



SPACE: Enabling Learning from Cross-Robot Data Toward Generalist Policies
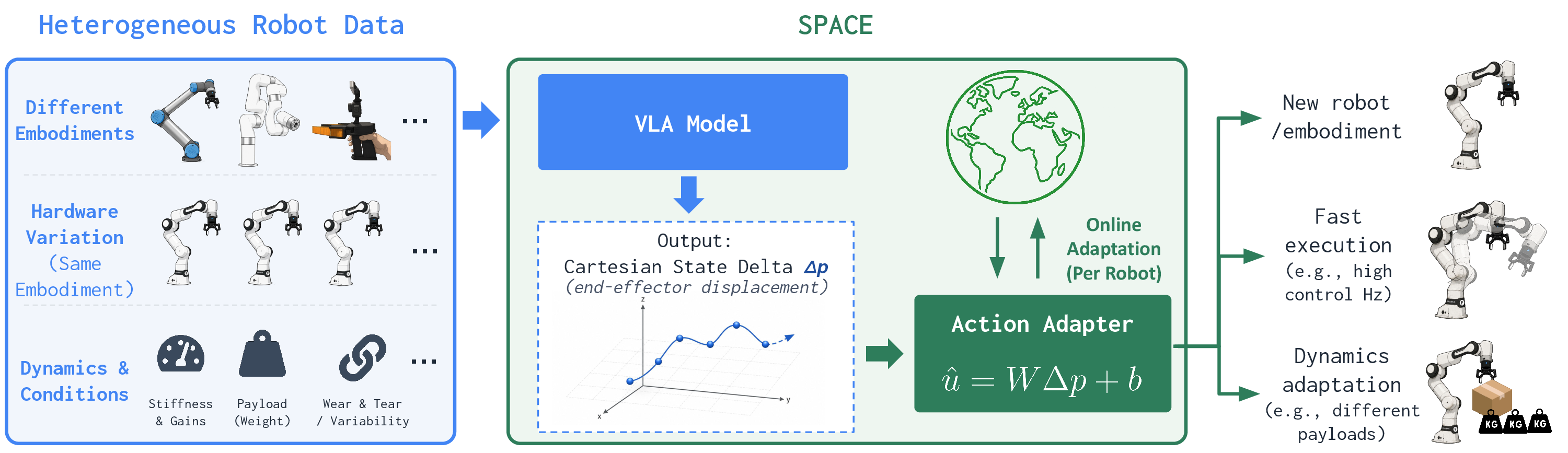
VLA가 robot-specific control command 대신 실제로 달성해야 할 6-DoF Cartesian end-effector displacement를 예측하게 하고, target robot마다 선형 Action Adapter를 offline calibration과 online LMS로 적응시켜 cross-embodiment·cross-hardware·deployment dynamics shift에 강한 execution interface를 만든다
Overview Figure
Summary
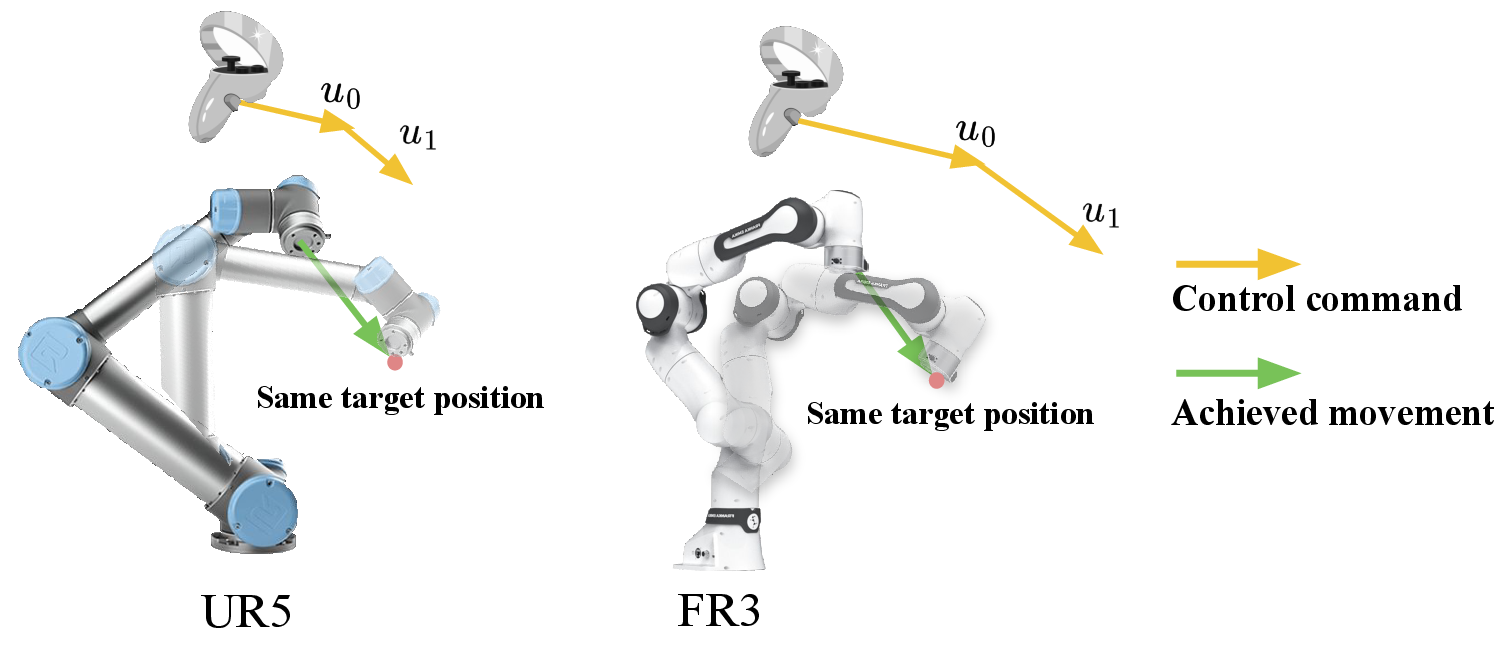
- 기존 cross-robot behavior cloning은 demonstration에 기록된 control command를 그대로 supervision으로 사용하지만, 같은 command라도 embodiment, controller, hardware unit, payload에 따라 실제 motion이 달라져 label inconsistency가 발생한다.
- 이 논문은 서로 다른 robot에서 공유 가능한 action semantics를 만들고, 그 action을 target robot의 실제 controller command로 안정적으로 변환하는 문제를 다룬다.
- 핵심 아이디어는 command가 아니라 trajectory에서 관측된 실제 end-effector displacement인 Cartesian state delta $\Delta p_t=p_{t+1}-p_t$를 policy output으로 사용하는 것이다.
- Pretrained $\pi_{0.5}$ VLA를 Cartesian state delta 예측으로 fine-tuning하고, target robot에서 약 500-step random calibration으로 linear Action Adapter를 초기화한 뒤 rollout 중 achieved motion feedback으로 LMS update를 수행한다.
- UR5→FR3, FastUMI+FR3, 서로 다른 FR3 unit, DROID multi-hardware data, control frequency·payload·controller gain shift에서 command-predicting baseline보다 큰 성공률 향상을 보였지만, 검증은 주로 FR3와 Cartesian-delta controller에 한정된다.
Further Analysis
-
핵심은 새로운 VLA architecture가 아니라 action interface의 factorization이다
\[\text{task intent: }o_t\rightarrow \Delta p_t^{\text{target}} \quad+\quad \text{robot realization: }\Delta p_t^{\text{target}}\rightarrow u_t\]- 기존 policy가 이 두 문제를 하나의 $o_t \rightarrow u_t$ mapping으로 학습했다면, SPACE는 semantic/task-level motion과 robot-specific actuation을 분리한다.
- Cartesian state delta만으로는 충분하지 않다
- 논문에서 state delta를 controller에 직접 전달한 경우 모든 cross-embodiment task에서 성공률이 0%였다. 실제 controller가 delta command를 완벽하게 추종하지 않기 때문에 Action Adapter가 필수적이다.
- Action Adapter는 full dynamics model보다 adaptive inverse actuation model에 가깝다
- Observation이나 joint state를 입력받아 미래 상태를 예측하는 것이 아니라, “이 robot에서 이 displacement를 만들기 위해 command를 얼마나 증폭·보정해야 하는가”를 온라인으로 추정한다.
- ‘Universal action’은 조건부 주장이다
- SPACE가 통일하는 것은 control command가 아니라 motion representation(achieved Cartesian end-effector displacement)이고, control command 자체는 per-robot Action Adapter로 분리해 처리한다.
- 반면 coordinate frame, sampling interval, gripper semantics, reachability, morphology, observation은 통일하지 않는다.
- Appendix의 action-chunk 결과는 중요한 단서다
- UMI 실험에서 16개 action 전체를 open-loop로 실행하면 SPACE와 baseline 모두 성공률이 5%였고, 첫 4개만 실행한 뒤 replanning하는 구성을 사용했다.
- 즉, SPACE는 controller mismatch를 해결하지만 action-chunk compounding error까지 해결하지는 않는다.
- Force-awareness의 부재
- 같은 displacement도 force가 다를 수 있어 contact-rich task에서 Cartesian state delta는 부족하다.