



Object-Centric Residual RL for Zero-Shot Sim-to-Real VLA Enhancement
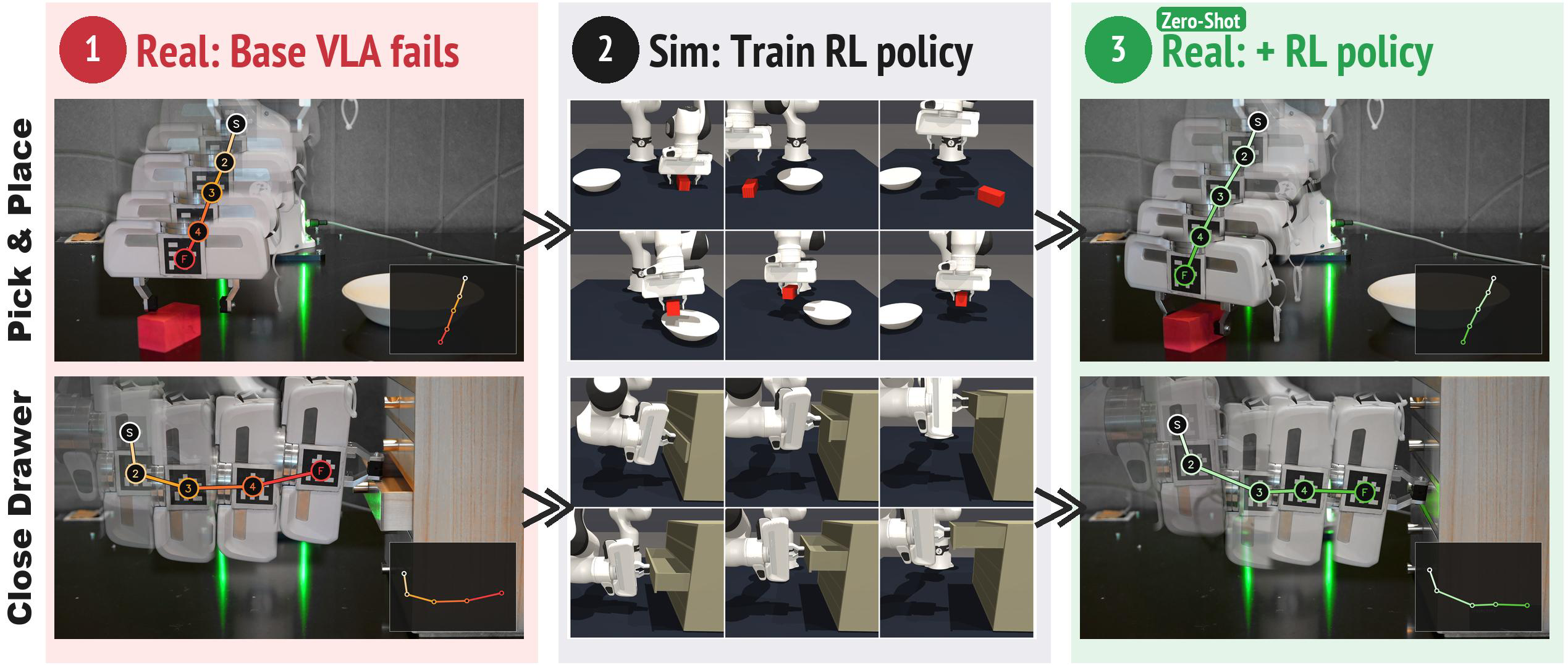
Real-robot demonstrations로 fine-tune한 VLA를 고정한 뒤, task-relevant object 6-DoF pose·proprioception·현재 base VLA action만 입력받는 lightweight residual RL policy를 simulation에서 학습하고 real robot에 adaptation 없이 결합해, FR3 5-task 평균 real success rate를 42%에서 76%로 높인 sim-to-real VLA enhancement framework
Overview Figure
Summary
- 기존 imitation-learning 기반 VLA는 action execution error가 누적되면 demonstration 분포 밖의 상태로 진입하지만, diffusion/flow 기반 대형 VLA에는 standard policy-gradient RL을 end-to-end로 직접 적용하기 어렵고, 기존 residual RL도 privileged-state distillation, visual domain gap, real-world RL 비용이라는 문제를 가진다.
- 이 논문은 simulation에서만 학습한 residual correction policy가 real-world VLA의 행동을 별도 adaptation 없이 개선할 수 있는가를 다룬다.
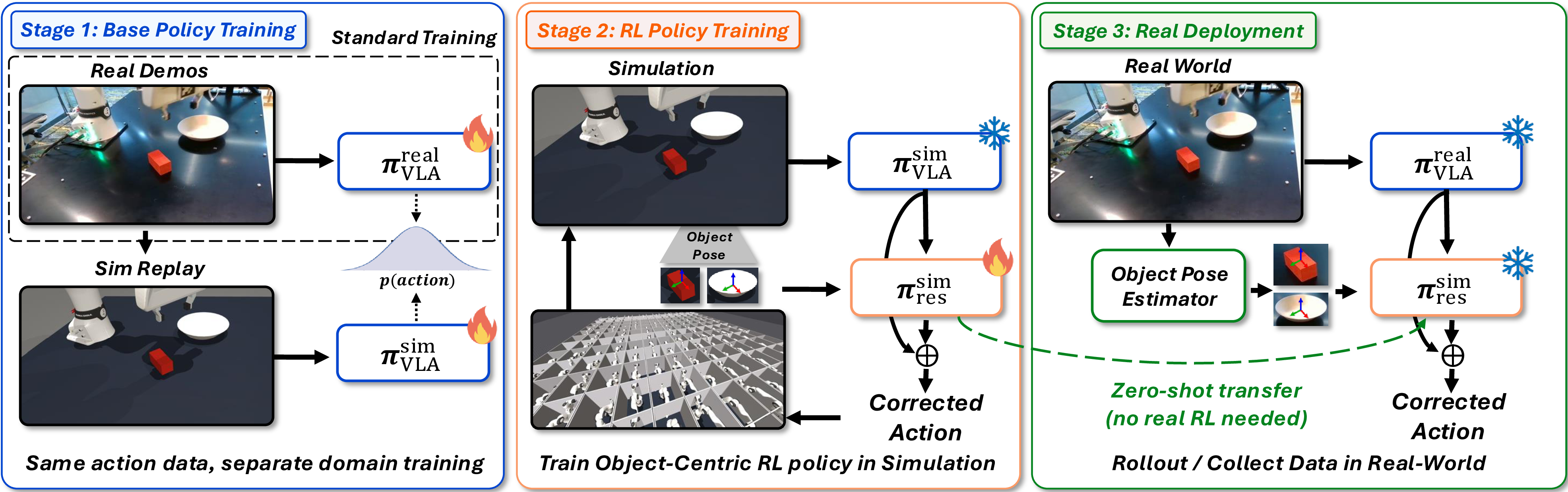
- 핵심 아이디어는 residual policy가 RGB image 대신 양쪽 domain에서 비교적 일관되게 얻을 수 있는 task-relevant object pose, proprioception, current base VLA action을 input으로 받도록 만드는 것이다.
- 동일한 teleoperation action을 simulation에서 replay해 sim/real VLA가 서로 다른 RGB domain에서도 같은 action supervision을 받도록 학습하고, frozen sim VLA 위에서 TD3 residual policy를 pose noise injection 및 pose dropout과 함께 학습한 뒤, deployment에서는 sim VLA를 frozen real VLA로 교체하고 residual policy는 추가 adaptation 없이 그대로 사용한다.
- GR00T-N1.5 기반 FR3의 다섯 manipulation task에서 sim-trained residual을 직접 결합한 policy의 평균 real success rate는 42%에서 76%로 향상되었다. 별도로, residual-corrected real rollout으로 base VLA를 다시 SFT하면 residual 없이 실행하는 standalone VLA도 추가 teleoperation 없이 42%에서 59%로 향상되었다.