



WAM4D: Fast 4D World Action Model via Spatial Register Tokens
4D geometry를 inference-time output으로 직접 만들지 않고, training-time spatial register token으로 future depth를 예측하게 만들어 geometric foundation prior를 causal video-action WAM에 distill한 뒤, deploy 시 geometry branch를 제거해 action chunk를 빠르게 생성
Overview Figure
Summary
- 기존 WAM은 future video/action을 함께 모델링하지만 대부분 2D video 또는 latent space에 머물러 manipulation에 중요한 3D spatial constraint, occluded contact geometry, free space, object extent를 충분히 반영하지 못한다.
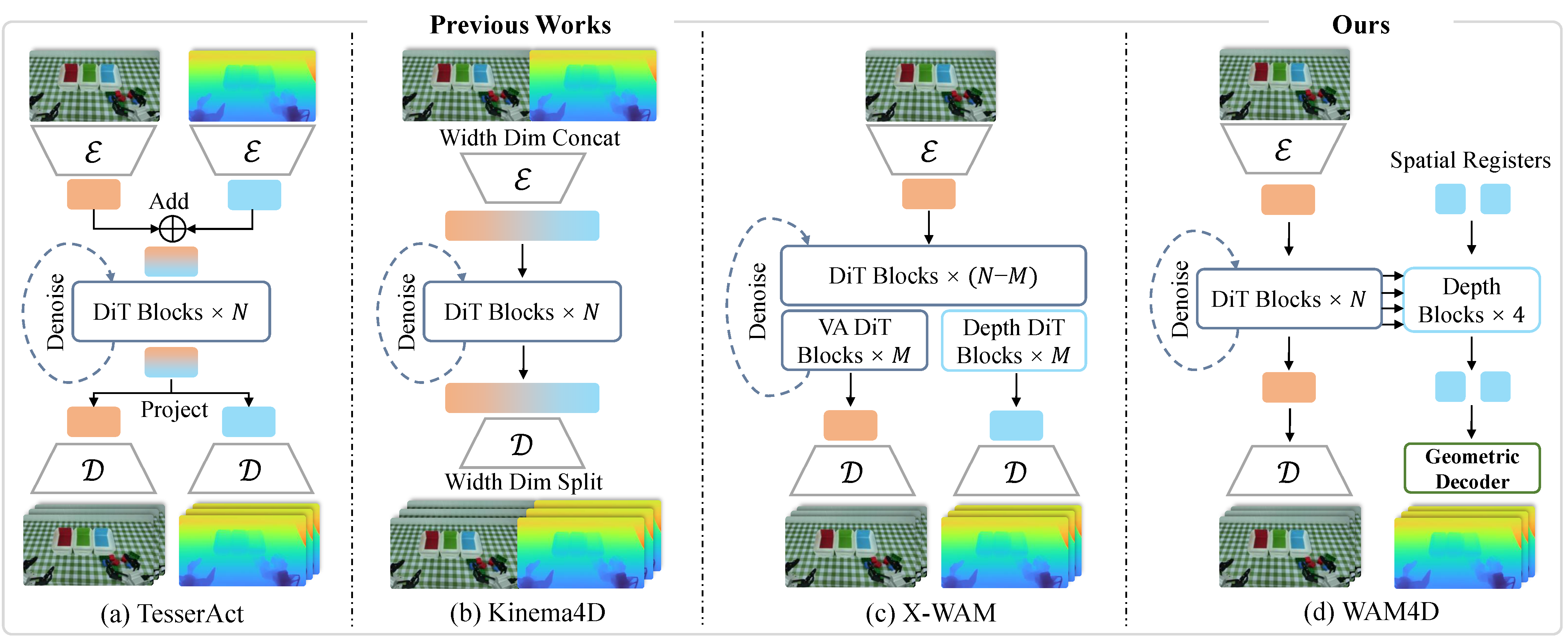
- 반대로 TesserAct, Kinema4D, X-WAM류의 4D world modeling은 dense geometry를 input/output 또는 inference target으로 다루기 때문에 action inference 시 geometric decoding 비용과 latency가 커진다.
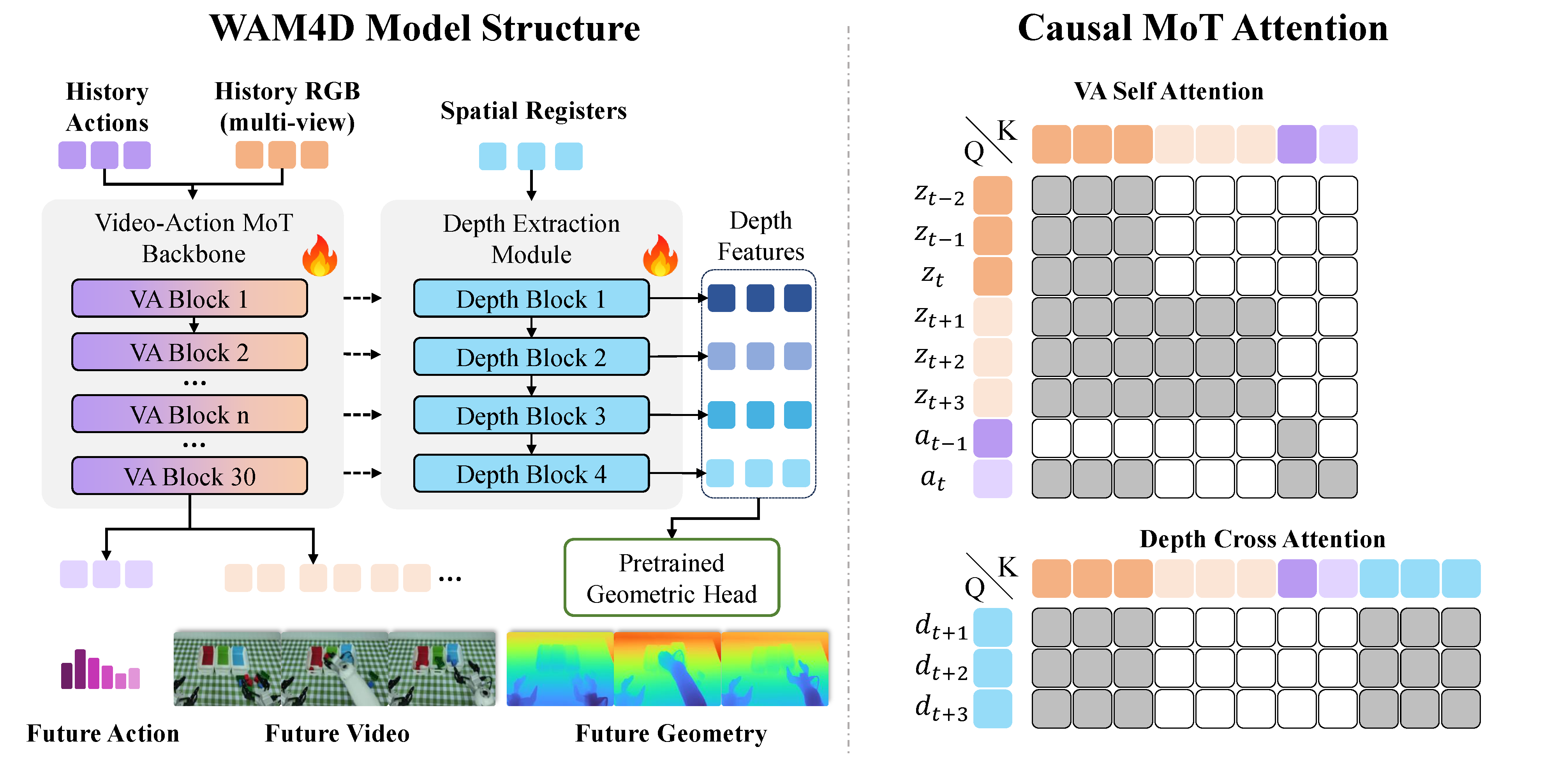
- WAM4D의 핵심 아이디어는 geometry를 deployment-time output이 아니라 training-time auxiliary readout target으로만 사용하고, learnable spatial register tokens가 history video feature에서 future depth를 읽어내도록 학습시키는 것이다.
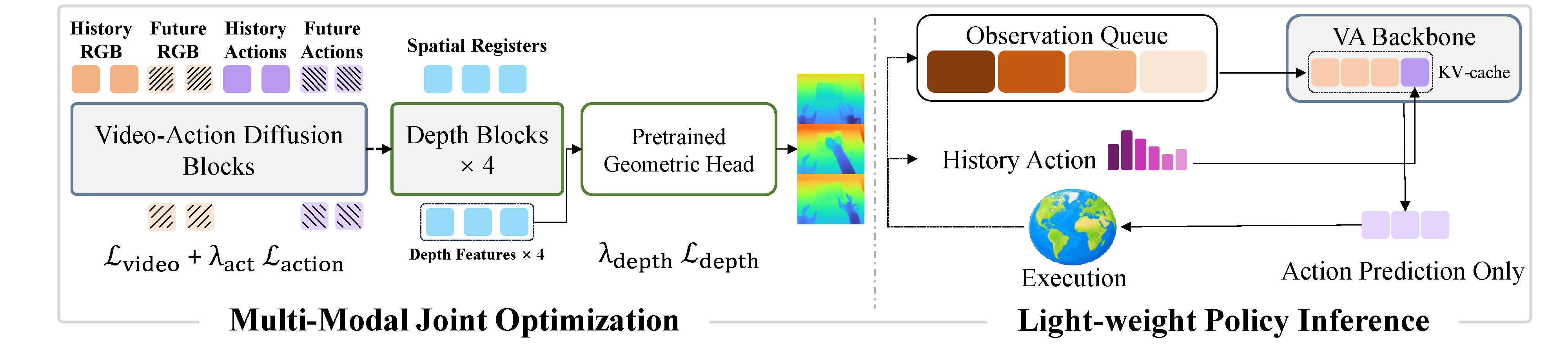
- 모델은 LingBot-VA 기반 causal video-action MoT backbone에 spatial register 기반 depth extraction blocks, pretrained Depth Anything 3 / DA3-GIANT-1.1 geometric head, causal mixture attention mask를 붙여 video/action/depth objective를 joint optimization한다.
- RoboTwin 2.0과 AstriBot S1 real-world task에서 WAM4D는 spatial consistency와 real-world sub-action success를 개선하지만, RoboTwin randomized average에서는 LingBot-VA/Fast-WAM보다 낮고, WAM 계열 자체도 VLA보다 latency가 크다는 한계가 있다.