



UniFS: Unified Fast-to-Slow Hierarchical Architecture for Vision-Language-Action Models
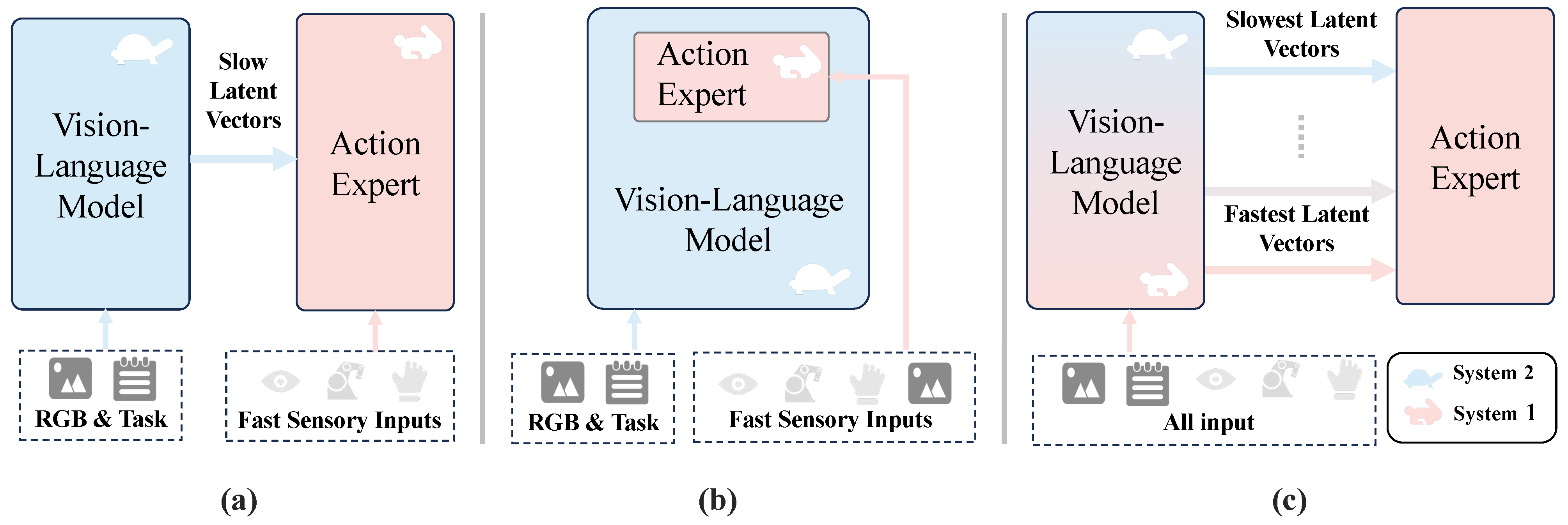
pretrained VLM과 action expert의 각 layer group을 서로 다른 주기로 실행·cache하도록 학습하고, VLM feature와 action decoding stage의 연결 순서를 뒤집어, VLA-Adapter의 success rate를 높이면서 평균 inference latency를 줄인 scheduler-aware VLA architecture
Overview Figure
Summary
- 기존 Fast-Slow VLA는 VLM과 action expert를 하나의 고정된 주기로 연결하기 때문에, 갱신 간격이 크면 stale semantic context가 쌓이고 간격이 작으면 계산 절감 효과가 사라지는 frequency dilemma가 발생한다.
- 또한 action expert가 VLM의 final-layer feature만 받으므로, layer마다 서로 다른 temporal dynamics를 갖는 intermediate feature를 활용하지 못한다.
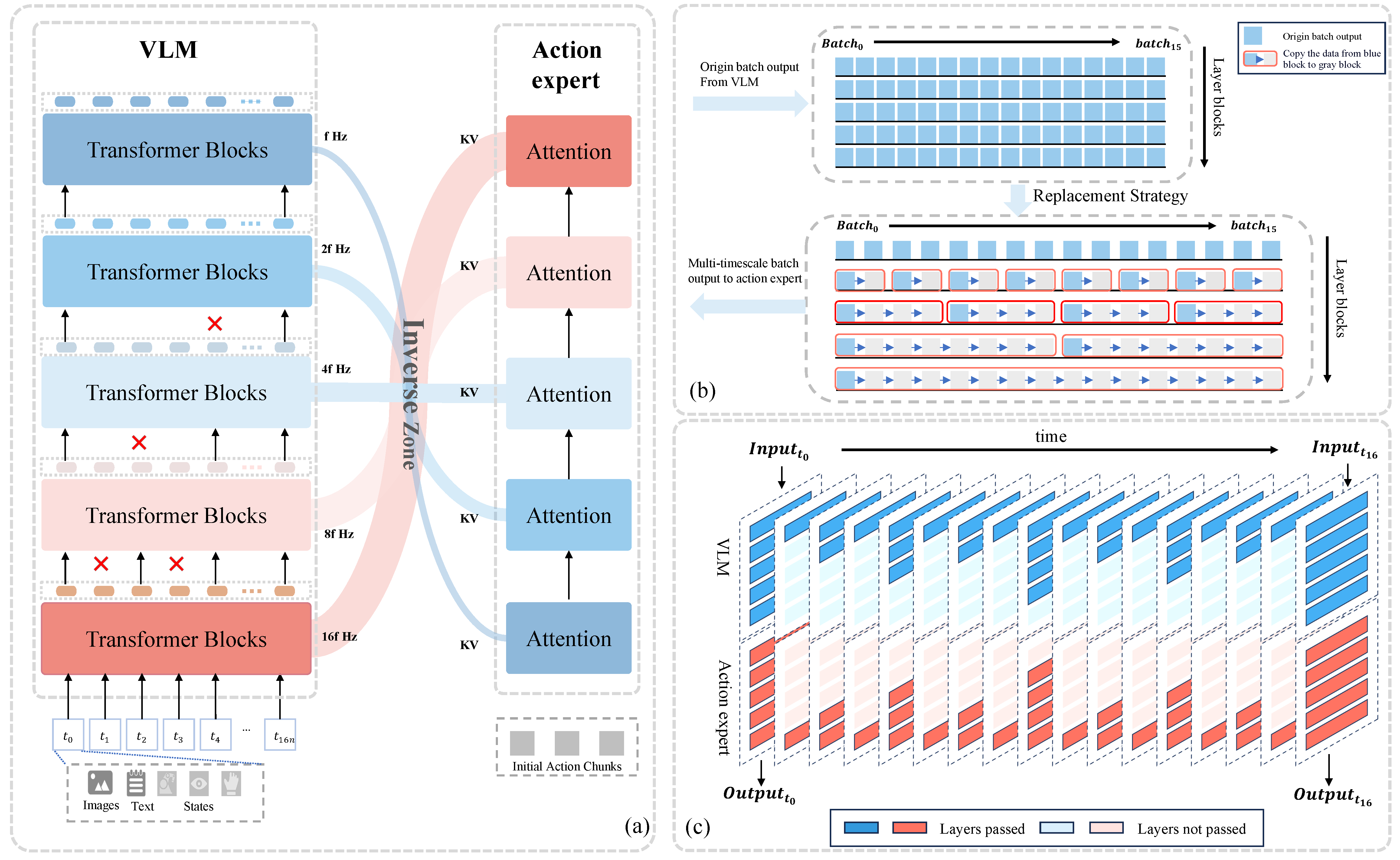
- UniFS는 VLM과 action expert를 여러 frequency group으로 나누는 Fast-to-Slow Architecture, VLM feature와 action-expert layer의 연결 순서를 뒤집는 Latent Vector Inversion, 각 frequency level에 action supervision을 부여하는 Multi-Level Supervision을 제안한다.
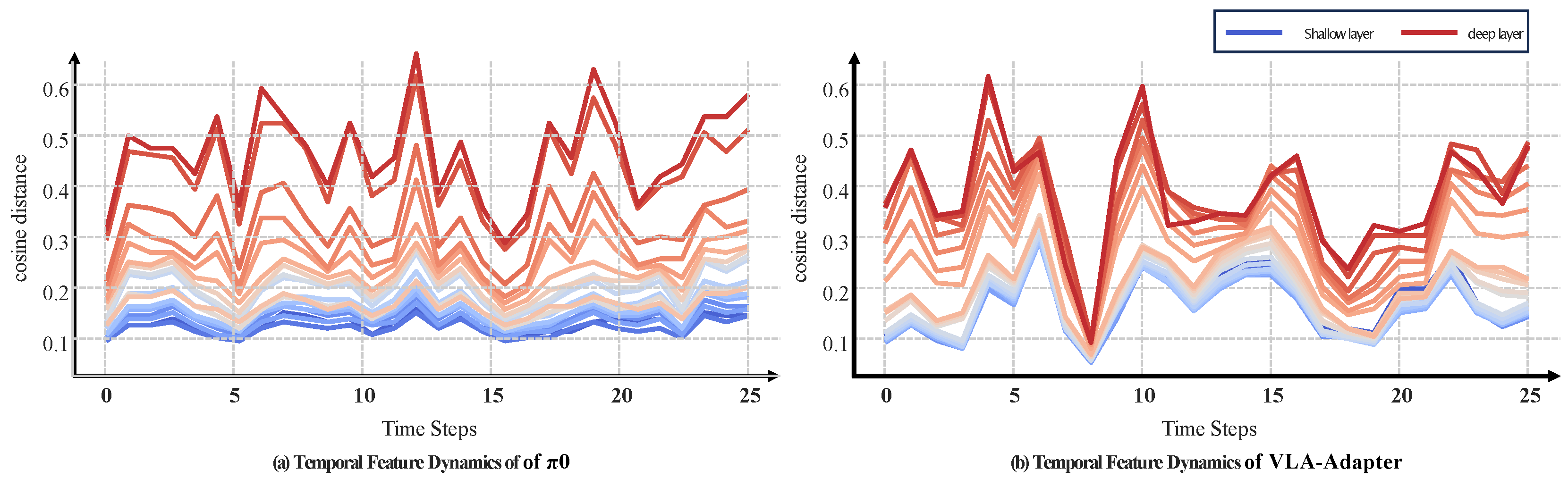
- 저자들은 deeper layer가 더 높은 temporal frequency(cosine distance 변동)를 보인다는 것을 발견했다(2번째 figure, action supervision이 fast-frequency라서 action output에 가까운 deeper layer가 빠르게 변함).
- 그런데 FSA는 caching을 위해 deeper layer가 느리게 갱신되길 요구한다.
- 따라서 interaction 순서를 뒤집어 noisy action proposal은 deep feature와, refined output은 shallow feature와 만나게 하여, high-frequency dynamics를 shallow로 이전 → deep을 stable·cacheable하게 만들었다.
- Training에서는 모든 timestep과 layer를 병렬 계산한 뒤 feature를 주기별로 복사하는 Frequency Feature Replacement로 inference-time caching을 모사하고, inference에서는
[1,2,4,8,16]간격으로 VLM과 action expert의 hidden state를 cache/reuse한다. - LIBERO에서 평균 성공률 98.3%, 평균 latency 17.8 ms를 기록했고, FR3 real-robot의 memory-sensitive Exchange Boxes task에서 VLA-Adapter의 15%보다 높은 50% 성공률을 보였다.
Further Analysis
- “Frequency”의 의미
- 여기서 frequency는 Fourier-domain frequency나 neural oscillation을 직접 모델링한다는 뜻이 아니다. 각 Transformer layer group을 얼마나 자주 recompute할 것인가를 의미하는 execution cadence이다.
- “Unified”의 의미
- VLM과 action expert가 물리적으로 완전히 하나의 Transformer가 된 것은 아니다. 여전히 VLM과 action expert가 존재하며, “unified”는 module 단위로 slow VLM → fast policy를 hard-link하는 대신 모델 깊이 전체에 multi-frequency pathway를 분산시켰다는 의미에 가깝다.
- 실제 novelty의 핵심
- 단순 cache가 아니라, cache가 가능한 representation을 만들기 위해 training distribution 자체를 frequency-aware하게 변경했다는 점이 중요하다.
- Implicit memory의 정확한 의미
- 별도의 recurrent memory, memory token, retrieval buffer를 학습한 것이 아니다. 이전 timestep의 low-frequency hidden state를 계속 유지하므로 과거 context가 남는다는 의미이다.
- 실험에서 발견한 사실
- FSA만 적용하면 성공률이 95.8%에서 70.3%로 붕괴한다. LVI까지 적용해도 94.3%이며, 최종 98.3%는 MLS를 추가해야 나온다. 따라서 성능 보존에는 caching 자체보다 representation alignment와 deep supervision이 핵심이다.
- Inference
- Table 2의 449.4 Hz는
1 / 17.8 ms = 56.2 Hz와 일치하지 않고,8 actions / 17.8 ms = 449.4 actions/s와 정확히 일치한다. 따라서 이는 policy query frequency가 아니라 chunk 내 action-step throughput으로 해석해야 한다.
- Table 2의 449.4 Hz는