는 flow-matching DiT variant를 각각 학습하며, 이를 위해 약 1M motion clip 규모의 MolmoMotion-1M과 742-clip PointMotionBench를 구축한다.
- PointMotionBench에서는 autoregressive variant가 전반적으로 가장 정확했고, simulated MolmoSpaces의 post-grasp pick-and-place policy를 MolmoMotion으로 초기화하면 평균 closed-loop success가 56.0%에서 76.3%로 높아졌지만, MolmoMotion trajectory를 이용한 explicit online planning과 real-world robot closed-loop control은 평가하지 않았다.
Key Components
- Object-attached sparse query points
- 모델은 물체 전체의 미래 RGB frame이나 category-specific 3D mesh를 생성하지 않고, 물체 표면에 놓인 소수의 query point들을 동일한 physical point를 나타내는 landmark로 사용한다.
- 입력으로는 reference time $t_0$에서의 2D query-point 위치와 이에 대응하는 initial 3D coordinates가 주어지며, 모델은 이후 각 point가 시간에 따라 3D space에서 어디로 이동할지를 예측한다.
- 여러 point의 움직임을 함께 보면 object의 translation뿐 아니라 rotation, articulation, 그리고 제한적인 deformation까지 하나의 category-independent representation으로 나타낼 수 있다.
- 다만 long-horizon training에서는 context-length 제약 때문에 object당 기본적으로 $N=8$개의 point만 사용하므로, dense geometry나 복잡한 deformable motion을 완전히 표현하는 것은 어렵다.
- Reference-camera-anchored metric world frame
- 각 미래 point를 매 frame의 image coordinate나 moving camera coordinate로 표현하지 않고, reference time $t_0$의 camera pose를 기준으로 고정된 하나의 3D coordinate frame에 표현한다.
- 따라서 이후 camera가 움직이거나 viewpoint가 바뀌더라도, camera ego-motion이 object motion에 직접 섞이지 않고 동일한 physical motion을 일관된 3D trajectory로 나타낼 수 있다.
- 여기서 말하는
world frame은 전역 지도 좌표가 아니라, $t_0$ camera를 기준으로 locally anchored된 metric frame이다.
- Anchor-relative coordinate parameterization
- 고정된 world frame을 정의하는 것과 별개로, 모델 내부에서는 첫 번째 query point의 초기 위치를 $ \mathbf{p}_{\mathrm{anc}} = \mathbf{p}_{t_{0}}^{1} $ 로 두고, 각 coordinate를 $ \boldsymbol{\delta}_{t}^n = \mathbf{p}_{t}^n - \mathbf{p}_{\mathrm{anc}} $ 와 같은 anchor-relative displacement로 표현한다.
- 이렇게 하면 모델이 scene마다 달라지는 absolute position보다 object 내부의 relative geometry와 실제 motion displacement에 집중할 수 있다.
- 실제 ablation에서도 absolute world coordinates를 그대로 사용하면 ADE/FDE가 전반적으로 약 50% 악화되어, 이 parameterization이 핵심적인 inductive bias임을 보여준다.
- 최종 예측에서는 $\mathbf{p}_{\mathrm{anc}}$를 다시 더해 metric world-frame trajectory를 복원한다.
- Language instruction as a future-motion selector
- 하나의 현재 observation만으로는 미래가 결정되지 않는다. 예를 들어 동일한 cup도 그대로 둘 수 있고, 들어 올리거나, 왼쪽으로 옮기거나, bowl 안에 넣을 수 있다.
- Language instruction은
"pick up the cup","slide the cup to the left","put the cup in the bowl"처럼 어떤 object가 어느 방향과 목적을 향해 움직여야 하는지를 지정하여 가능한 future distribution을 좁힌다. - 즉, language가 trajectory 자체를 대신 생성하는 것이 아니라, visual history와 initial geometry만으로는 모호한 여러 motion mode 중 intended future를 선택하기 위한 goal condition으로 작동한다.
- Language를 제거하고 모든 instruction을 단순히
"motion"으로 대체한 ablation에서는 성능이 크게 하락하므로, instruction은 부가적인 caption이 아니라 실제 motion direction을 결정하는 핵심 conditioning signal이다.
- Embodiment-independent motion prior
- Human hand와 robot gripper는 서로 다른 joint structure와 action space를 사용하지만, 성공적으로 물체를 옮겼을 때 나타나는 object-level 3D trajectory는 유사할 수 있다.
- MolmoMotion은 이 공통 object motion을 pretraining target으로 사용하여 human video, robot video, simulation, in-the-wild video 사이에서 공유 가능한 motion prior를 학습한다.
- MolmoSpaces 실험에서는 MolmoMotion이 예측한 trajectory를 robot이 직접 추종한 것이 아니라, MolmoMotion-pretrained backbone으로 MolmoBot policy를 초기화한 뒤 robot action data로 fine-tuning했다.