



µ0: A Scalable 3D Interaction-Trace World Model
pretraining 단계에서는 action-labeled robot data 없이 heterogeneous videos에서 추출한 semantic 3D interaction traces를 학습하고, downstream에서는 frozen trace world model의 hidden features를 action expert에 주입해 robot policy를 만드는 3D trace-space world model
Overview Figure

Summary
- 기존 pixel-space video world model은 dense appearance reconstruction에 capacity를 많이 쓰고, 기존 VLA / direct action model은 embodiment-specific action label이 필요해 scale이 어렵다.
- 이 논문은 “무엇이 움직여야 하는가”를 pixel이나 robot action이 아니라 objects, tools, hands, contact regions의 3D interaction traces로 표현하면 video-only pretraining을 robot control로 더 잘 transfer할 수 있다고 본다.
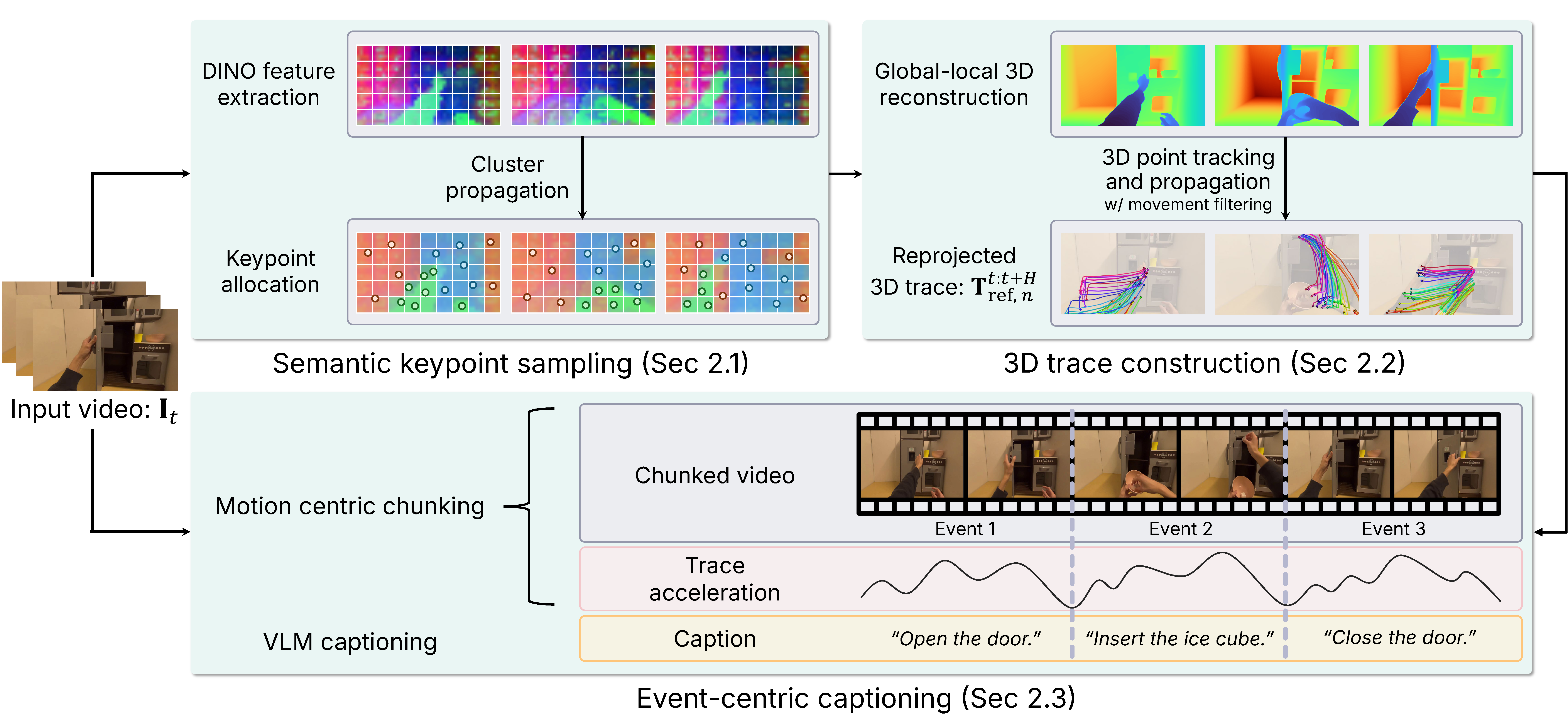
- 이를 위해 TraceExtract가 DINOv2 semantic keypoint sampling, globally aligned 3D tracking, event-centric captioning을 통해
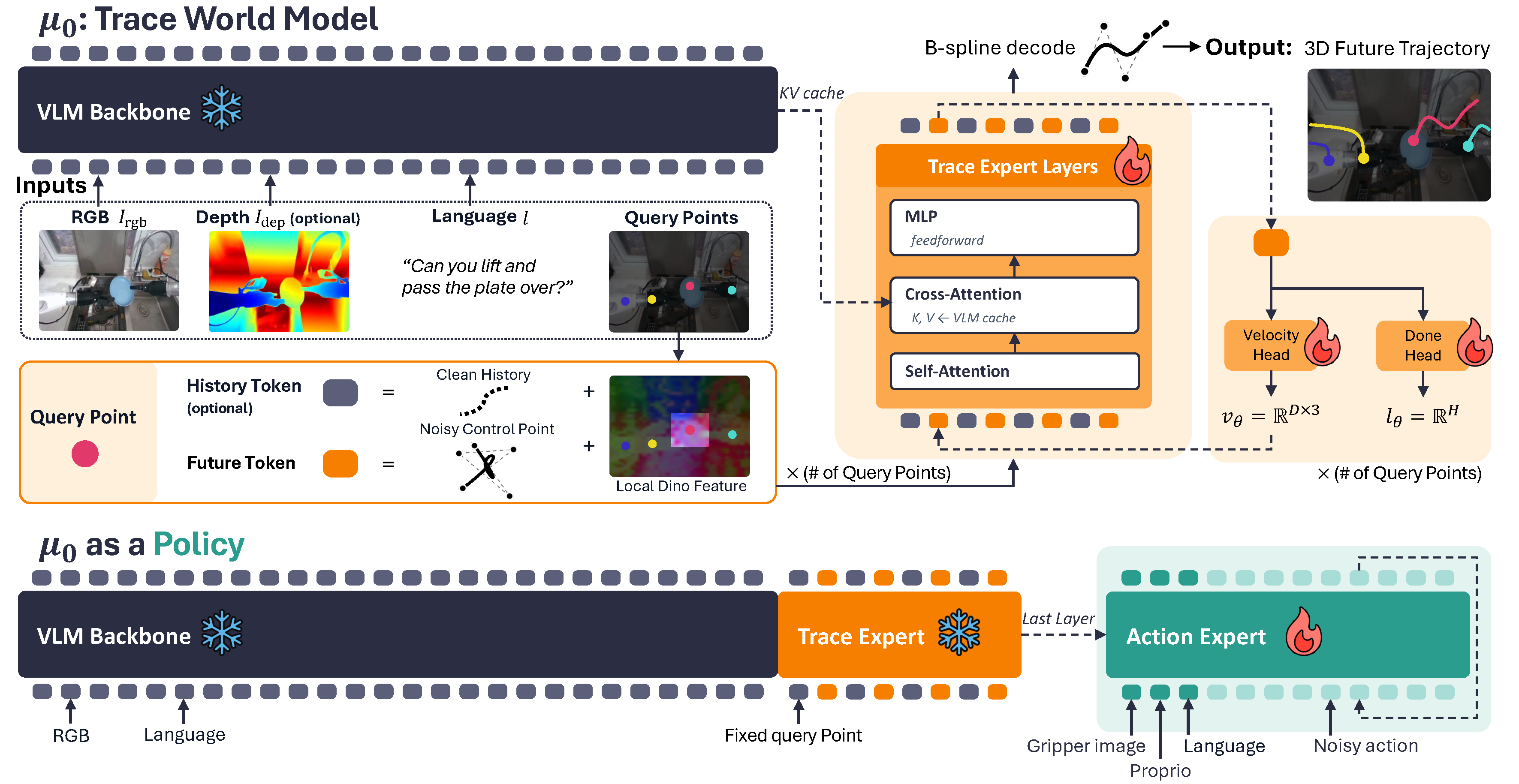
{observation, language, 3D trace}supervision을 자동 생성한다. - $\mu_{0}$는 SmolVLM2 기반 VLM backbone + permutation-equivariant Trace Expert + B-spline control-point flow matching으로 미래 3D traces를 예측하고, downstream에서는 $\mu_{0}$를 freeze한 뒤 single partial-denoising step에서 얻은 trace hidden feature를 gated cross-attention으로 action expert에 주입해 continuous action chunks를 생성한다.
- 실험에서는 2D/3D trace prediction에서 강한 성능을 보이고, RoboCasa365 simulation 평균 성공률 30.25%로 $\pi_{0}$는 넘지만 $\pi_{0.5}$에는 못 미치며, UR3 real-world in-distribution 3개 task에서는 평균 91.7%의 success rate를 달성한다.