



WAM-RL: World-Action Model Reinforcement Learning with Reconstruction Rewards and Online Video SFT
pretrained WAM에서 actor만 RL fine-tuning하지 않고, successful online rollout으로 world model을 KL-regularized video SFT하며, actor는 imagined future와 executed future의 reconstruction consistency reward로 RL update하는 WAM post-training framework
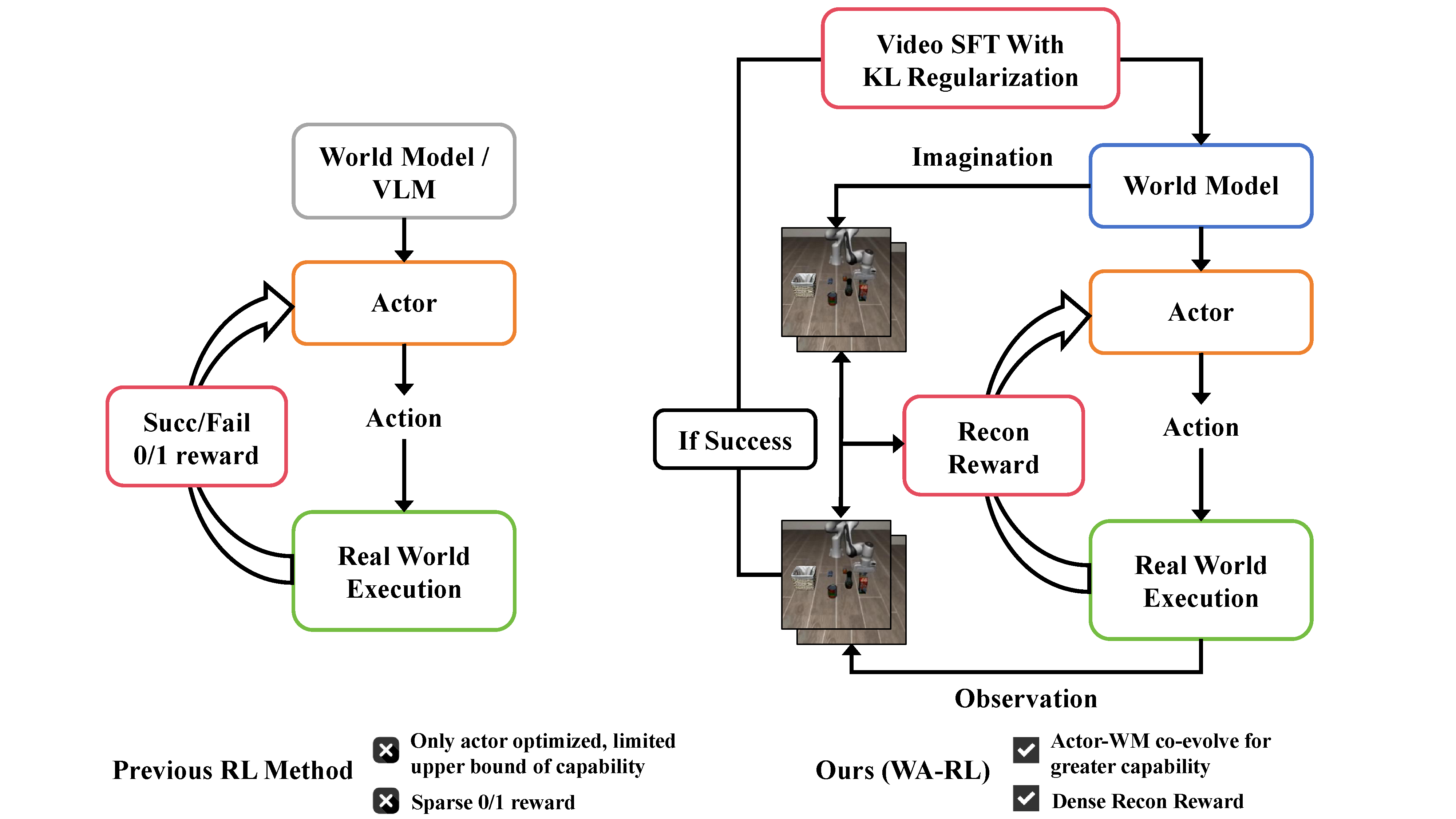
Overview Figure
Summary
- 기존 WAM은 future observation과 action을 함께 모델링해 long-horizon decision making에 유리하지만, 대부분 expert trajectory 기반 supervised learning에 의존해 demonstration distribution 밖의 fine-grained skill을 배우거나 interaction으로 지속 개선하기 어렵다.
- 이 논문은 WAM에 RL을 넣을 때 actor만 update하면 world model latent space에 묶인 actor가 accumulated prediction errors over long horizons를 고치지 못한다는 문제를 다룬다.
- 핵심 아이디어는 WAM의 주된 capability가 world model에서 나오고 actor는 latent prediction을 executable action으로 번역하는 translator에 가깝기 때문에, world model과 actor를 함께 co-evolve시켜야 한다는 것이다.
- world model을 successful online rollout으로 video self-supervised fine-tuning(SFT)하되 KL regularization으로 pretrained latent geometry를 보존하고, actor는 imagined future와 실제 실행 결과 사이의 similarity를 reconstruction-based dense reward로 삼아 policy gradient로 학습한다.
- 실험에서는 LIBERO-Object에서 Base 68%, actor-only $\pi_{\text{RL}}$ 78%, WAM-RL 82%, RLBench Water Plants에서 Base 19%, $\pi_{\text{RL}}$ 18%, WAM-RL 22%를 달성하며, 특히 video SFT가 failed grasp 이후 recovery behavior를 예측하게 만든다고 주장한다.