



Qwen-RobotManip Technical Report: Alignment Unlocks Scale for Robotic Manipulation Foundation Models
Qwen-VL 기반 VLA에 canonical state/action alignment, camera-frame EEF action, in-context policy adaptation, Human-to-Robot synthesis를 결합해 heterogeneous robot manipulation data를 coherent하게 scale하고 OOD task/scene·instruction·cross-embodiment generalization을 끌어올린 robot manipulation foundation model
Overview Figure
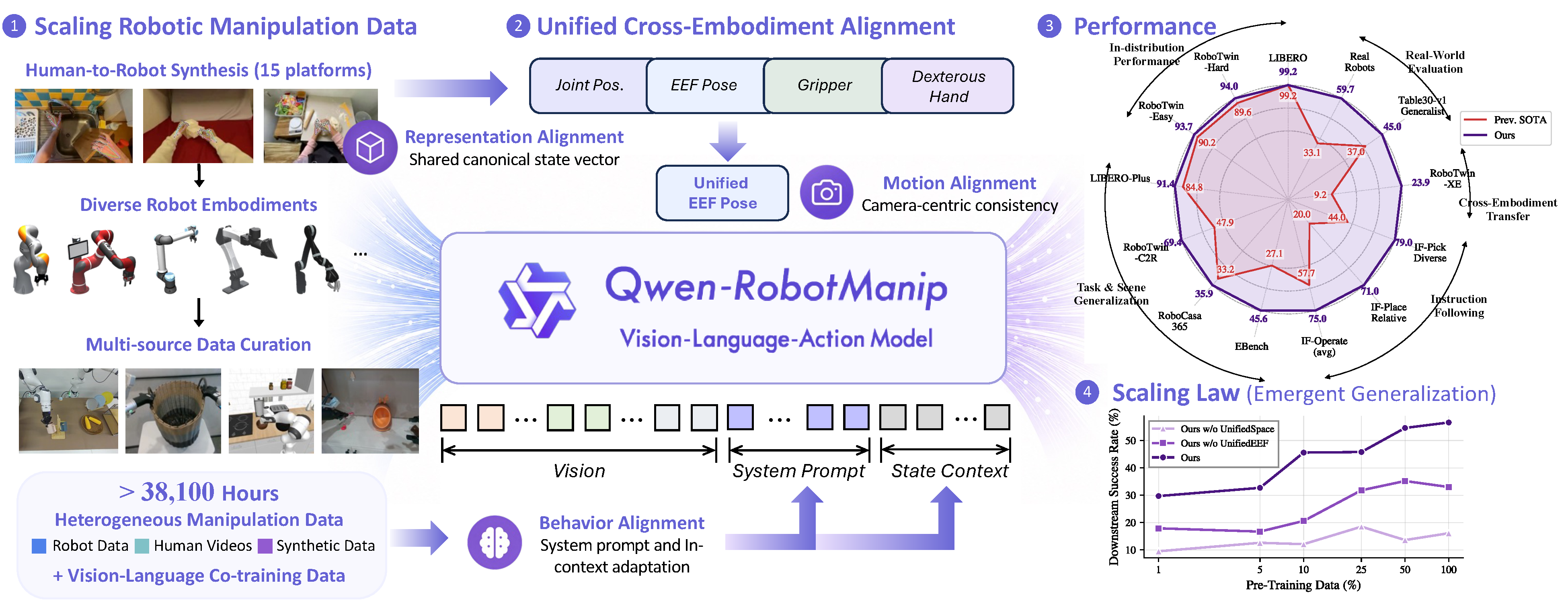

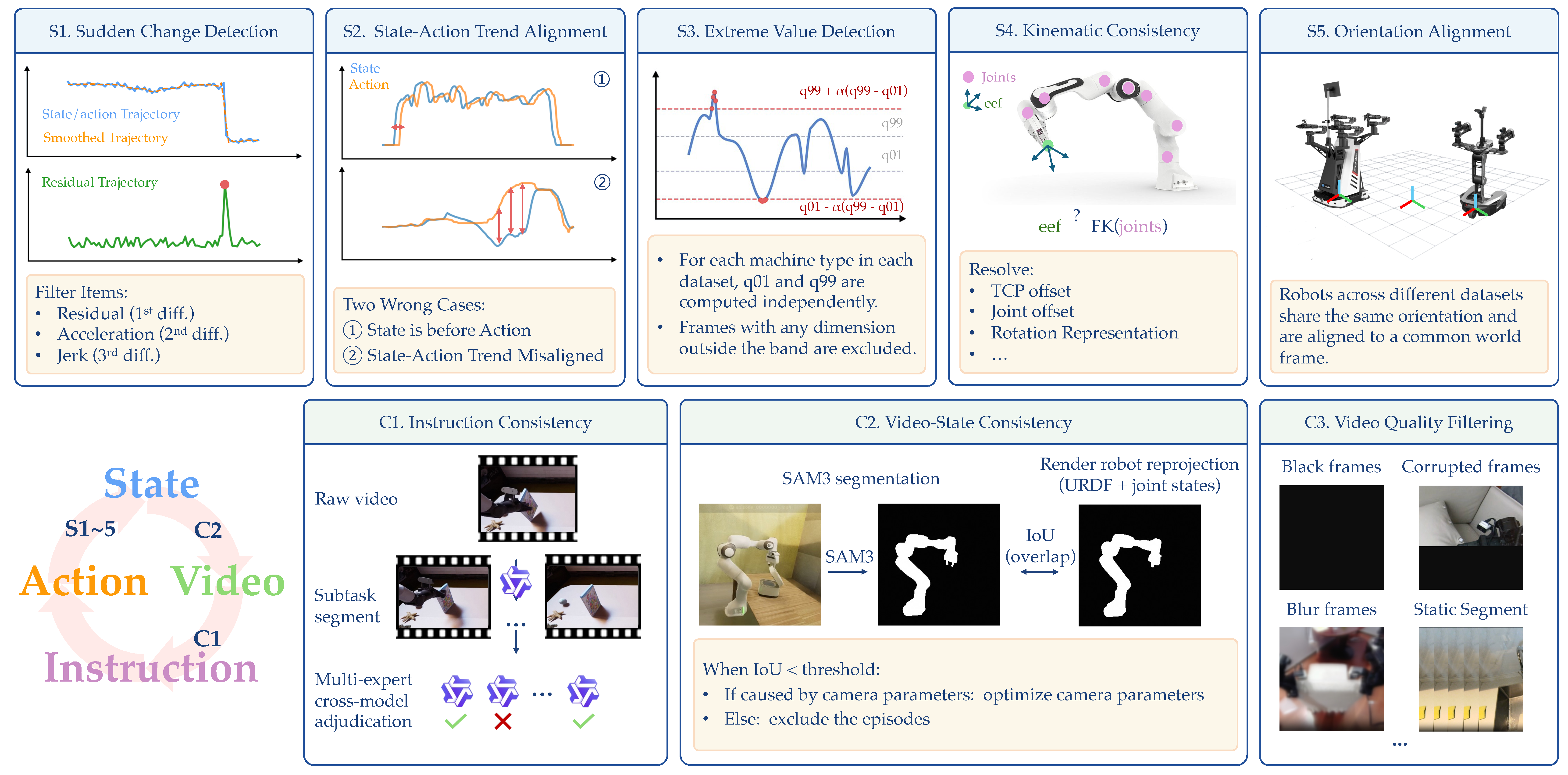
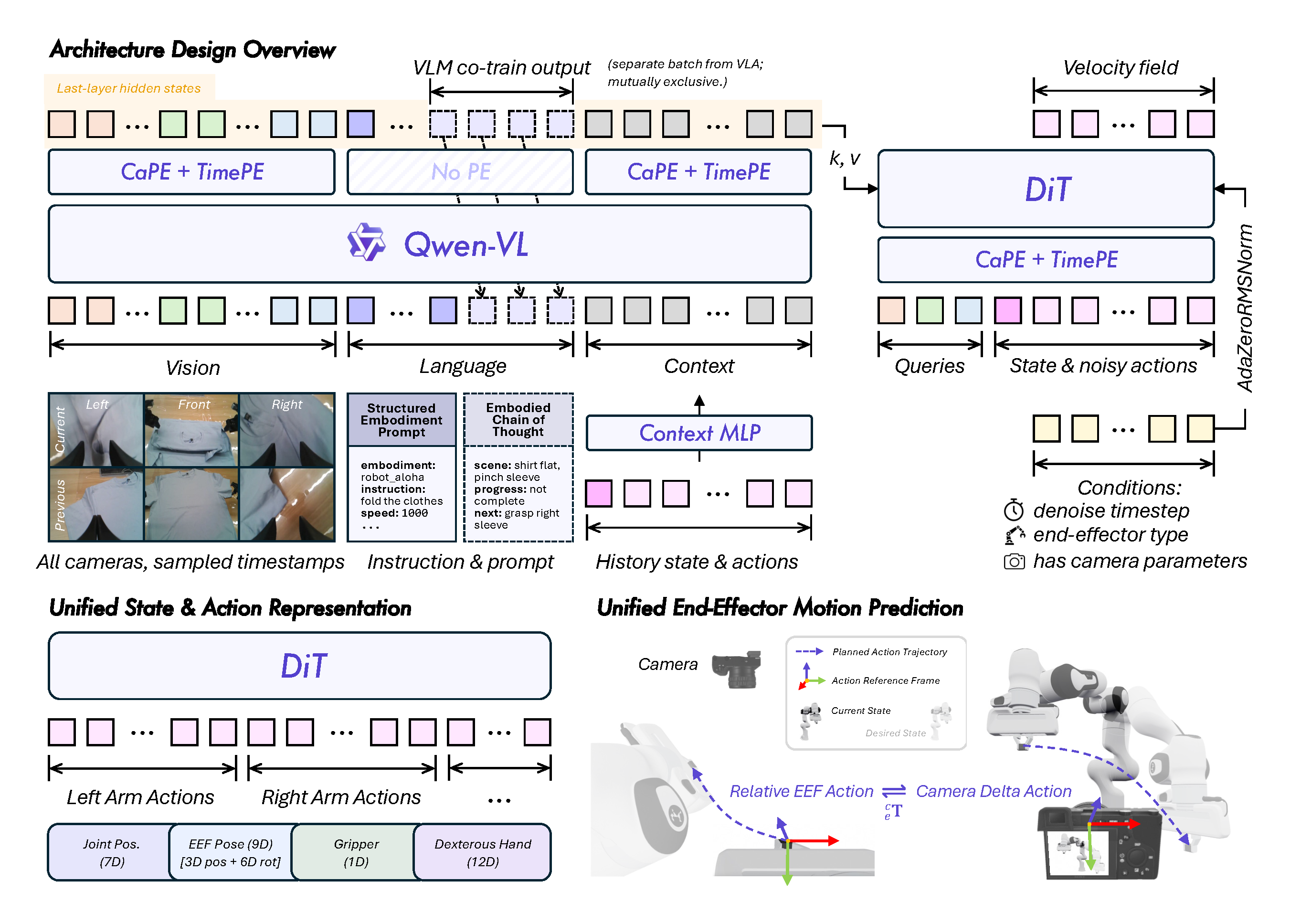
Summary
- 기존 VLA 모델들은 LIBERO, RoboTwin 같은 standard in-domain benchmark에서는 높은 점수를 보이지만, 다른 embodiment, 다른 camera, 다른 scene, 다른 instruction으로 넘어가면 generalization이 급격히 약해지는 문제가 있다.
- 이 논문은 로봇 데이터가 embodiment, coordinate frame, action space, teleoperation setup별로 서로 달라서 단순히 데이터를 많이 섞는 것만으로는 scaling law가 생기지 않는다는 문제를 다룬다.
- 핵심 아이디어는 alignment first, then scale로, canonical 80D state-action vector, per-dimension binary mask, camera-frame delta EEF pose, structured embodiment prompt, in-context policy adaptation을 통해 여러 robot morphology의 데이터를 하나의 일관된 물리 표현으로 맞춘 뒤 대규모 pretraining을 수행하는 것이다.
- 모델은 Qwen3.5-4B / Qwen-VL 계열 vision-language backbone과 flow-matching DiT action expert로 구성되며, manipulation data와 vision-language data를 dual-stream으로 co-training하고, downstream domain에서는 SFT 또는 mixed post-training으로 adaptation한다.
- 약 38,100시간 manipulation corpus와 OOD benchmark suite에서 RT-C2R Hard 69.4% vs. $\pi_{0.5}$ 47.9%, RoboTwin-IF 72.2% vs. 49.6%, RoboTwin-XE EEF 23.9% vs. 7.5%처럼 OOD robustness, instruction following, cross-embodiment transfer를 크게 끌어올렸지만, Human-to-Robot 합성 artifact, simulation 중심 OOD 평가, fixed action chunk와 latency 한계는 남아 있다.