



EgoEngine: From Egocentric Human Videos to High-Fidelity Dexterous Robot Demonstrations
egocentric human manipulation video를 digital twin 기반으로 변환해, robot observation video와 실행 가능한 로봇 action trajectory를 함께 생성하고, 이를 이용해 real-robot dexterous visuomotor policy를 학습하는 human-video-to-robot-demo data engine
Overview Figure
Summary
- 기존 dexterous manipulation policy는 고품질 robot demonstration 수집 비용이 너무 크고, human egocentric video는 풍부하지만 human hand/arm과 robot embodiment 사이의 visual gap 및 human motion과 robot-executable action 사이의 action gap 때문에 바로 policy 학습에 쓰기 어렵다.
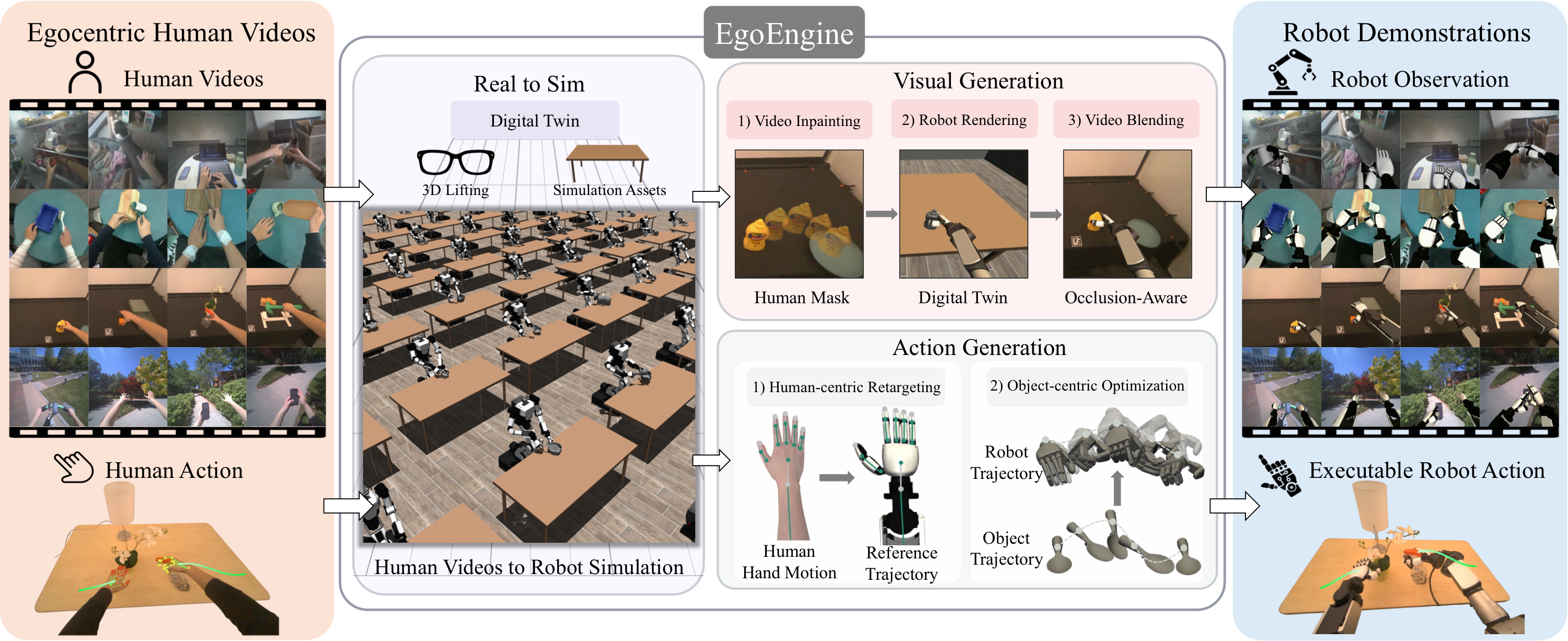
- EgoEngine은 egocentric RGB human video를 입력으로 받아, 원래 scene context와 temporal alignment를 보존하면서 human을 robot으로 대체한 robot observation video와, object motion에 정렬된 executable robot action trajectory를 함께 만든다.
- 핵심 아이디어는 human video를 단순히 video editing하거나 hand retargeting하는 것이 아니라, object-centric digital twin을 만들고 그 안에서 visual generation branch와 action generation branch를 병렬로 실행하는 것이다.
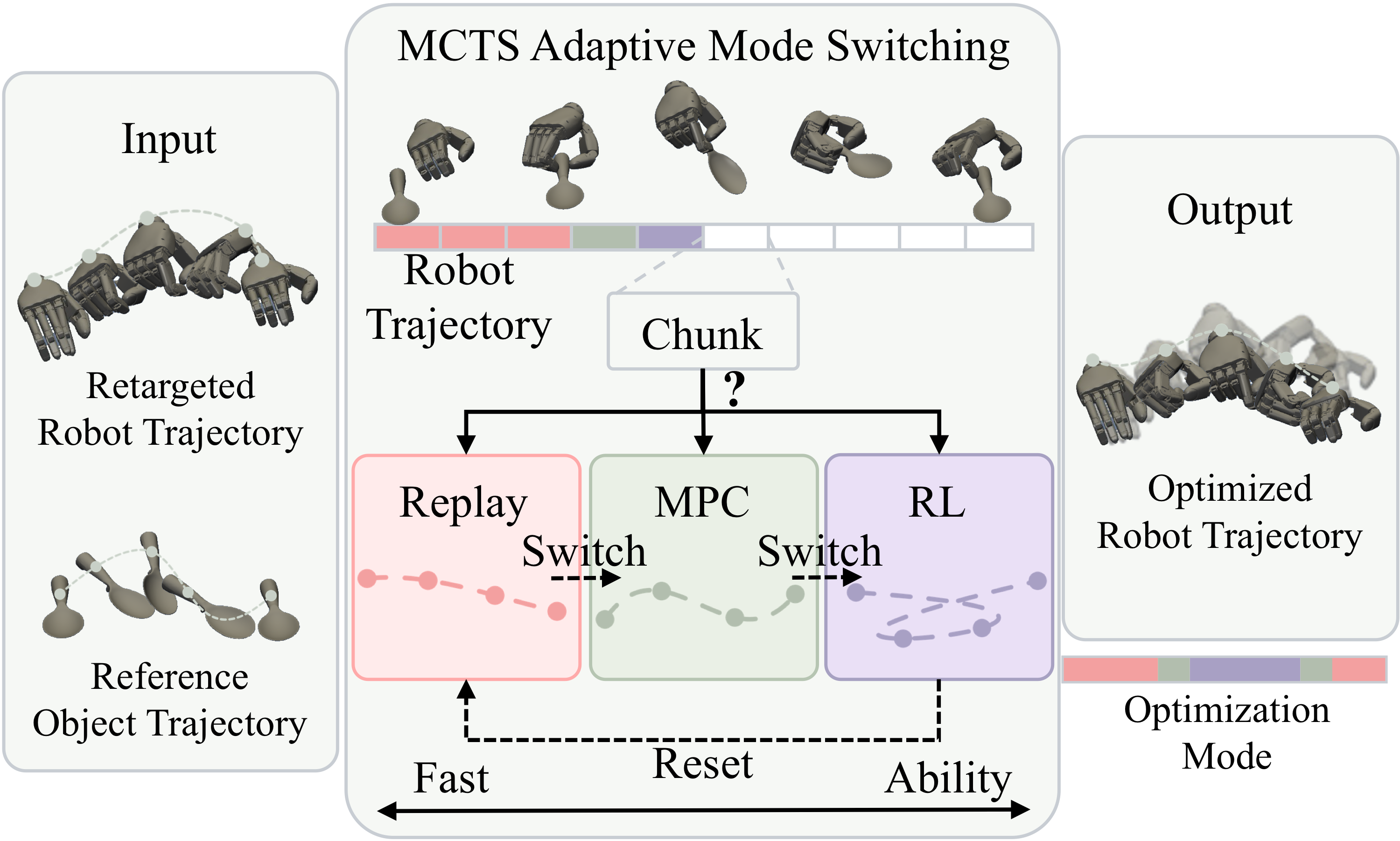
- Action branch는 MINK 기반 human-to-robot retargeting 이후, object pose tracking reward를 기준으로 Replay → MPC → RL을 chunk 단위로 adaptive switching하여 trajectory를 refine하고, visual branch는 inpainting + robot rendering + occlusion-aware blending으로 robot-view observation을 만든다.
- 실험에서는 TACO/Aria 기반 visual fidelity, simulation action fidelity, real-robot downstream policy success를 평가하며 (비교용 real-robot teleoperation demo는 수집했지만 EgoEngine 학습에는 사용하지 않고) egocentric human video만으로 zero-shot dexterous visuomotor policy learning이 가능하다고 주장한다.