



FlowDPG: Deterministic Policy Gradient on Flow Matching Policies for Real-World Manipulation
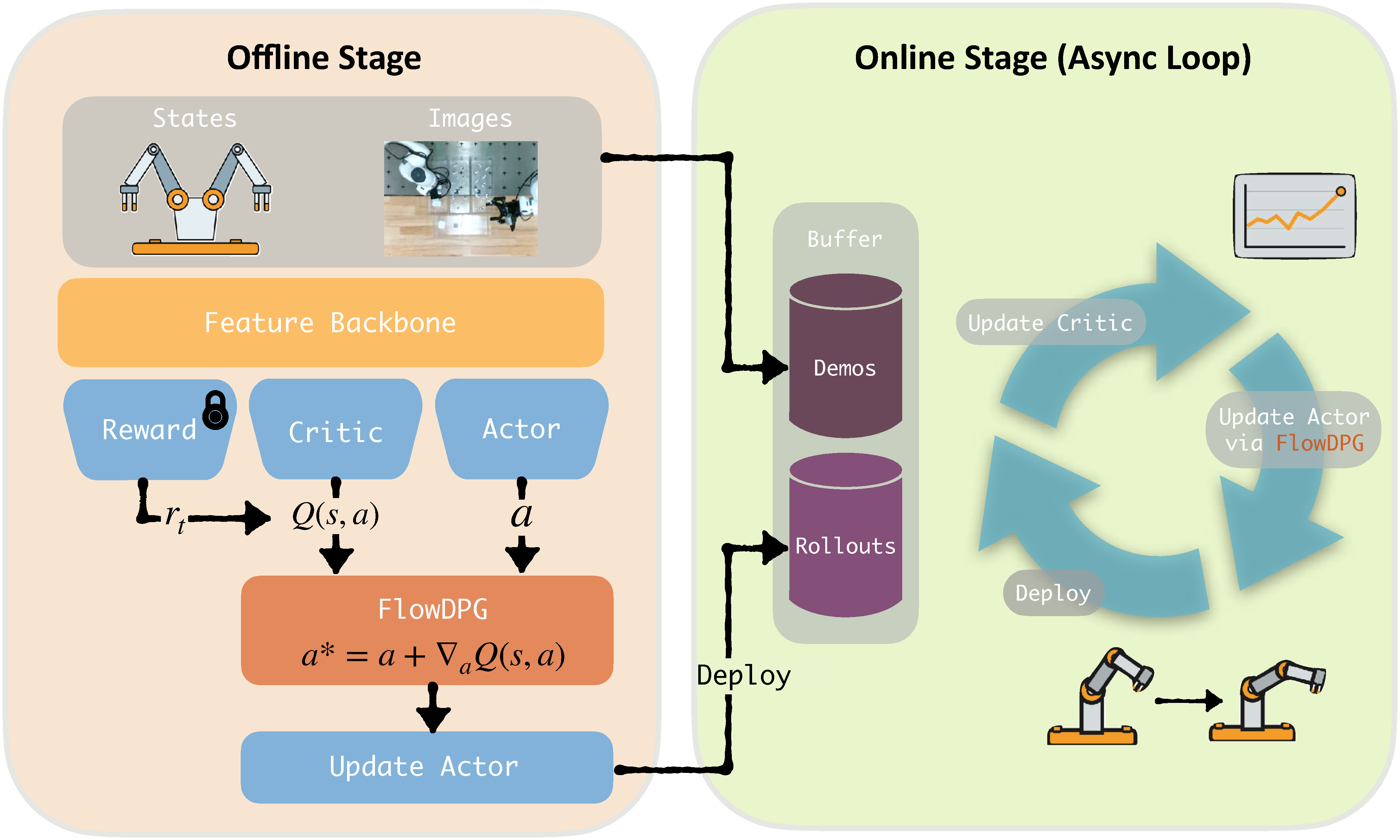
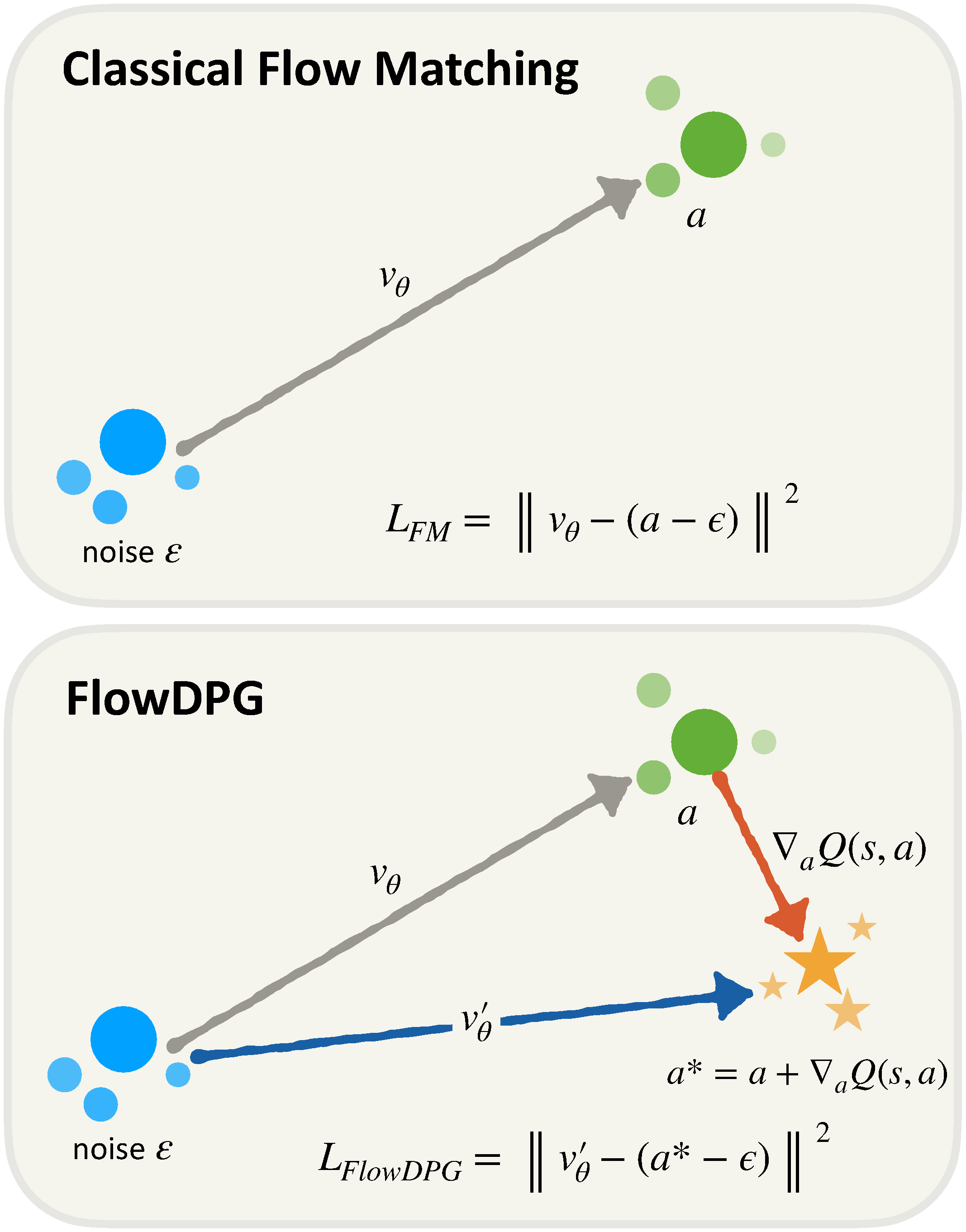
flow matching robot policy의 중간 noisy action을 clean action chunk로 한 번에 projection한 뒤, 그 지점의 critic gradient를 value-improved velocity target으로 distillation하여 전체 denoising ODE를 backpropagation하지 않고도 offline-to-online real-world RL을 수행
Overview Figure
Summary
- 기존 flow matching robot policy에 DDPG-style actor update를 적용하려면 final action에 대한 critic gradient를 multi-step ODE 전체로 backpropagation해야 하므로, training memory와 연산량이 solver step 수에 따라 증가하고 Jacobian product 때문에 gradient explosion/vanishing이 발생할 수 있다.
- 이 논문은 flow policy의 multi-modal action-generation 능력을 유지하면서도, ODE BPTT 없이 critic의 action gradient를 actor에 전달하는 offline-to-online RL을 목표로 한다.
- 핵심 아이디어는 임의의 flow timestep $t$에서 velocity predictor 한 번으로 clean action $\hat{a}$를 추정하고, $\nabla_{a}Q(s,\hat{a})$ 방향으로 이를 이동시켜 value-improved action target $a^*$를 만든 뒤 해당 target velocity를 flow field에 L2 regression하는 것이다.
- 모델은 DINOv2 기반 multi-view visual backbone, DiT flow actor, SARM stage-aware reward model, IQL value network 및 twin critics로 구성되며, offline demonstration 학습 후 real-world rollout을 수집하여 actor와 critic을 asynchronous하게 계속 업데이트한다.
- dual-Franka AirPods assembly에서 BC의 64%보다 28 percentage points 높은 92% end-to-end success를 얻었고, strongest reported RL baselines의 80%보다 12 points 높았지만, 평가는 하나의 robot platform과 하나의 task family에 국한된다.
Further Analysis
- 이 논문의 실제 novelty는 backbone이 아니라 actor update rule이다
- DINOv2, DiT, IQL, twin critic, SARM은 각각 기존 구성요소이다. 새 contribution은 critic gradient를 ODE endpoint까지 직접 backpropagation하지 않고 supervised velocity target으로 변환하는 policy extraction objective에 있다.
- FlowDPG는 inference-time steering이 아니다
- critic과 reward model은 training에서만 사용된다. Deployment에서는 기존 flow policy와 동일하게 noise에서 action chunk까지 ODE를 적분하며, critic query나 candidate search가 추가되지 않는다.
- 성능은 FlowDPG objective만으로 나온 것이 아니다
- stage label, within-stage progress, terminal reward를 제공하는 SARM reward model이 매우 중요한 역할을 하며, reward ablation에서 이 shaping이 제거되면 policy가 BC보다 나빠지기도 한다.
- 논문의 compute claim은 이론적으로 타당하지만 system measurement가 없다
- BPTT의 $O(T)$ activation-memory 문제는 제거하지만, 실제 wall-clock, peak VRAM, throughput을 BPTT나 QAM과 비교한 결과는 보고하지 않는다.