



World Value Models for Robotic Manipulation
Pretrained Wan2.2 video world model을 robot video로 jointly fine-tune하면서 별도의 lightweight value DiT를 Mixture-of-Transformers로 결합해, video와 language로부터 4-frame task-progress chunk를 flow matching으로 생성하고 그 progress 변화량으로 suboptimal data를 filtering·reweighting하는 generalist robotic value model
Overview Figure
Summary
- 기존 robotic value model은 scalar supervision에 의존하고, task-specific하게 설계되며, static image 중심으로 pretrain된 VLM backbone 때문에 hesitation·retry와 같은 dense temporal behavior를 정확히 추적하기 어렵다.
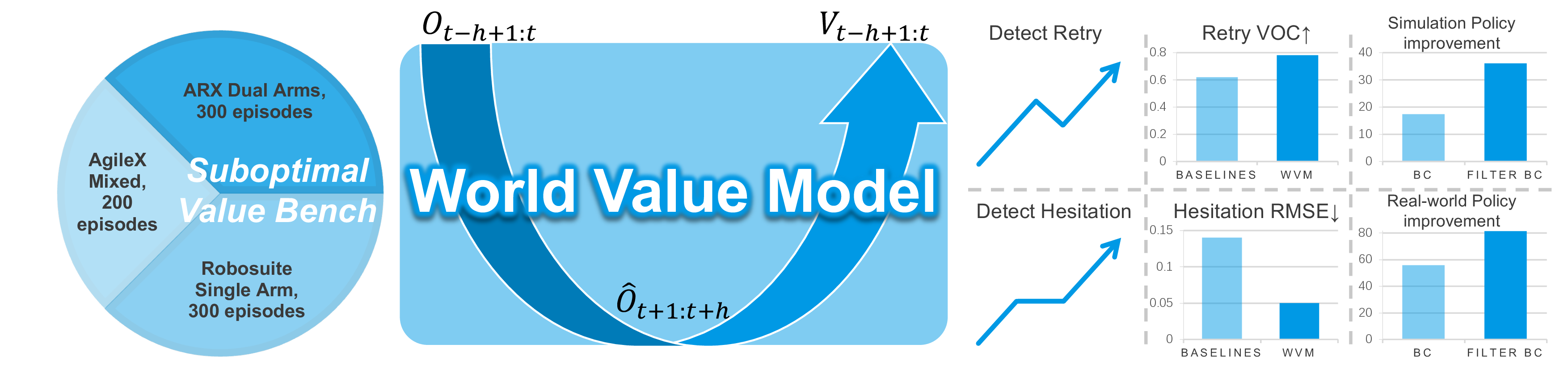
- 이 논문은 large-scale heterogeneous video에서 task progress를 추정하여 mixed-quality robot data의 품질을 평가할 수 있는 generalist value model을 만들고자 한다.
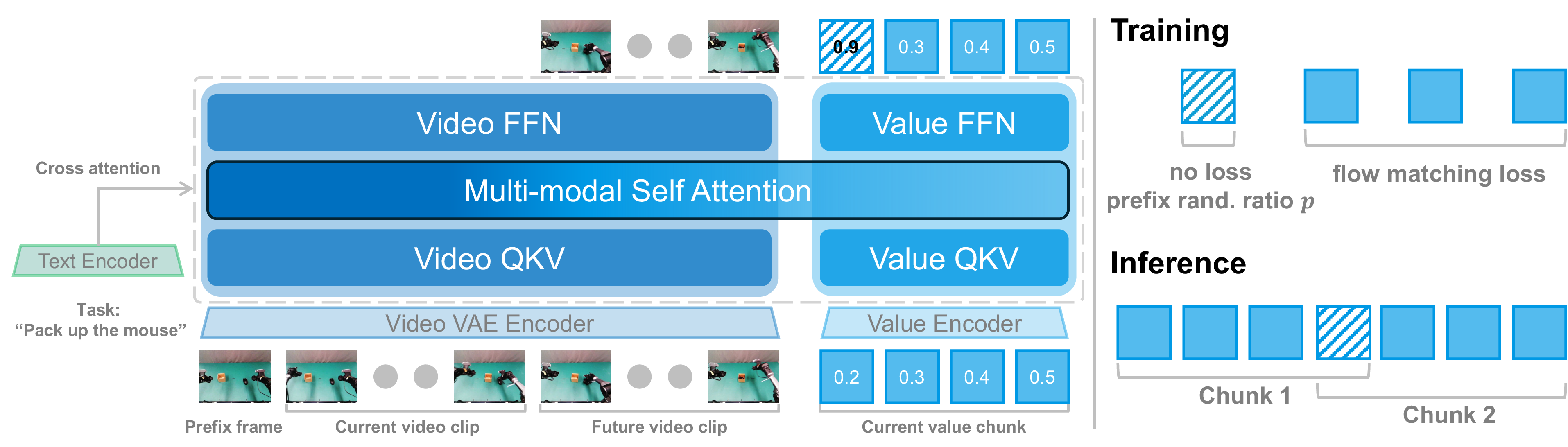
- 핵심 아이디어는 pretrained video world model의 temporal prediction prior를 value learning의 backbone으로 사용하고, 개별 scalar가 아니라 plateau와 regression을 포함하는 distributional value chunk를 flow matching으로 학습하는 것이다.
- Wan2.2-TI2V-5B video DiT와 약 0.7B value DiT를 asymmetric MoT attention으로 연결하고, future-video flow loss와 value-flow loss를 함께 최적화하며 prefix randomization과 video rewinding을 적용한다.
- WVM은 평균 Hesitation-RMSE 0.05, Retry-VOC 0.78, Expert-VOC 0.95를 기록하고, WVM 기반 AWR·Filtered BC가 simulation과 real robot에서 vanilla BC보다 높은 성공률을 보였다.
Further Analysis
- WVM의 역할
- WVM이 예측하는 것은 엄밀한 RL state value라기보다 language-conditioned visual task progress에 가깝다. 기본 training target이 $v_{t}=t/T$이기 때문이다.
- World model의 역할
- inference-time rollout이나 MPC를 수행하는 것이 아니라, future-video prediction으로 학습된 latent representation을 value head가 읽는다.
- Action-free scaling
- action label 없이 video와 task description만으로 학습할 수 있어 EgoDex 같은 human egocentric video까지 활용할 수 있다.
- Downstream 역할
- WVM은 recorded action chunk가 실행된 뒤 관찰된 progress 증가량을 계산해 imitation-learning sample을 weighting한다. 따라서 본 실험에서는 post-hoc offline critic이다.
- 핵심 비판
- flow matching의 우월성을 주장하지만, 가장 중요한 비교인 scalar chunk regression versus flow chunk가 없다.
- Closed-loop 관점
- 최종 $\pi_{0.5}$ policy의 success rate는 개선되지만 WVM 자체는 deployment-time closed loop에 개입하지 않는다.